






这篇文章之前需要先了解self-attention
Transformer是什么?Transformer是一个Sequence-to-sequence (Seq2seq)的模型。
1、什么是Seq2seq模型
Seq2seq是什么?输入时一个序列(向量序列),输出是一个序列(向量序列)。输入序列和输出序列的长度是可变的,而输出序列的长度由模型自己决定。Seq2Seq模型经常在输出的长度不确定时采用。
比如下图中的语音识别、机器翻译、语音翻译(有的语言没有文字)。
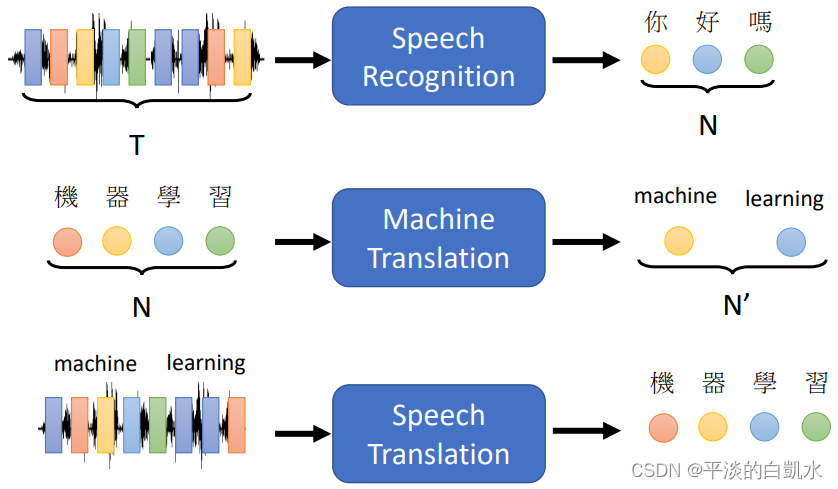
在YouTube上1500小时的闽南语(中文字幕)视频,作为数据直接进行训练,就可以的到一个不错的语音翻译工具,输入闽南语,输出中文。
再比如说:Text-to-Speech Synthesis (TTS 语音合成)、Chatbot、Syntactic Parsing、Multi-label Classification、Object Detection。
2、Seq2seq模型的组成
一般的Seq2seq模型里面会分成两块。一块是encoder,一块是decoder
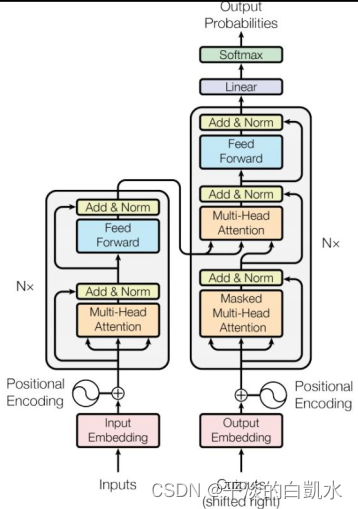
Transformer整体结构如下图所示,左边为encoder,右边为decoder。Encoder 和 Decoder 都包含N个 block。
3、Transformer的encoder模块
Encoder做的事情就是输入一排向量,输出一排向量。达到这个目的很多模型都能做到,比如RNN,CNN。Transformer中用到的是self-attention,如下图。
