







一、 目标
准备3台Ubantu的Linux服务器h1、h2、h3。h1为主节点,担任NameNode、SecondNameNode、JobTracker三个角色;h2和h3作为两个从节点,担任DataNode和TaskTracker两个角色。
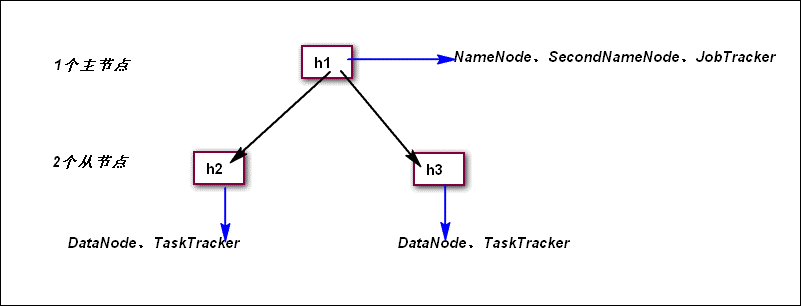
二、 步骤预览

三、 环境需求
开始搭建集群前,我们首先要确保,三台机器都已安装了SSH(一般默认安装系统时都安装了),并且配置好了JDK环境。JDK配置比较简单,这里不再做介绍。下面介绍SSH的检测和安装:
检查看机子是否安装了SSH用如下命令:
dpkg --list|grepssh
如果你看到的有openssh-client和openssh-server,就不再需要再安装了,一般来说openssh-client已经安装,但是openssh-server不一定,如果有openssh-server没有安装,用一下命令安装(这是在线安装,前提是机器必须能上Internet):
sudo apt-getinstall openssh-server
同理,如果客户端没有安装,则用如下命令
sudo apt-getinstall openssh-client
四、 开始搭建集群
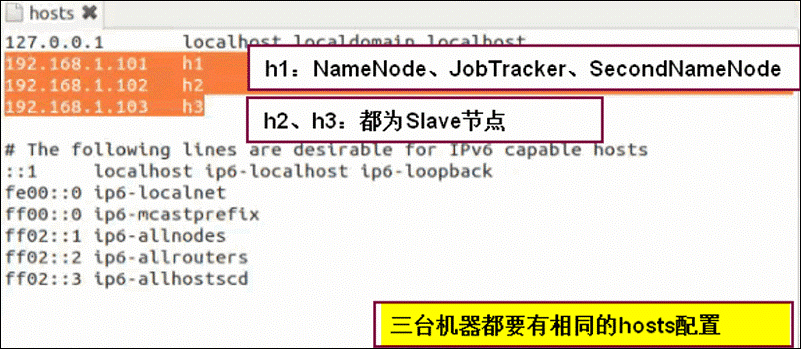
第一步:配置host文件
建议配置好一台,然后拷贝到其它机器上
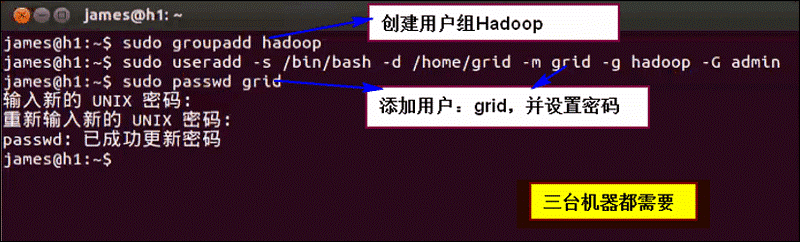
第二步:建立Hadoop运行账号
三台机器都建立一个用户:hadoop,密码都为grid。为了下面操作方便。
第三步:配置SSH免密码登录
需要做到三件事:
a) 保证Master(NameNode)能够SSH免密码登录到“本机—localhost”
b) 保证Master能够SSH免密码登录到所有的Slave(h2/h3)
c) 能够SSH免密码登录到JobTracker(h1)。注,这里的1、3重复了,因为Master与JobTracker为一台机器h1,做一个即可。
首先,ssh-keygen -t dsa-P "" –f ~/.ssh/id_dsa生成机器h1(Master)的一对公钥和私钥:


然后,cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys将公钥加入到已认证的key中:

解释一下,第一条生成ssh密码的命令,-t 参数表示生成算法,有rsa和dsa两种;-P表示使用的密码,这里使用“”空字符串表示无密码。第二条命令将生成的密钥写入authorized_keys文件。这时输入 sshlocalhost,弹出写入提示后回车,便可无密码登录本机。同理,将authorized_keys文件 通过 scp命令拷贝到其它主机相同目录下,则可无密码登录其它机器。
然后进入到~/.ssh目录下,发现多了authorized_keys文件:

然后ssh localhost登录本机,还需要输入yes:
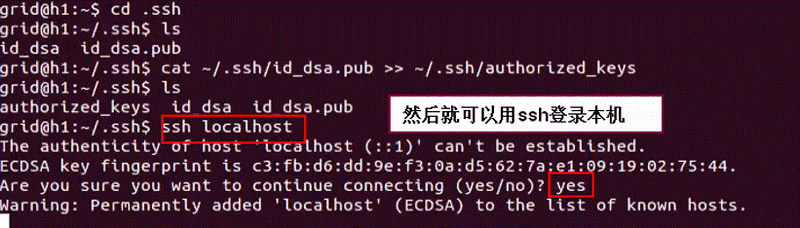
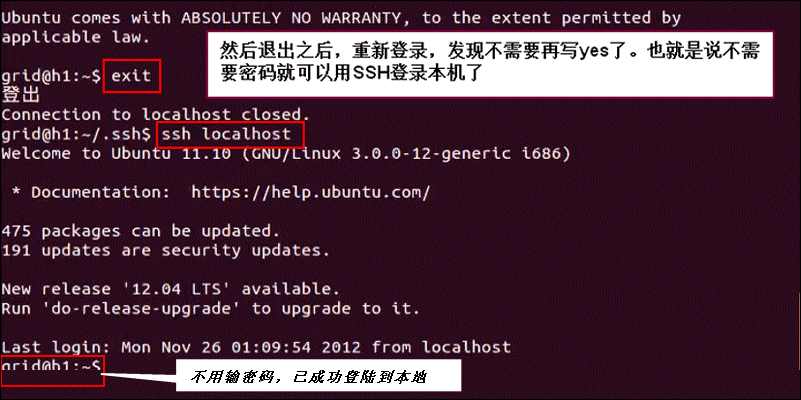
然后退出登录,再次ssh localhost 发现不用输入任何东西即可成功登陆本机了,表示本机的ssh免密码登录已配置成功:
然后,我们需要将这个公钥拷贝到其它Slave节点node2、node3,即配置NameNode可以ssh免密码登录node2、node3:
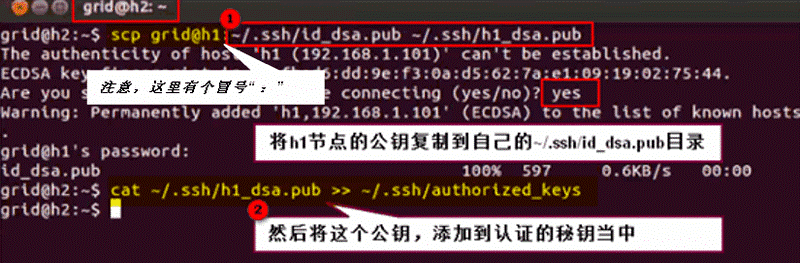
此时我们切换回h1,然后直接用ssh h2登录h2,发现已不用再输密码了,表示h2机器已配置好对h1的免密码登录了:

对h3机器也需要做相同的操作,即配置h3对h1的免密码登录,这里不再重复。
第四步:下载并解压Hadoop安装包
第五步:配置Hadoop-conf目录下的配置
这里要涉及到的配置文件有6个:
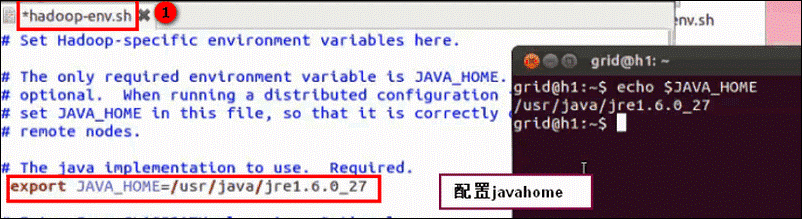
~/hadoop/etc/hadoop/hadoop-env.sh
~/hadoop/etc/hadoop/core-site.xml
~/hadoop/etc/hadoop/hdfs-site.xml
~/hadoop/etc/hadoop/mapred-site.xml
~/hadoop/etc/hadoop/masters
~/hadoop/etc/hadoop/slaves
详细配置如下:
hadoop-env.sh:
core-site.xml:
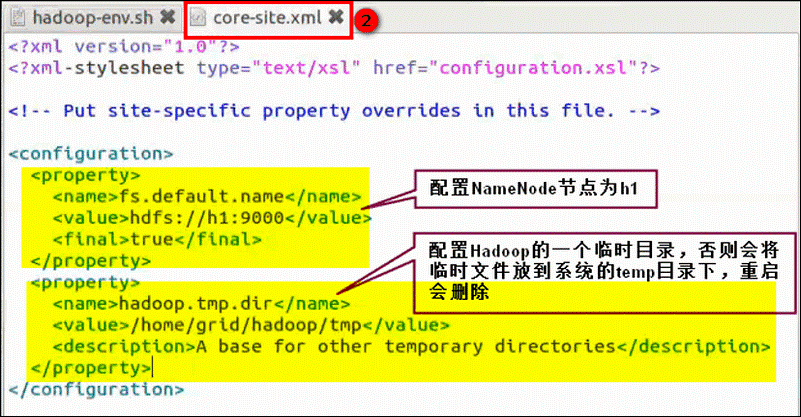
hdfs-site.xml:
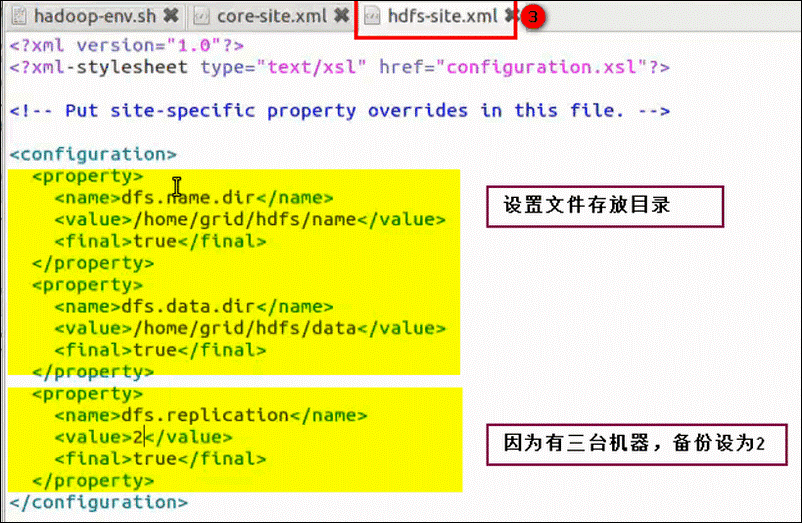
mapred-site.xml:
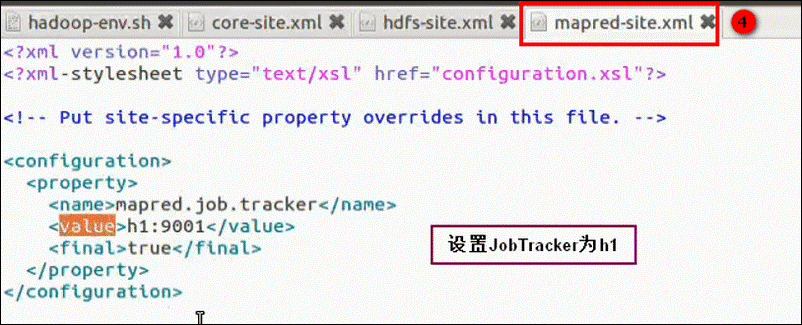
masters:
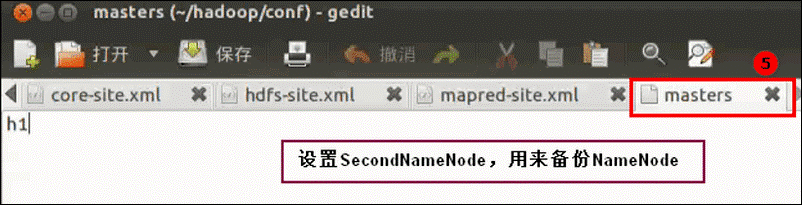
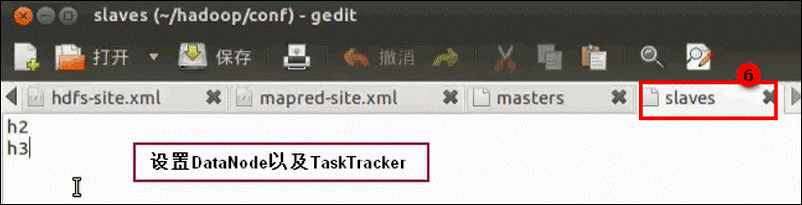
slaves:
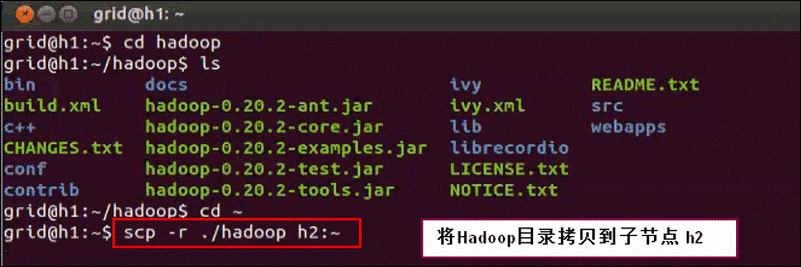
第六步:向各节点复制Hadoop

