




知识图谱调研报告
一、 知识图谱介绍
知识图谱是一种用于组织世界上结构化知识的抽象概念,它可以将来自多个数据源的信息集成在一起。知识图谱的节点和边缘都有特定的含义,可以表示现实世界中的实体、事件、情况或概念,并说明它们之间的关系[1]。知识图谱已经开始在自然语言处理和计算机视觉中扮演重要角色,因为它可以表示从这些领域中提取的信息。知识图谱中的领域知识正在输入到机器学习模型中,以产生更好的预测结果[1]。知识图谱的基本术语、概念和用法可以在这篇博客文章中了解到[1]。
1.1知识图谱定义
知识图谱(英语:Knowledge Graph),是结构化的语义知识库,用于以符号形式描述物理世界中的概念及其相互关系。其基本组成单位是“实体-关系-实体”三元组,以及实体及其相关属性-值对,实体间通过关系相互联结,构成网状的知识结构。知识图谱可以实现Web从网页链接向概念链接转变,支持用户按主题而不是字符串检索,真正实现语义检索。基于知识图谱的搜索引擎,能够以图形方式向用户反馈结构化的知识,用户不必浏览大量网页即能准确定位和深度获取知识[2]。
在知识表示中,知识图谱是一种知识库,其中的数据通过图结构的数据模型或拓扑整合而成。知识图谱通常被用来存储彼此之间具有相互联系的实体[2]。1980年代后期,格罗宁根大学和特文特大学联合启动了一个名为知识图谱的项目。Google、Bing和Yahoo等搜索引擎均已引入知识图谱并在搜索界面的右侧显示[2]。
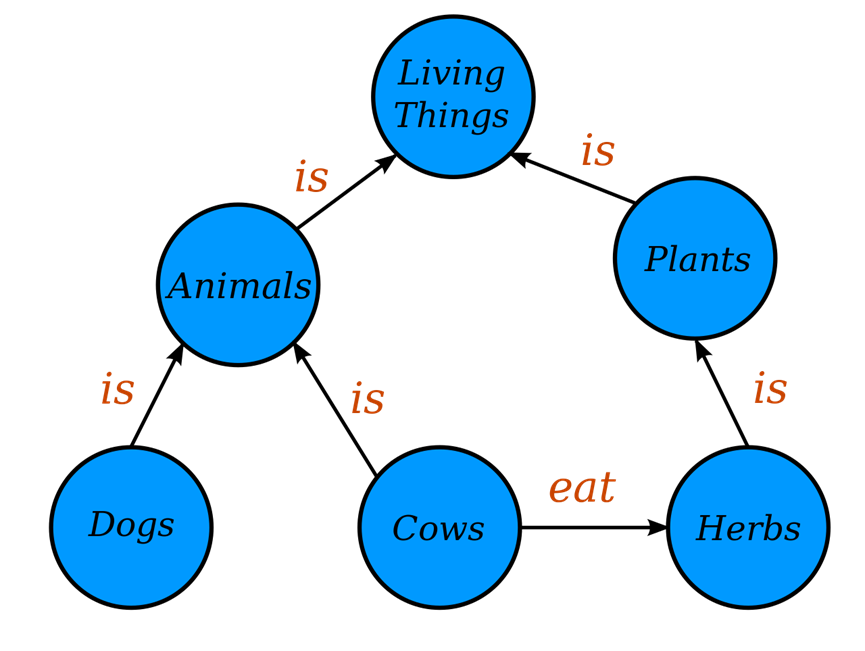
知识图谱是一个有向标记图,其中我们将节点和边缘与特定的领域含义相关联。节点可以是任何东西,例如人、公司、计算机等。边缘标签捕获节点之间的关系,例如两个人之间的友谊关系、公司和人之间的客户关系或两台计算机之间的网络连接等。知识图谱的有向标记图表示根据应用程序的需要而使用在各种方式中。知识图谱作为一种数据结构,用于存储信息。信息可以通过人工输入、自动化和半自动化方法的组合添加到知识图谱中。无论知识输入的方法如何,都希望记录的信息可以被人类轻松理解和验证[1]。
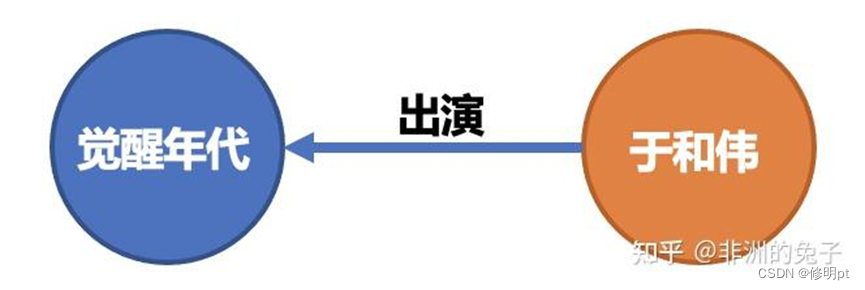
上面的图展示了知识图谱的基本结构和单元,圆圈也就是节点,代表实体,箭头也就是边,代表关系。上图中表示的知识用自然语言可以表述为“于和伟 出演 了 觉醒年代”。
同时每个节点代表的实体还存在着一些属性,比如“《觉醒年代》”这个节点,我们可以把一些基本信息作为属性,比如影片名称、发行时间、影片类型、集数等。
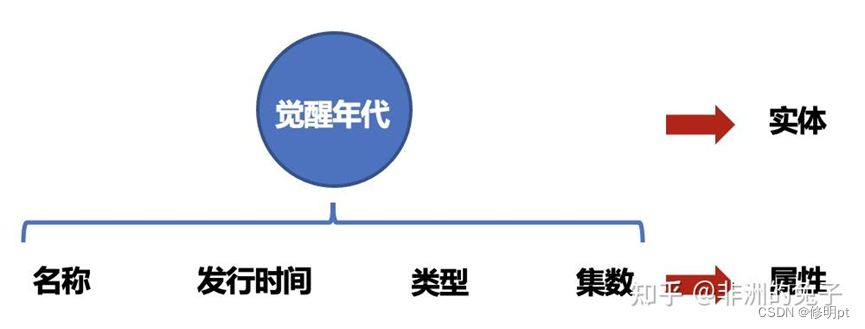
知识图谱就是由这些节点和边组成的网络状的知识库。知识图谱建立起来后的各种应用将在后面继续讨论。
1.2 知识图谱的分类
知识图谱按照功能和应用场景可以分为通用知识图谱和领域知识图谱。其中通用知识图谱面向的是通用领域,强调知识的广度,形态通常为结构化的百科知识,针对的使用者主要为普通用户;领域知识图谱则面向某一特定领域,强调知识的深度,通常需要基于该行业的数据库进行构建,针对的使用者为行业内的从业人员以及潜在的业内人士等。

1.3 知识图谱的发展历程
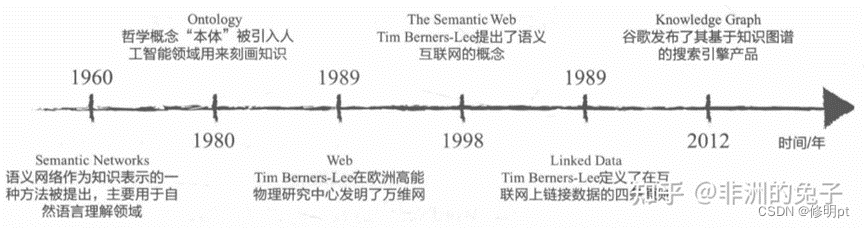
