






关键字: Monte Carlo方法, Monte Carlo 整合, 随机变量, 概率,统计,期望值,variance(方差),标准差(standard deviation), 概率分布,概率密度模型(probability density function), 累积分布函数(cumulative distribution function), 转置采样,估值。
原始的我们并不想这个教程太长,有太多关于概率和统计的信息,但是实际上,如果你想掌握Monte Carlo方法的话,你需要学习很多的概率和统计的知识。
在这篇文章中,我们会给一个Monte Carlo的大致介绍,让你知道它是什么,它们是怎么工作的。这是一个快速的介绍,为那些没有太多的时间或者不再想深入的读者准备的。但是如果你感兴趣的话可以学习接下来的章节,那些章节可以让你更深入。
这篇文章不仅仅是一个数学工具的介绍,这些方法也会在下一章(Monte Carlo方法中实现)。
1. Monte Carlo前言
就像你会发现其它的很多名词一样,Monte Carlo就像是一个神奇的名字。和其它一些用在CG上的数学工具相比,比如spherical harmonics(立体调和)很难,至少和Monte Carlo方法相比它们很难。这个方法很好因为它解决了很多复杂的问题。Monte Carlo 积分或者估值(用积分可能更好),是一种比较古老的方法(它在18世纪早期完成),直到20世纪40年代中期才命名为这个名字。Monte Carlo要和发明Casinos的Monaco的名字区分。当我们介绍Monte Carlo方法的时候,在统计学上有很多的应用,他是一个很好的估计你赢得一个比赛的概率的工具,这种概率往往被看做是随机的。这个名字也很好地反应了这个方法要做什么。这个方法的发明,是一些注明的数学家(费米,Ularm, 冯。卡门, Metropolis和其它的)对研究原子弹的爆炸有重要意义。同时它们被应用于现代科学中,von Neumann建立了第一台计算机的一部分。没有计算机的帮助,Monte Carlo积分是非常可怕的,因为它需要数以亿计的运算,它正好是计算机擅长的。现在,我们来复习一些这个方法名字的起源,让我们来解释一下什么是Monte Carlo,很不幸的是,就像之前简要的说明那样,Monte Carlo方法是建立在很多统计和概率论的基础上形成的。我们需要复习那些概念在你深入理解Monte Carlo方法之前。

2. Monte Carlo方法的快速介绍
什么是Monte Carlo ?Monte Carlo方法的概念是简单且健壮的。但是,就像你不久后就会看到,它需要大量的计算,它的出现很大程度上是因为计算机技术的兴起。生活上的很多东西都是很难估计的,特别是涉及到大量的时候。比如,很难估算下图中的1kg的东西里面含有多少个豆子,你可能通过手动去数它们,一个接一个地,但是会花很多的时间。

计算一个国家的成年人的平均身高,需要计算每个人的身高,把这些身高加起来然后除以总数。再次说明,这种方法会花费很多的时间。我们可以提取人口的一部分样本,去计算它的平均身高。它似乎不会给你整个人口的准确的平均身高,但是这个方法会给你一个大概的数字。我们用精度去换速度。统计学也是基于这个原则。同时很有趣的是,往往估计的数字和整体人口的平均值基本上是一样的。这是因为概率,在绝大部分的例子中,这个数字会是不相同的。一个问题我们需要问自己,就是有什么不同?实际上,随着样本数据的增加,这个估计值会和精确值会越来越接近。换句话说,这个估计值和真实值的差距会随着样本的增加逐渐减小。直观上来说,这个概念很容易掌握,但是我们会在下一章中看到,它应该被公式化和证明。记住,公平来讲,样本的选择应该是随机的有相同的概率。
记住,一个人的身高是一个随机值,你它可以使用随机值表示。因此,当你获取一个样本的时候,需要随机地提取其中的元素,测量它们的身高估计平均值。你每个样本的都有不同的值。如果你不能预测它们加起来的和是多少,因为这个数字是随机的。
对于一个数学家来说,人口的平均身高被叫做随机变量(random variable),因为身高的组成是随机的。我们可以用大写字母表示随机变量,通常合格字母是X.
在统计学上,组成这个人口的元素我们使用小写字码x表示,比如如果我们写成x2,这会表示人口中的第二个元素。它们的所有的x可以看做是样本的随机输出。如果我们我们可以使用下面的数据公式来估计人口的平均身高:

就像你看到的那样,这个近似的平均值X(一个国家成年人的身高),和从这个国家选择n个成年人计算平均身高是相等的,这也是我们的Monte Carlo approximation. 它会估计一个很大的样本的属性值,会从中抽取N个值来计算它的属性值。你也可以说Monte Carlo估值可以是一种使用样本估计事物的方法。我们将在下一篇学习到,我们所估计的值在数学上叫做期望。我们使用M代替整个样本,可以得到下面的公式:
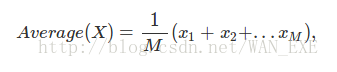
这里的,x1, x2, xm代表这整个成年人口中每个人的身高。在统计上,随机变量X的平均值,我们叫做期望,写成E(X).
总结来说,Monte Carlo估值是一个使用样本估计期望值的方法,可以用下面的数学定义表示:

上面的约等号表示左边的计算值E(X)只是一个近似的值。
如果你对理解这个Monte Carlo方法背后的东西不感兴趣,那么这个就是你所有想要知道的。但是为了完成这个介绍,让我们解释它能用在什么地方。很明显有时候是很难计算E(x)的值的,这也意味着你无法用一种有效的方式计算E(X)的值,特别是提到计算一个国家的成年人平均身高的时候。MC方法提供了一个很简单迅速的估值期望。它不会 给你准确的数字,但是它可以很接近。
(3)Monte Carlo, Biased and Unbiased Ray Tracing(偏和非偏光线追踪)
为了总结这个快速的介绍,我们意识到你已经听说过Monte Carlo 光纤追踪,以及Biased 和Unbiased ray tracing,同时希望看到这篇文章能找到这些名词意味着什么的答案。让我们来快速地理解它们,我们建议你一章接一章有序地阅读接下来的教程,来得到这些更深入的答案。
想象一下你要使用一个数码相机拍照,如果你将你的图片的表面分成方格的形式(像素),记住每个像素可以看做是很小的但是它们可以看着是连续地反射照在上面的光。这些光最终会变换成颜色(我们会在后面介绍到这个过程),如果你看这些像素值,你可以注意到这些像素只是一个物体而已,物体表面上的颜色也会根据像素的表面不同而产生变化。我们可以用下图展示
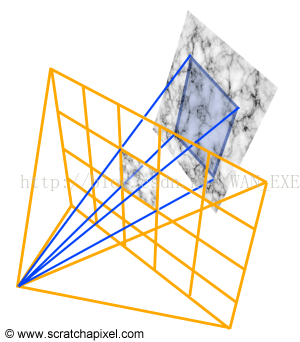
我们需要计算的是计算通过这个像素的表面所反射的光线,这是一个很难的问题,传统意义上来说我们很难通过积分的手段计算通过那个像素反射的光线值。我们可以通过数学思想写出来,这里并没有解答这个公式的方法。
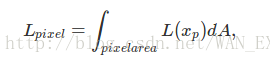
这里的L表示Radiance(辐射),你可以把这个公式理解成等式左边的L,也表示颜色,通过对右边的光线照射在这个像素上的面积通过积分得到。像我们刚才所说的,这个问题没有可分析的方法,我们需要使用数值估值来计算。
再次说明,计算它的规则很简单,它是这个积分的估值,通过在这个像素区域采集几个位置。换句话说,我们使用Monte Carlo approximation.我们所需要做得,就是在这个像素区域选择几个样本位置然后计算它们颜色的平均值。现在的问题是我们怎么找到这些样本?当然是使用光线追踪。光线会从我们的眼睛的地方开始,可以随机地穿过像素上的区域,如下图所示:

那么这个样本的颜色就是我们想要得到的像素的颜色,有下面的公式:

