







pandas分组与聚合
分组聚合是最常使用的数据操作之一。
分组 - DataFrame.groupby()
分组 steps:
- Splitting the data into groups based on some criteria
- Applying a function to each group independently
- Combining the results into a data structure
这里创建的数据对象如下,甲和乙列下面的数据可以明显的进行分组。
import pandas as pd
import numpy as np
years = pd.date_range("20220101", periods=12, freq="M").year
# years
columns = list("甲乙丙丁戊己庚辛壬癸")
df = pd.DataFrame(
{
"甲": ["foo", "bar", "foo", "bar", "foo", "bar"] * 2,
"乙": ["one", "one", "two", "three", "two", "two"] * 2,
} |
{
col: pd.Series(np.random.randint(1, 100, len(years)), index=years) for col in columns[2:]
}
)
# df
完整语法:
DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, observed=False, dropna=True)
by参数可以是:映射、函数、标签、Grouper 对象,或是以上的类型构成的列表,如标签列表。- 返回结果是一个
DataFrameGroupBy对象:- 对其进行标签索引还是一个
DataFrameGroupBy对象。 - 使用
list将其列表化,看具体的分组情况,每一组有一个共同的组标签,组数据结构是 DataFrame。
- 对其进行标签索引还是一个
- 这里只是浅入浅出一下,通过一两个例子认识分组的效果,不多介绍更多的参数。
df.groupby("甲") # <pandas.core.groupby.generic.DataFrameGroupBy object at 0x...>
df.groupby("甲")[["癸", "丁"]]
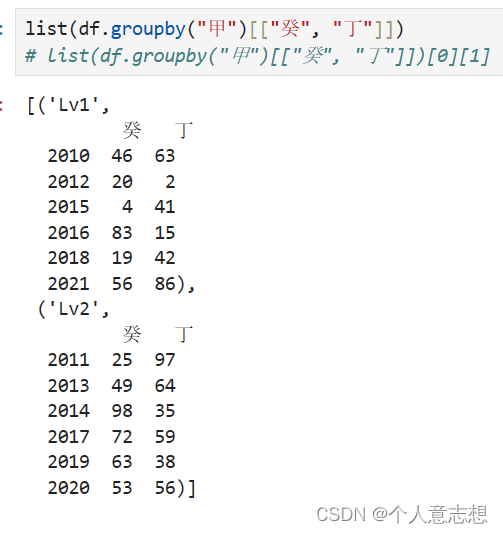
list(df.groupby("甲")[["癸", "丁"]])
list(df.groupby(["甲", "乙"])[["癸", "丁"]])
| 一级分组 | 二级分组 |
|---|---|
 |  |
聚合
所谓聚合就是在对数据进行指定分组后,再按需进行的一系列操作(多为计算),如求统计量(最值、平均值……)、转换等。
聚合函数与方法通常是实现数据处理的最终目的手段,分组很多情况下也是为更好地聚合。
常用统计量的计算
这里也是简要描述,很多方法都可以传入参数,实现更多功能。
- 求总和 -
DataFrameGroupBy.sum() - 求平均值 -
DataFrameGroupBy.mean() - 求中值(中位数) -
DataFrameGroupBy.median() - 求最值 -
DataFrameGroupBy.max() && DataFrameGroupBy.min() - 求协方差 -
DataFrameGroupBy.cov() - 求相关 -
DataFrameGroupBy.corr() - 求每一组的条目数 -
DataFrameGroupBy.count() - 求去重后的条目数 -
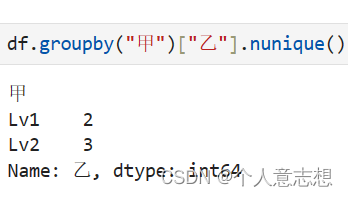
DataFrameGroupBy.nunique()
g1 = df.groupby("甲")[["癸", "丁"]]
g2 = df.groupby(["甲", "乙"])[["癸", "丁"]]
g1.sum()
g1.mean()
g1.median()
g1.max() # g1.min()
g1.count()
g1.cov()
具体这些统计量计算出什么结果人尽皆知,这里不予展示;下面是一个求去重后条目数的结果,以供更好理解:















 4389
4389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