知识图谱的起源可以追溯至1960年,在人工智能的早起发展中,有两个主要的分支,也就是两派系,一个是符号派,注重模拟人的心智,研究如何用计算机符号表示人脑中的知识,以此模拟人的思考、推理过程;一个则是连接派,注重模拟人脑的生理结构,由此发展了人工神经网络。这个时候提出了Semantic Networks,也就是语义网络,作为一种知识表示的方法,主要用于自然语言理解领域。
1970年,随着专家系统的提出和商业化发展,知识库(Knowledge Base)构建和知识表示得到重视。专家系统的主要思想认为专家是基于脑中的知识来进行决策的,所以为了实现人工智能应该用计算机符号来表示这些知识,通过推理机来模仿人脑对知识进行处理。早期的专家系统常用的知识表示方法有基于框架的语言(Frame-based Languages)和产生式规则(Production Rules)。框架语言用来描述客观世界的类别、个体、属性等,多用于辅助自然语言理解;产生式规则主要用于描述逻辑结构,用于刻画过程性知识。
1980年,哲学概念“本体”(Ontology)被引入人工智能领域来刻画知识,我理解的本体大概可以说是知识的本体,一条知识的主体可以是人,可以是物,可以是抽象的概念,本体就是这些知识的本体的统称。1989年,Tim Berners-Lee在欧洲高能物理研究中心发明了万维网,人们可以通过链接把自己的文档链入其中,在万维网概念的基础上,1998年又提出了语义网(Semantic Web)的概念,与万维网不同的是,链入网络的不止是网页,还包括客观实际的实体(如人、机构、地点等)。2012年谷歌发布了基于知识图谱的搜索引擎。
知识图谱的概念最早由谷歌2012年5月17日提出,其将知识图谱定义为用于增强搜索引擎功能的辅助知识库。但在知识图谱概念问世之前,语义网络技术的研究领域早已开始。2006年,Berners-Lee提出数据链接(linked data)的思想,推广和完善URI (uniform resource identifier) , RDF (resource description framework) , OWL (Web ontology language) 等技术标准,为知识图谱提供了技术基础条件[6]。
二、 技术架构
2.1表达方式
三元组是知识图谱的一种通用表示方式,即 G =(E, R, S),其中 E 是知识库中的实体,R 是知识库中的关系,S 代表知识库中的三元组。三元组的基本形式主要包括实体1、关系、实体2和概念、属性、属性值等。实体是知识图谱中的最基本元素,不同的实体间存在不同的关系。概念主要指集合、类别、对象类型、事物的种类,例如人物、地理等;属性主要指对象可能具有的属性、特征、特性、特点以及参数,例如国籍、生日等;属性值主要指对象指定属性的值,例如中国、1988-09-08等。每个实体(概念的外延)可用一个全局唯一确定的ID来标识,每个属性-属性值对(attribute-value pair, AVP) 可用来刻画实体的内在特性,而关系可用来连接两个实体,刻画它们之间的关联[4]。
2.2逻辑结构
知识图谱在逻辑架构上分为两个层次:数据层和模式层。数据层是以事实(fact)为存储单位的图数据库,其事实的基础表达方式就是“实体-关系-实体”或者“实体-属性-属性值”。模式层存储的是经过提炼的知识,借助本体库来规范实体、关系以及实体类型和属性等之间的关系[3]。
2.3体系架构