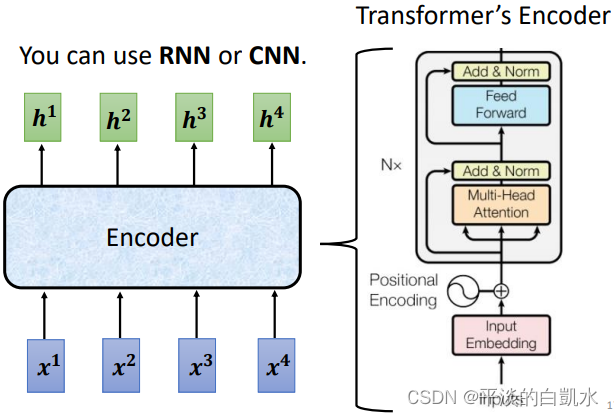
Transformer的encoder模块由很多的block组成。每个block都是输入一排向量,输出一排向量,如下图左边所示。

每个block的组成如图右半部所示:向量序列经过self-attention,生成向量序列。再经过各自的FC(full connection)层,输出向量序列。
事实上原始的Transformer中,它做的更复杂一些。如下图左半部每个self-attention的输出,和输入再做一个相加(残差),残差输出再进行normalization,最后才是FC的输入。
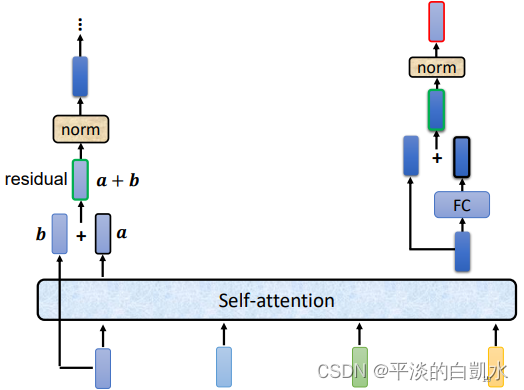
如上图右半部,FC也有残差的结构,残差输出再进行normalization,最后输出block的输出。
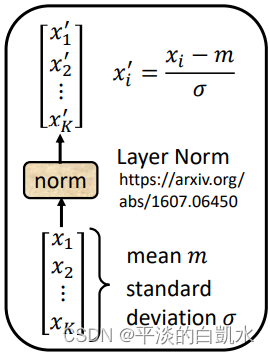
这里的normalization都不是batch norm,而是layer norm。具体做法如下图,即求出向量的均值和标注差。将向量减去均值,除以标准差即可。
回头再看Transformer的encoder模块中的Add&Norm其实就是残差和layer norm的部分。而feed forward就是FC部分。输入也需要加上位置编码positional encoding。
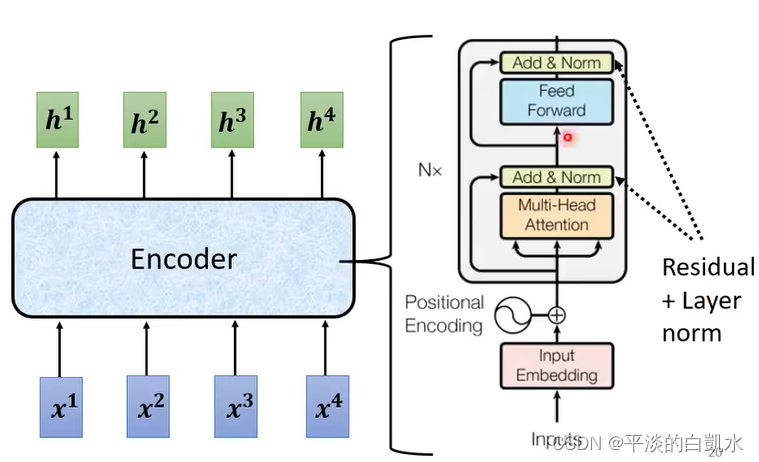
整个block重复N次。
4、Transformer的decoder模块