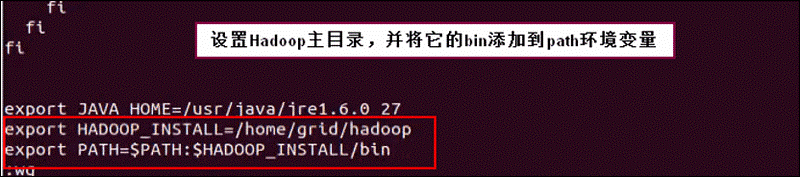
配置一下h1的环境变量,将Hadoop的bin目录添加到Path环境变量中:


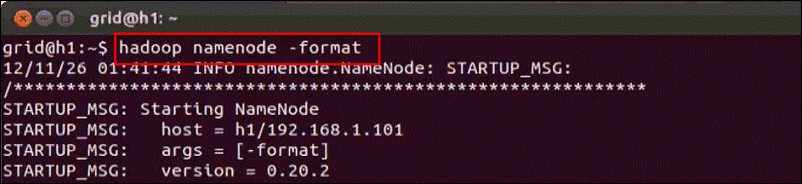
第七步:格式化NameNode
第八步:启动Hadoop集群

第九步:用jps命令检查各节点后台进程是否成功启动
查看master(h1):

查看slave1(h2):

查看slave2(h3):

第十步:执行一个wordCount程序检查集群
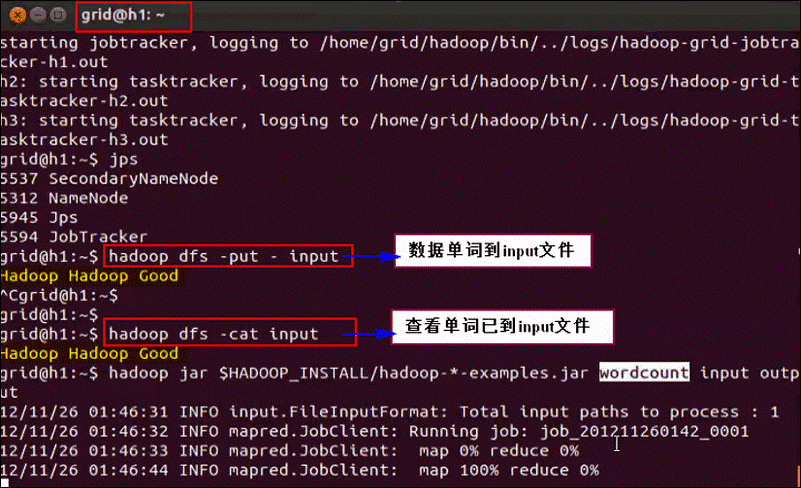
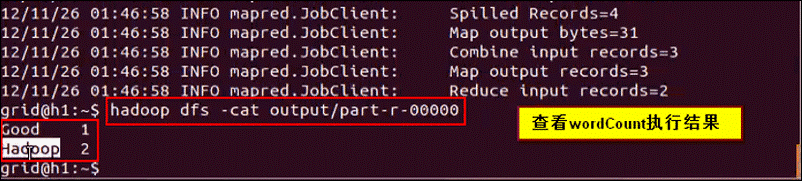
第十一步:查看执行结果
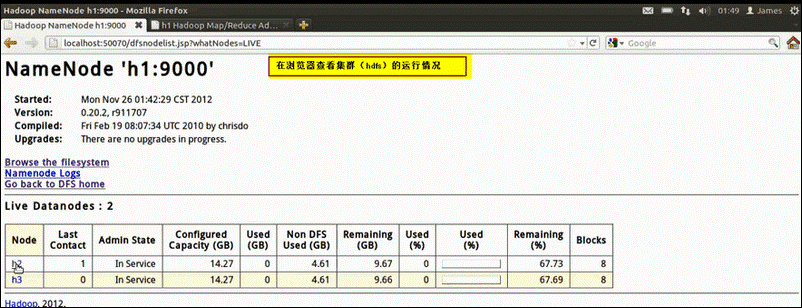
可以在浏览器输入localhost:50070在后台查看HDFS状况:
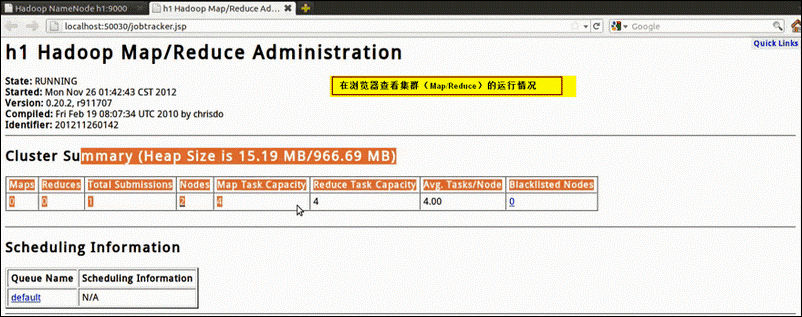
可以在浏览器输入localhost:50030在后台查看MapReduce状况:
到此,Hadoop1.x集群配置完毕~~















 703
703











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