知识图谱的体系架构分为3个部分,分别获取源数据、知识融合和知识计算与知识应用[5]。知识图谱有两种构建方式,自顶向下和自底向下。在知识图谱发展初期,知识图谱主要借助百科类网站等结构化数据源,提取本体和模式信息,加入到知识库的自顶向下方式构建数据库。现阶段知识图谱大多为公开采集数据并自动抽取资源,经过人工审核后加入到知识库中,这种则是自底向上的构建方式。
三、 知识图谱的构建
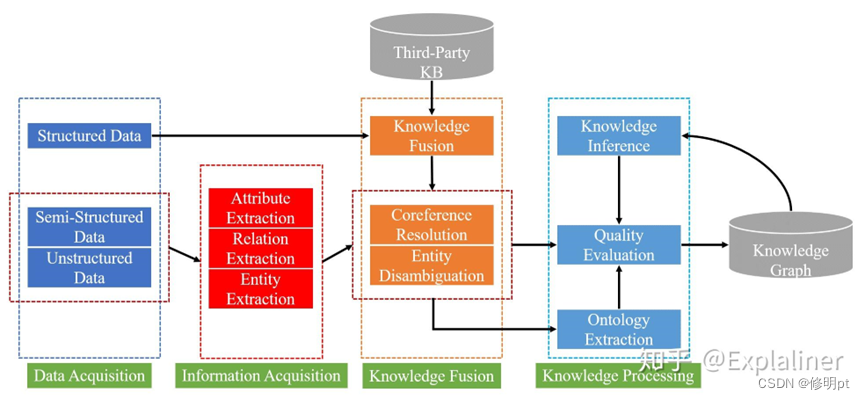
知识图谱的构建过程如上图所示,分为四个功能模块:分别是数据获取、信息获取、知识融合和知识加工。
3.1 数据获取(Data Acquisition)
知识抽取(information extraction)是构建知识图谱的第一步,为了从异构数据源中获取候选知识单元,知识抽取技术将自动从半结构化和无结构数据中抽取实体、关系以及实体属性等结构化信息[11]。
3.2 信息获取(Information Acquisition)
信息获取分为三个关键技术:实体提取、关系提取和属性提取。
3.2.1 实体提取(Entity Extraction)
实体提取,也称为命名实体识别(named entity recognition,NER),指从源数据中自动识别命名实体,这一步是信息抽取中最基础和关键的部分,因为实体抽取的准确率和召回率对后续知识获取效率和质量影响很大。
早期实体提取的准召率不够理想,但在2004年,Lin等采用字典辅助下的最大熵算法,基于Medline论文摘要的GENIA数据集使得实体抽取的准召率均超过70%[12]。2008年,Whitelaw等提出根据已知实体实例进行特征建模,利用模型从海量数据集中得到新的命名实体列表,然后再针对新实体建模,迭代地生成实体标注语料库[13]。2010年,Jain等提出一种面向开放域的无监督学习算法,事先不给实体分类,而是基于实体的语义特征从搜索日志中识别命名实体,然后采用聚类算法对识别出的实体对象进行聚类[14]。
3.2.2 关系提取(Relation Extraction)
经过实体提取, 知识库目前得到的仅是一系列离散的命名实体,。为了得到更准确的语义信息, 还需要从文本语料中提取出实体之间的关联关系, 以此形成网状的知识结构,这种技术则为关系提取技术。
3.2.2 属性提取(Attribute Extraction)
属性提取是从不同信息源中采集特定实体的属性信息。例如针对某个公众人物, 可以从网络公开信息中得到其昵称、生日、国籍、教育背景等信息。属性提取技术能够从各个数据源中汇集属性信息,更完整地表述实体属性。
3.3 知识融合(Knowledge Fusion)
通过知识提取的结果可能存在大量冗余和错误信息,形成的结构化信息也会缺乏层次性和逻辑性,因此需要对提取来的信息做知识融合,消除歧义概念、剔除冗余和错误概念,提升知识质量。
知识融合分为实体链接和知识合并两部分。实体链接(entity linking)指将在文本中抽取出来的实体链接到知识库中正确实体[15]。知识合并指从第三方知识库产品或已有数据化数据中获取知识输入,包括合并外部知识库和合并关系数据库。
3.3.1 实体链接(Entity Linking)
是指对于从文本中抽取得到的实体对象,将其链接到知识库中对应的正确实体对象的操作。实体链接主要包含两个关键技术,分别是实体消歧和共指消解。
(1)实体消歧(Entity Disambiguation)是专门用于解决同名实体产生歧义问题的技术,通过实体消歧,就可以根据当前的语境,准确建立实体链接。