Decoder其实有两种:Autoregressive(自回归)和Non-autoregressive(非自回归)。Autoregressive decoder需要用已生成的输出来预测下一个位置的输出,Non-autoregressive decoder打破了生成时的串行顺序,同时生成一整个输出。
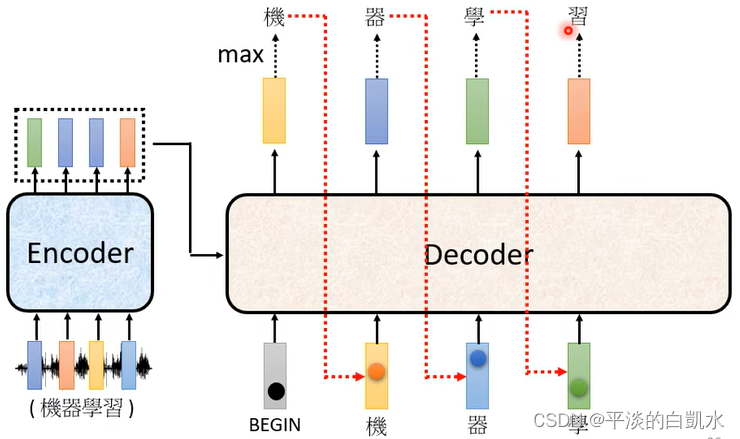
这里只介绍Autoregressive decoder。以语音识别为例,decoder先读入encoder的输出。当给decoder输入一个特殊的输入表示开始,decoder经过softmax输出一个vector,它的size和字典的长度相同。这个vector表示字典中各个字的分布概率(比如中文中每个字的概率)。
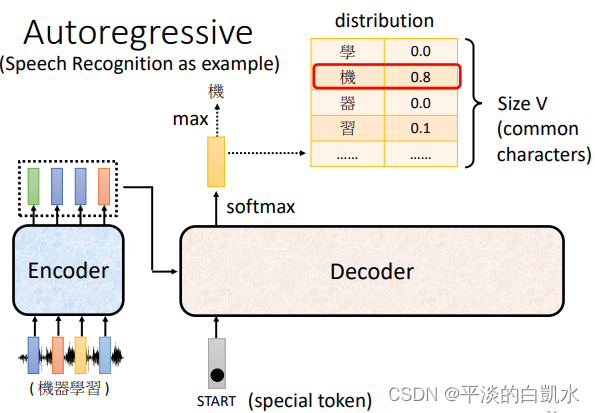
在这个vector中求出max可以得到输出某个字,比如图中为“机”。
之后再将上个输出“机”,转换为one-hot的格式的vector作为输入,送入decoder中,decoder又输出“器”。依此类推,如下图所示。
Transformer的decoder模块如下图右半部所示:
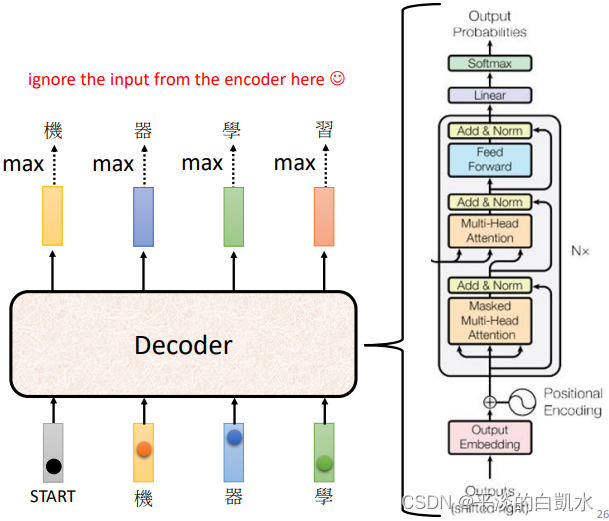
对比encoder和decoder,如果decoder中间部分盖起来,两个部分其实差别并不大。
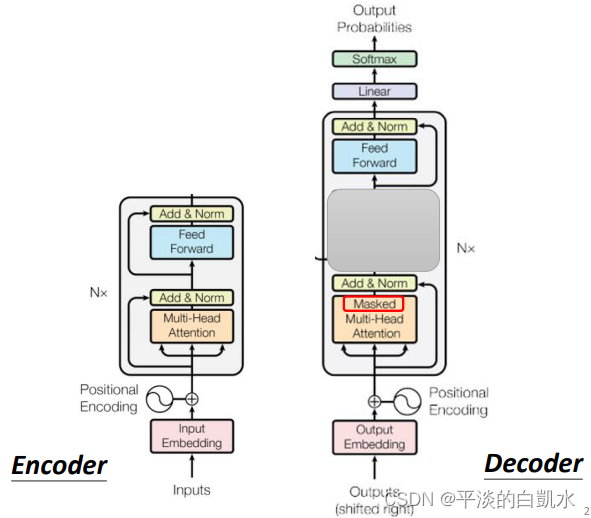
两部分在Multi-Head Attention的地方,decoder加了一个Masked。
什么是Mask self-attention呢?
