








 超级会员免费看
超级会员免费看


文章目录
整体代码结构:
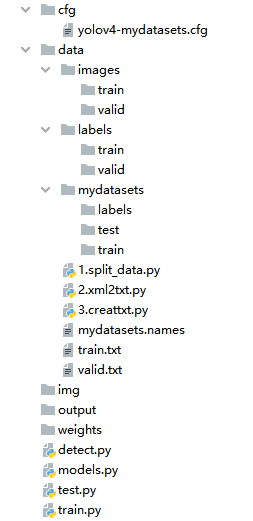
一、cfg文件修改
创建yolov4-mydatasets.cfg,因为我用了yolov4.cfg训练太吃显存,2080TI的机子batchsize设置为2也会爆显存。其主要原因是mish函数太占显存了。
修改的地方:
将mish函数替代为relu函数,大大降低显存使用!
另外filters设置为:(class数目 + 4 +1) × 3 = 45(我这里10个类别)分别对应三个detect header
classes=10 修改为类别数目,我这里是10(所以这里和filters一共修改6处)
其他的超参数可以适当修改。
[convolutional]
size=1
stride=1
pad=1
filters
 订阅专栏 解锁全文
订阅专栏 解锁全文

















 5139
5139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











