







什么是知识图谱?
简单理解就是一个图,节点是各种各样的现实当中的实体,如人、物、组织等,线是反应节点之间的关系或者属性。如图所示。
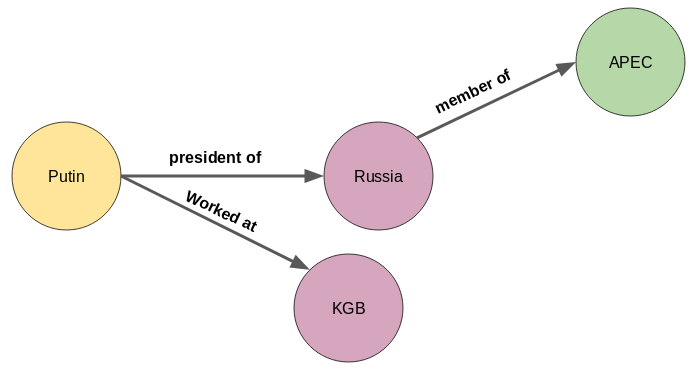
知识图谱的作用
如今知识图谱广泛应用于聊天机器人,推荐系统等方面,而在金融、农业、电商、医疗健康、环境保护、工业制造场景等各种不同的垂直领域,得益于知识图谱的先验知识的特性,均得到了广泛的应用。说的抽象点,知识图谱就是把离散的符号表述,变成了连续的向量表示的巨大的知识网络图。
知识图谱的表示和存储
目前有两种方法,一种是 RDF ,它是由很多三元组组成的,优点是易于发布分享,缺点是不支持实体或者关系拥有属性,如果非要加属性则需要做特殊的修改,目前多用于学术场景,常见的有 Jena ,是开源的 Java 语义网框架,用于链接数据和构建语义网,可存储 RDF、RDFS 类型数据,易于构建推理规则,支持用户进行自定义推理规则。另一种方法是图数据库,有高效的查询和搜索功能,如 Neo4j 应用最广泛,方便数据可视化,更容易表达现实的业务场景中的关系,数据量在不过十亿级的情况下效果还是可以的,唯一的缺点就是不支持分布式。

知识抽取
构建知识图谱的数据无非就两个来源:一个是公司内部的业务数据,一般都存在结构化的数据库中,可以直接拿来用。另一种是需要通过爬虫从网上抓取的网页,或者外部提供的数据,此类数据比较杂乱无结构,需要进行必要的处理。所以难点主要来源于后者。主要涉及到自然语言的相关技术,如实体命名识别,关系抽取,实体统一,指代消解。如下图使用非结构化的文本构建知识图谱。
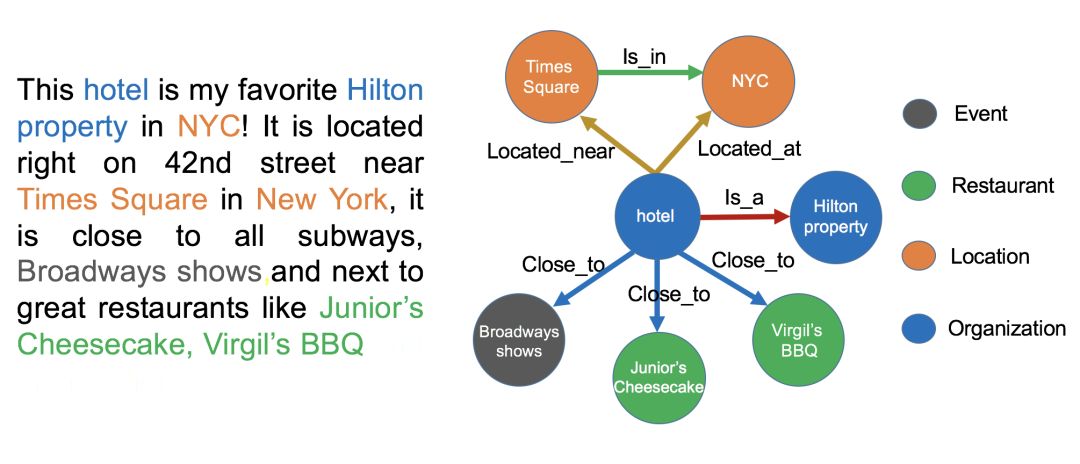
上面的涉及的几项 NLP 技术都用到了
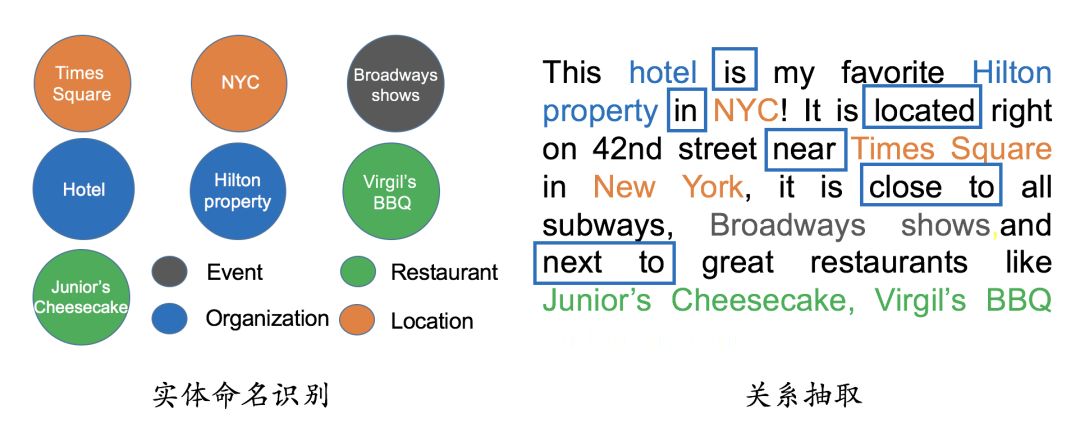