(2)共指消解(Entity Resolution)主要用于解决多个指称项对应于同一实体对象的问题。利用共指消解技术,可以将这些指称项关联(合并)到正确的实体对象。
3.3.2 知识合并
在构建知识图谱时,需要从第三方知识库产品或已有结构化数据获取知识输入。
(1)合并外部知识库:例如从百度百科,维基百科等进行知识合并。
(2)合并关系数据库:知识图谱构建过程中,一个重要的高质量知识来源是企业或者机构自己的关系数据库。为了将这些结构化的历史数据融入到知识图谱中,可以采用资源描述框架(RDF)作为数据模型。这一过程被称为RDB2RDF,实质就是将关系数据库的数据转换成RDF的三元组数据。
3.4 知识加工
通过知识提取、知识融合得到一系列的基本事实表达,离结构化、网络化的知识体系仍有一段距离。因此还需要针对这些事实表达进行知识加工,包括本体构建、知识推理和质量评估。
3.4.1 本体构建(Ontology Extraction)
本体构建(ontology)指对概念建模的规范,以形式化方式明确定义概念之间的联系。在知识图谱中,本体位于模式层,用于描述概念层次体系的知识概念模版[16]。
3.4.2 知识推理(Knowledge Inference)
知识推理指从知识库中已有的实体关系数据经过计算建立新实体关联,从现有知识中发现新知识,拓展和丰富知识网络。例如已知 (乾隆, 父亲, 雍正) 和 (雍正, 父亲, 康熙) , 可以得到 (乾隆, 祖父, 康熙) 或 (康熙, 孙子, 乾隆) 。知识推理的对象除了实体关系,还包括实体的属性值、本体概念层次关系等。例如已知 (老虎, 科, 猫科) 和 (猫科, 目, 食肉目) , 可以推出 (老虎, 目, 食肉目) 。
3.4.3 质量评估(Quality Evaluation)
因为知识推理的信息基础来源于开放域的信息抽取,可能存在实体识别错误、关系抽取错误等问题,因此知识推理的质量也可能存在对应问题,需要在入知识库之前,将推理得来的知识进行质量评估。2011年,Fader采用人工标注方式对1000个句子中的实体关系三元组进行标注,并作为训练集得到逻辑斯蒂回归模型,用于对REVERB系统的信息抽取结果计算置信度。另外,谷歌的Knowledge Vault从全网范围内抽取结构化的数据信息, 并根据某一数据信息在整个抽取过程中抽取频率对该数据信息的可信度进行评分, 然后利用从可信知识库Freebase中的先验知识对已评分的可信度信息进行修正, 这一方法有效降低对数据信息正误判断的不确定性, 提高知识图谱中知识的质量。
四、 相关工具
1、 Neo4j: Neo4j是一个可扩展的图形数据库,用于存储和查询知识图谱。它提供了一组用于构建和查询知识图谱的API和工具。Neo4j还提供了一些用于可视化知识图谱的工具,例如Bloom和Neo4j Browser[7][8]。
2、 Cambridge Intelligence: Cambridge Intelligence是一家提供知识图谱可视化工具的公司。他们的工具可以帮助用户可视化和探索知识图谱,以便更好地理解和分析数据[8]。
3、 KGTK: KGTK是一个知识图谱工具包,用于导入、转换和操作知识图谱数据。它支持多种数据格式,例如Wikidata和RDF,可以帮助用户轻松地将数据添加到知识图谱中[9]。
4、 KBpedia: KBpedia是一个开源的知识图谱,将七个主要的公共知识库组合成一个集成的可计算结构。KBpedia覆盖了98%的Wikidata和几乎完整覆盖了Wikipedia4[10]。
