






一、报错信息IndexError: list index out of range
上面显示:列表索引超出范围
问题可能是导入模块出现问题,我这边重复导入两次模块。
这是第一次,在开头导入模块BiLevelRoutingAttention(模块名称不一定一样要注意)
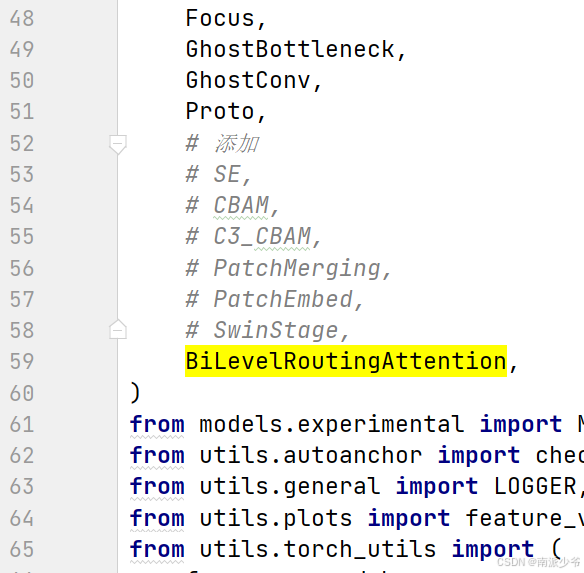
第二次,这次在yolo.py文件中间到导入模块BiLevelRoutingAttention
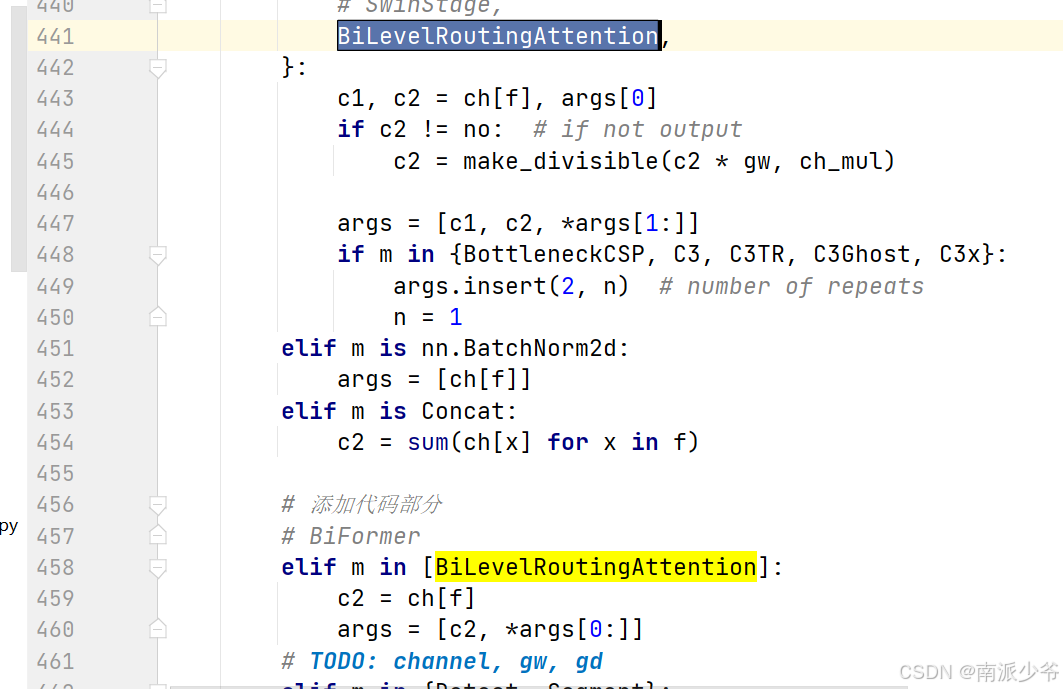
二、解决方法
只需要将yolo.py文件代码中间的模块BiLevelRoutingAttention注释到就可以了。
重新运行yolo.py文件就可以了
三、BiLevelRoutingAttention模块代码
模块BiLevelRoutingAttention的代码是添加到\yolov5-master\models\common.py里面。
BiLevelRoutingAttention模块代码详细
from torch import Tensor
from typing import Tuple
import torch.nn.functional as F
from einops import rearrange
class TopkRouting(nn.Module):
"""
differentiable topk routing with scaling
Args:
qk_dim: int, feature dimension of query and key
topk: int, the 'topk'
qk_scale: int or None, temperature (multiply) of softmax activation
with_param: bool, wether inorporate learnable params in routing unit
diff_routing: bool, wether make routing differentiable
soft_routing: bool, wether make output value multiplied by routing weights
"""
def __init__(self, qk_dim, topk=4, qk_scale=None, param_routing=False, diff_routing=False):
super().__init__()
self.topk = topk
self.qk_dim = qk_dim
self.scale = qk_scale or qk_dim ** -0.5
self.diff_routing = diff_routing
self.emb = nn.Linear(qk_dim, qk_dim) if param_routing else nn.Identity()
self.routing_act = nn.Softmax(dim=-1)
def forward(self, query: Tensor, key: Tensor) -> Tuple[Tensor]:
if not self.diff_routing:
query, key = query.detach(), key.detach()
query_hat, key_hat = self.emb(query), self.emb(key)
attn_logit = (query_hat * self.scale) @ key_hat.transpose(-2, -1)
topk_attn_logit, topk_index = torch.topk(attn_logit, k=self.topk, dim=-1)
r_weight = self.routing_act(topk_attn_logit)
return r_weight, topk_index
class KVGather(nn.Module):
def __init__(self, mul_weight='none'):
super().__init__()
assert mul_weight in ['none', 'soft', 'hard']
self.mul_weight = mul_weight
def forward(self, r_idx: Tensor, r_weight: Tensor, kv: Tensor):
n, p2, w2, c_kv = kv.size()
topk = r_idx.size(-1)
topk_kv = torch.gather(kv.view(n, 1, p2, w2, c_kv).expand(-1, p2, -1, -1, -1),
dim=2,
index=r_idx.view(n, p2, topk, 1, 1).expand(-1, -1, -1, w2, c_kv)
)
if self.mul_weight == 'soft':
topk_kv = r_weight.view(n, p2, topk, 1, 1) * topk_kv
elif self.mul_weight == 'hard':
raise NotImplementedError('differentiable hard routing TBA')
return topk_kv
class QKVLinear(nn.Module):
def __init__(self, dim, qk_dim, bias=True):
super().__init__()
self.dim = dim