这里的L(xn)表示样本颜色,通常来说,这只是一个估值。这个方法叫做Monte Carlo积分(尽管它和Monte Carlo近似很像,它被用于找到一个积分的近似值)。对Monte Carlo积分的正式的定义会在下一篇中介绍,这里只是快速地和非正式的介绍概念。
如果你不能很好地理解这个问题,让我们想象一下一个16 x 16的矩阵颜色,如下图所示
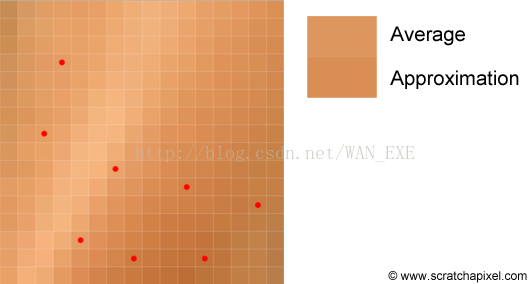
这个问题会变得简单,因为我们只有256个不同的颜色,找到每个像素的颜色值是容易的。但是如果这个方格无限地大,那么这种方法就不奏效了,我们需要找到这个问题的近似值,我们可以找这个例子中的8个样本(我们只选择8个,表示这个例子中的N值),读取这些方格里面的颜色值,然后把它们加起来除以8。你可以从上图中理解这些概念,你可以看到估值和平均值很接近,这是Monte Carlo的缺陷,它只给我们近似估值。另外一个缺陷是你会得到不同的估值,如果你使用随机方法获取8个样本的位置,因为它们每次都会改变。比如下面的这张图使用了16中不同位置的估值

好消息是,你可以通过增加样本的数量来减少这种误差。坏消息是,如果你想将误差减小一半,你需要两倍的样本值。这也是Monte Carlo方法比较慢的原因,另一种更准确的描述方法是说它们的计算值慢。会在下面的教程中详细研究它们。下面这张图,表示了选择8, 16, 32, 64, 128, 256个样本来估值的16个不同的位置。

你可以看到随着样本值的增加,这个期望的估值误差在减小。这个在渲染的不同被叫做噪点。它是因为你使用的估值方法不同所引起的,技术上来说这个正确的名字叫做variance。在低样本的情况下你会得到更多的噪点,或者可以说你可以增加样本的数量减少噪点。
记住所获取的变量的变化和图形也是有关系的,使用下面这张图,那么这个获取的近似值会更明显。

这是怎么发生的?当你看到复杂表面的多个物体时,通常来说,你需要避免从一个很大图像中去获取一个很小的点,因为这会需要更多的样本来减少噪点。我们可以使用下面这个程序进行测试。
#include <fstream>
#include <cstdlib>
#include <cstdio>
int main(int argc, char **argv)
{
std::ifstream ifs;
ifs.open("./tex.pbm");
std::string header;
uint32_t w, h, l;
ifs >> header;
ifs >> w >> h >> l;
ifs.ignore();
unsigned char *pixels = new unsigned char[w * h * 3];
ifs.read((char*)pixels, w * h * 3);
// sample
int nsamples = 8;
srand48(13);
float avgr = 0, avgg = 0, avgb = 0;
float sumr = 0, sumg = 0, sumb = 0;
for (int n = 0; n < nsamples; ++ n) {
float x = drand48() * w;
float y = drand48() * h;
int i = ((int)(y) * w + (int)(x)) * 3;
sumr += pixels[i];
sumg += pixels[i + 1];
sumb += pixels[i + 2];
}
sumr /= nsamples;
sumg /= nsamples;
sumb /= nsamples;
for (int y = 0; y < h; ++y) {
for (int x = 0; x < w; ++x) {
int i = (y * w + x) * 3;
avgr += pixels[i];
avgg += pixels[i + 1];
avgb += pixels[i + 2];
}
}
avgr /= w * h;
avgg /= w * h;
avgb /= w * h;
printf("Average %0.2f %0.2f %0.2f, Approximation %0.2f %0.2f %0.2f\n", avgr, avgg, avgb, sumr, sumg, sumb);
delete [] pixels;
return 0;
} 国内的搜索真垃圾,连个pbm都下载不到,我都怀疑有这种文件格式没有。
因为我们使用光线追踪去估计样本,那么这个方法叫做Monte Carlo ray tracing.(也叫做Stochastic Ray Tracing, 这个stochastic和random是雅漾的意思。
现在我们来讨论biased 和unbiased,在统计学上,我们计算E(X)的期望值的时候叫做estimator.使用的是下面这个等式:
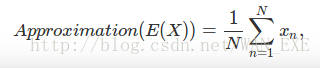
unbiased所有表达的意思是当样本的数量变大和或者趋向于无穷的时候,那么这个时候的期望值和真正的期望值相减趋向于0.
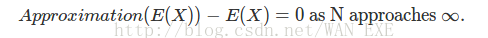
这真是Monte Carlo所要表达的。
Monte Carlo是一个unbiased estimator.
但是当估值和期望值一直是某个常数的时候,我们就说这个estimator是biased.
现在翻译太糟糕了,有些东西自己都没有看懂,先暂停一段时间了。














 5560
5560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