先看self-attention,对于self- attention,bi的输出考虑了a1-a4全部输入的信息。
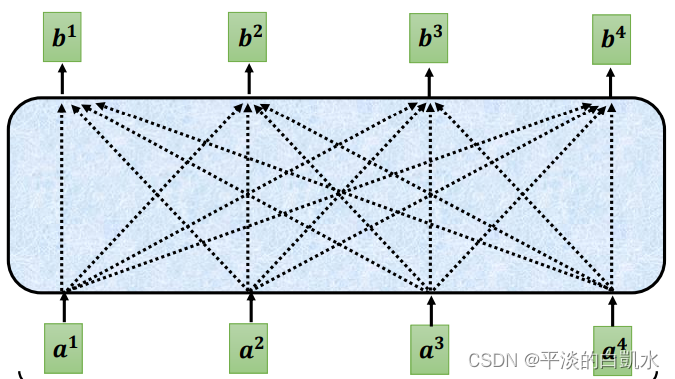
而对于Mask self-attention,输出bi只考虑了已知部分的输入信息,比如b1只和a1有关,b2只和a1、a2有关,以此类推。

为什么要用Mask self-attention?
正如前面所说,对encoder,a1、a2是同时输入的。但对decoder而言,a1、a2……是根据输出依次产生和输入的。所以没有办法知道将来的数据,只能输入过去的数据,即左边的数据。
如何确定输出sequence的长度?
在字典中加入一个“stop token“ END,如下图

当输出END时,表示sequence结束。
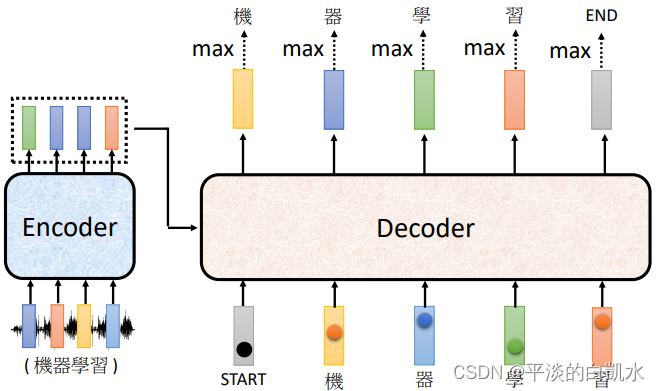
Encoder到decoder的数据传递
这部分就是之前decoder中间的被遮起来的部分。
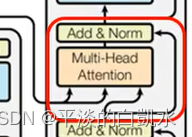
这部分叫做cross attention,它时encoder和decoder之间的桥梁。这部分的输入既有encoder的部分,也有decoder的部分。
cross attention交叉注意力
之所以称为交叉注意力,是因为向量q,k,v不是来自同一个模块。
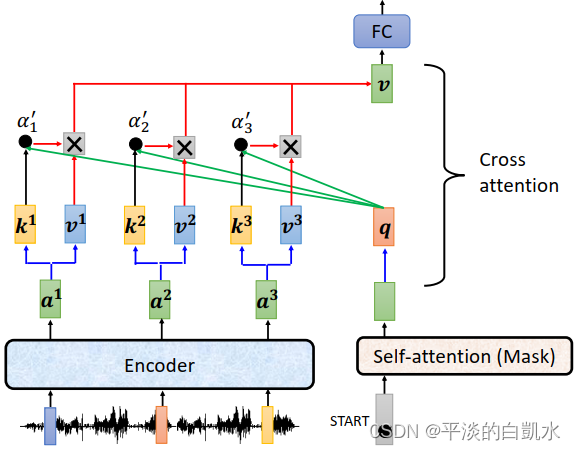
