







↑↑↑关注后"星标"Datawhale
每日干货 & 每月组队学习,不错过
Datawhale干货
作者:宋志龙、王威,啄云智能GOAT战队
大家好,我们是来自浙江啄云智能科技有限公司的GOAT算法团队,团队多年来专注于X光安检领域算法研究。今天给大家分享的是我们团队在2021科大讯飞--X光安检图像识别挑战赛中所做的一些工作,在讯飞2021年的赛事中,这个比赛可以说是竞争最激烈了,前后历时三个多月,我们团队进行了大量实验,最终拿到了复赛第一、决赛第一的成绩。
下面我将从赛题背景、赛题内容分析、解决方案和总结这四个方面进行介绍,欢迎大家在评论区进行交流。
一、赛题背景
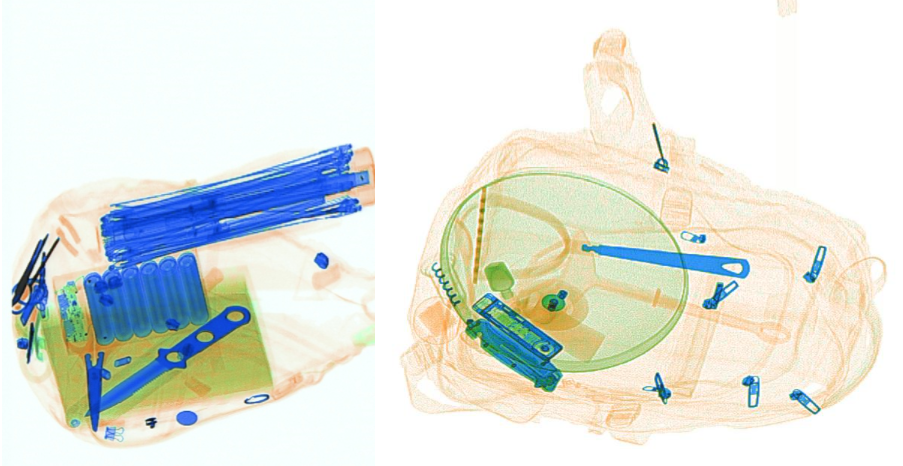
X光安检机是目前我国使用最广泛的安检技术手段,广泛应用于城市轨交、铁路、机场、重点场馆、物流寄递等场景。使用人工智能技术,辅助一线安检员进行X光安检判图,可以有效降低因为人员疲劳或注意力不集中带来的漏报等问题。但在实际场景中,因物品的多样性、成像角度、遮挡等问题,为算法的开发带来了一定的挑战。
赛题链接:
http://challenge.xfyun.cn/topic/info?type=Xray-2021
二、赛题内容及分析
1. 赛题内容
赛题数据组成
初赛:
1)带标注的训练数据,即待识别物品在包裹中的X光图像及其标注文件;
2)不带标注的测试数据;
复赛:
1)无标注训练数据即包裹X光图像(其中有的包裹包含待识别物品);
2)部分待识别物品X光图像(无背景);
目标类别:
刀、剪刀、尖锐工具、甩棍、小玻璃瓶、电棍、塑料饮料瓶、带喷嘴塑料瓶、电子设备、电池、公章、伞, 共12类。
模型评价指标
wAP50,即各个类别的AP50按照权重进行加权的结果。
其中各类别权重为:
刀1、剪刀1、尖锐工具1、甩棍1、小玻璃瓶1、电棍1、塑料饮料瓶0.7、带喷嘴塑料瓶0.7、电子设备0.7、电池0.7、公章0.7、伞0.7。
模型大小
600M以内
2. 赛题分析
赛题数据中,提供了大量的无标注数据,利用好这些无标注数据进行半监督学习是关键。
数据可视化发现数据背景较复杂且差异较大,设计合适的数据增强方法是关键
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6863
6863











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