self.qk_dim = qk_dim
self.qkv = nn.Linear(dim, qk_dim + qk_dim + dim, bias=bias)
def forward(self, x):
q, kv = self.qkv(x).split([self.qk_dim, self.qk_dim + self.dim], dim=-1)
return q, kv
class BiLevelRoutingAttention(nn.Module):
"""
n_win: number of windows in one side (so the actual number of windows is n_win*n_win)
kv_per_win: for kv_downsample_mode='ada_xxxpool' only, number of key/values per window. Similar to n_win, the actual number is kv_per_win*kv_per_win.
topk: topk for window filtering
param_attention: 'qkvo'-linear for q,k,v and o, 'none': param free attention
param_routing: extra linear for routing
diff_routing: wether to set routing differentiable
soft_routing: wether to multiply soft routing weights
"""
def __init__(self, dim, n_win=7, num_heads=8, qk_dim=None, qk_scale=None,
kv_per_win=4, kv_downsample_ratio=4, kv_downsample_kernel=None, kv_downsample_mode='identity',
topk=4, param_attention="qkvo", param_routing=False, diff_routing=False, soft_routing=False,
side_dwconv=3,
auto_pad=True):
super().__init__()
self.dim = dim
self.n_win = n_win # Wh, Ww
self.num_heads = num_heads
self.qk_dim = qk_dim or dim
assert self.qk_dim % num_heads == 0 and self.dim % num_heads == 0, 'qk_dim and dim must be divisible by num_heads!'
self.scale = qk_scale or self.qk_dim ** -0.5
self.lepe = nn.Conv2d(dim, dim, kernel_size=side_dwconv, stride=1, padding=side_dwconv // 2,
groups=dim) if side_dwconv > 0 else \
lambda x: torch.zeros_like(x)
self.topk = topk
self.param_routing = param_routing
self.diff_routing = diff_routing
self.soft_routing = soft_routing
# router
assert not (self.param_routing and not self.diff_routing)
self.router = TopkRouting(qk_dim=self.qk_dim,
qk_scale=self.scale,
topk=self.topk,
diff_routing=self.diff_routing,
param_routing=self.param_routing)
if self.soft_routing: # soft routing, always diffrentiable (if no detach)
mul_weight = 'soft'
elif self.diff_routing: # hard differentiable routing
mul_weight = 'hard'
else: # hard non-differentiable routing
mul_weight = 'none'
self.kv_gather = KVGather(mul_weight=mul_weight)
# qkv mapping (shared by both global routing and local attention)
self.param_attention = param_attention
if self.param_attention == 'qkvo':
self.qkv = QKVLinear(self.dim, self.qk_dim)
self.wo = nn.Linear(dim, dim)
elif self.param_attention == 'qkv':
self.qkv = QKVLinear(self.dim, self.qk_dim)
self.wo = nn.Identity()
else:
raise ValueError(f'param_attention mode {self.param_attention} is not surpported!')