如图所示,向量 ki, vi来自于encoder的输出ai,而q来自于decoder的mask self-attention的输出。最后生成向量v,输入到FC中。
5、Transformer的training训练
和分类问题很象,网络的输出同one-hot表示的ground truth做一个cross entropy。
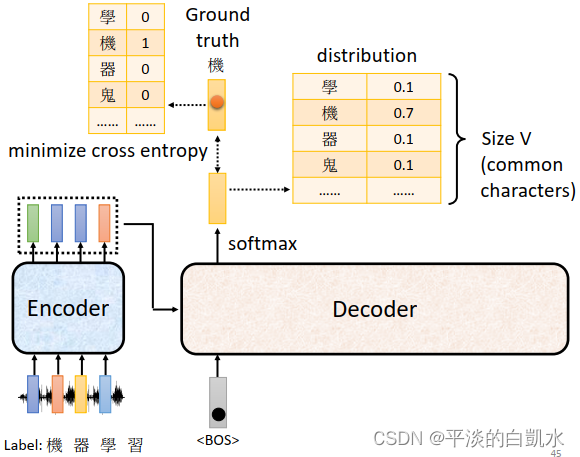
最后,所有的cross entropy之和越小越好。
这时候会有一个问题,decoder的输入是什么呢?是encoder的输出还是ground truth呢?这里用ground truth作为decoder的输入,如下图所示。也就是在训练的时候,decoder的输入也是ground truth,即Teacher Forcing。
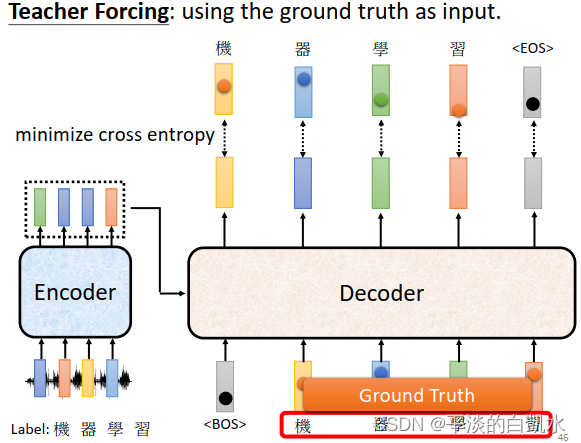
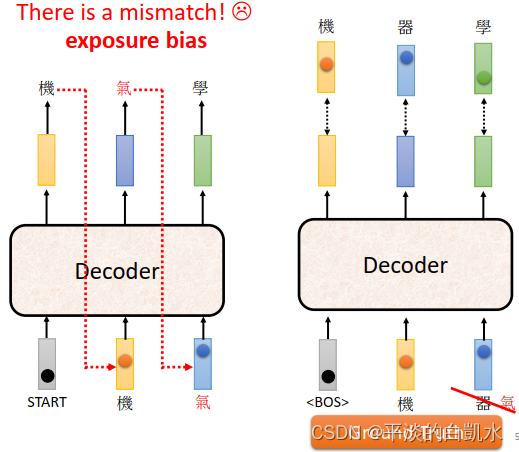
还有一个问题是,训练时decoder的输入都是ground truth。但测试的时候,ground truth时未知的,是把encoder的输出作为decoder的输入。如果这时候encoder的输出出现错误,有没有可能“一步错,步步错“呢?有可能的。怎么解决呢?有一个可思考的方向是训练时给decoder的输入加一些错误的东西。















 1311
1311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