搭建知识图谱
常见误区:在不涉及数据的重要性情况下,很多人认为搭建一个知识图谱系统的重点在于算法和开发。但事实并不是想象中的那样,其实最重要的核心在于对业务的理解以及对知识图谱本身的设计,并且还要对未来业务有一定的预估,这就类似于对于一个业务系统,数据库表的设计尤其关键,而且这种设计绝对离不开对业务的深入理解以及对未来业务场景变化的预估。
主要的步骤:
-
明确自身业务需不需要知识图谱的支持

-
定义具体的业务问题
-
数据的收集和预处理
常见问题:
1. 我们已经有哪些数据? 2. 虽然现在没有,但有可能拿到哪些数据? 3. 其中哪部分数据可以用来降低风险? 4. 哪部分数据可以用来构建知识图谱? 5. 注意并不是所有跟目标相关的数据都要进入知识图谱 -
知识图谱的设计
常见问题:
1. 需要哪些实体、关系和属性? 2. 哪些属性可以做为实体,哪些实体可以作为属性? 3. 哪些信息不需要放在知识图谱中?设计原则:
业务原则:一切要从业务逻辑出发,并且通过观察知识图谱的设计也很容易推测其背后业务的逻辑,而且设计时也要想好未来业务可能的变化。好的设计很容易让人从图谱中看到业务本身的逻辑。 分析原则:不需要把跟关系分析无关的实体放在图谱当中。 效率原则:在于把知识图谱设计成小而轻的存储载体,对关系分析无关紧要的信息放在传统的关系型数据库当中。 冗余原则:有些重复性信息、高频信息可以放到传统数据库当中。 -
知识图谱的存储
存储上我们要面临存储系统的选择,但由于我们设计的知识图谱带有属性,图数据库可以作为首选。但至于选择哪个图数据库也要看业务量以及对效率的要求。如果数据量特别庞大,则 Neo4j 很可能满足不了业务的需求,这时候不得不去选择支持准分布式的系统比如 OrientDB , JanusGraph(原 Titan) 等,或者通过效率、冗余原则把信息存放在传统数据库中,从而减少知识图谱所承载的信息量。 通常来讲 Neo4j 已经足够了。
-
上层应用的开发以及系统的评估
构建好知识图谱,根据需求,从图谱中挖掘有价值的信息。从算法的角度来讲,有下面三种不同的场景:一种是基于规则的,常见的应用分别是不一致性验证、基于规则的特征提取、基于模式的判断;另一种是基于概率的,常见的应用有社区挖掘、聚类等;还有一种是基于动态网络的,常见的应用有 T 时刻到 T+1 时刻风险变化等。
相比规则的方法论,基于概率的方法的缺点在于:需要足够多的数据。如果数据量很少,而且整个图谱比较稀疏(Sparse),基于规则的方法可以成为我们的首选。尤其是对于金融领域来说,数据标签会比较少,这也是为什么基于规则的方法论还是更普遍地应用在金融领域中的主要原因。
鉴于目前 AI 技术的现状,基于规则的方法论还是在垂直领域的应用中占据主导地位,但随着数据量的增加以及方法论的提升,基于概率的模型也将会逐步带来更大的价值。
结尾
首先,知识图谱的主要作用还是在于分析关系,尤其是深度的关系。所以在业务上,首先要确保它的必要性,其实很多问题可以用非知识图谱的方式来解决。
知识图谱领域一个最重要的话题是知识的推理。 而且知识的推理是走向强人工智能的必经之路。但很遗憾的,目前很多语义网络的角度讨论的推理技术(比如基于深度学习,概率统计)很难在实际的垂直应用中落地。其实目前最有效的方式还是基于一些规则的方法论,除非我们有非常庞大的数据集。
最后,还是要强调一点,知识图谱工程本身还是业务为重心,以数据为中心。不要低估业务和数据的重要性。
本文参考:https://blog.csdn.net/lzw17750614592/article/details/82666287
















 2395
2395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