self.kv_downsample_mode = kv_downsample_mode
self.kv_per_win = kv_per_win
self.kv_downsample_ratio = kv_downsample_ratio
self.kv_downsample_kenel = kv_downsample_kernel
if self.kv_downsample_mode == 'ada_avgpool':
assert self.kv_per_win is not None
self.kv_down = nn.AdaptiveAvgPool2d(self.kv_per_win)
elif self.kv_downsample_mode == 'ada_maxpool':
assert self.kv_per_win is not None
self.kv_down = nn.AdaptiveMaxPool2d(self.kv_per_win)
elif self.kv_downsample_mode == 'maxpool':
assert self.kv_downsample_ratio is not None
self.kv_down = nn.MaxPool2d(self.kv_downsample_ratio) if self.kv_downsample_ratio > 1 else nn.Identity()
elif self.kv_downsample_mode == 'avgpool':
assert self.kv_downsample_ratio is not None
self.kv_down = nn.AvgPool2d(self.kv_downsample_ratio) if self.kv_downsample_ratio > 1 else nn.Identity()
elif self.kv_downsample_mode == 'identity': # no kv downsampling
self.kv_down = nn.Identity()
elif self.kv_downsample_mode == 'fracpool':
raise NotImplementedError('fracpool policy is not implemented yet!')
elif kv_downsample_mode == 'conv':
raise NotImplementedError('conv policy is not implemented yet!')
else:
raise ValueError(f'kv_down_sample_mode {self.kv_downsaple_mode} is not surpported!')
self.attn_act = nn.Softmax(dim=-1)
self.auto_pad = auto_pad
def forward(self, x, ret_attn_mask=False):
"""
x: NHWC tensor
Return:
NHWC tensor
"""
x = rearrange(x, "n c h w -> n h w c")
if self.auto_pad:
N, H_in, W_in, C = x.size()
pad_l = pad_t = 0
pad_r = (self.n_win - W_in % self.n_win) % self.n_win
pad_b = (self.n_win - H_in % self.n_win) % self.n_win
x = F.pad(x, (0, 0, # dim=-1
pad_l, pad_r, # dim=-2
pad_t, pad_b)) # dim=-3
_, H, W, _ = x.size() # padded size
else:
N, H, W, C = x.size()
assert H % self.n_win == 0 and W % self.n_win == 0 #
x = rearrange(x, "n (j h) (i w) c -> n (j i) h w c", j=self.n_win, i=self.n_win)
q, kv = self.qkv(x)
q_pix = rearrange(q, 'n p2 h w c -> n p2 (h w) c')
kv_pix = self.kv_down(rearrange(kv, 'n p2 h w c -> (n p2) c h w'))
kv_pix = rearrange(kv_pix, '(n j i) c h w -> n (j i) (h w) c', j=self.n_win, i=self.n_win)
q_win, k_win = q.mean([2, 3]), kv[..., 0:self.qk_dim].mean(
[2, 3]) # window-wise qk, (n, p^2, c_qk), (n, p^2, c_qk)
lepe = self.lepe(rearrange(kv[..., self.qk_dim:], 'n (j i) h w c -> n c (j h) (i w)', j=self.n_win,
i=self.n_win).contiguous())
lepe = rearrange(lepe, 'n c (j h) (i w) -> n (j h) (i w) c', j=self.n_win, i=self.n_win)
r_weight, r_idx = self.router(q_win, k_win) # both are (n, p^2, topk) tensors
kv_pix_sel = self.kv_gather(r_idx=r_idx, r_weight=r_weight, kv=kv_pix) # (n, p^2, topk, h_kv*w_kv, c_qk+c_v)
k_pix_sel, v_pix_sel = kv_pix_sel.split([self.qk_dim, self.dim], dim=-1)
k_pix_sel = rearrange(k_pix_sel, 'n p2 k w2 (m c) -> (n p2) m c (k w2)',
m=self.num_heads) # flatten to BMLC, (n*p^2, m, topk*h_kv*w_kv, c_kq//m) transpose here?
v_pix_sel = rearrange(v_pix_sel, 'n p2 k w2 (m c) -> (n p2) m (k w2) c',
m=self.num_heads) # flatten to BMLC, (n*p^2, m, topk*h_kv*w_kv, c_v//m)
q_pix = rearrange(q_pix, 'n p2 w2 (m c) -> (n p2) m w2 c',
m=self.num_heads) # to BMLC tensor (n*p^2, m, w^2, c_qk//m)
attn_weight = (
q_pix * self.scale) @ k_pix_sel # (n*p^2, m, w^2, c) @ (n*p^2, m, c, topk*h_kv*w_kv) -> (n*p^2, m, w^2, topk*h_kv*w_kv)
attn_weight = self.attn_act(attn_weight)
out = attn_weight @ v_pix_sel # (n*p^2, m, w^2, topk*h_kv*w_kv) @ (n*p^2, m, topk*h_kv*w_kv, c) -> (n*p^2, m, w^2, c)
out = rearrange(out, '(n j i) m (h w) c -> n (j h) (i w) (m c)', j=self.n_win, i=self.n_win,
h=H // self.n_win, w=W // self.n_win)
out = out + lepe
out = self.wo(out)
if self.auto_pad and (pad_r > 0 or pad_b > 0):
out = out[:, :H_in, :W_in, :].contiguous()
if ret_attn_mask:
return out, r_weight, r_idx, attn_weight
else:
return rearrange(out, "n h w c -> n c h w")分享并解决一些简单问题!!!


















 1693
1693

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