五、典型案例
知识图谱是一种用于表示知识的图形化数据结构。它可以帮助人们更好地理解和模拟复杂的概念和关系。知识图谱的应用非常广泛,包括搜索引擎、智能问答、自然语言处理、推荐系统等。知识图谱的典型案例包括:
1、 Google 知识图谱:它是一种用于展示 Google 搜索结果的知识图谱,可以根据全球用户的搜索内容提供相关信息[17]。
2、 Wikidata 知识图谱:它是一个由维基媒体基金会维护的知识图谱,包含了大量的结构化数据[17]。
3、 DBPedia 知识图谱:它是一个由柏林自由大学维护的知识图谱,从维基百科中提取了大量的结构化数据[17]。
4、 GeoNames 知识图谱:它是一个由德国地理研究中心维护的知识图谱,包含了全球地理位置信息[17]。
5、 WordNet 知识图谱:它是一个由普林斯顿大学维护的英语词汇知识图谱,包含了大量的同义词和词汇关系[17]。
[1] An Introduction to Knowledge Graphs
[2] 知识图谱—维基百科
[3] 刘峤,李杨,段宏,刘瑶,秦志光.知识图谱构建技术综述[J].计算机研究与发展,2016,53(03):582-600.
[4] 徐增林,盛泳潘,贺丽荣,王雅芳.知识图谱技术综述[J].电子科技大学学报,2016,45(04):589-606.
[5] 张吉祥; 张祥森; 武长旭; 赵增顺. 知识图谱构建技术综述. 计算机工程. 2022, 48 (3): 23–37 [2023-03-17].
[6] 程学旗,靳小龙,王元卓,郭嘉丰,张铁赢,李国杰.大数据系统和分析技术综述[J].软件学报,2014,25(09):1889-1908.DOI:10.13328/j.cnki.jos.004674.
[7] Knowledge Graphs | Enterprise Knowledge Graph Database & Tools (neo4j.com)
[8] Knowledge graph visualization (cambridge-intelligence.com)
[9] usc-isi-i2/kgtk: Knowledge Graph Toolkit (github.com)
[10] KBpedia - Open-source Integrated Knowledge Structure
[11] Cowie, Jim; Lehnert, Wendy. Information extraction. Communications of the ACM. 1996-01, 39 (1): 80–91. ISSN 0001-0782. doi:10.1145/234173.234209.
[12] Tsai, Richard Tzong-Han; Wu, Shih-Hung; Chou, Wen-Chi; Lin, Yu-Chun; He, Ding; Hsiang, Jieh; Sung, Ting-Yi; Hsu, Wen-Lian. Various criteria in the evaluation of biomedical named entity recognition. BMC Bioinformatics. 2006-02-24, 7 (1). ISSN 1471-2105. doi:10.1186/1471-2105-7-92.
[13] Whitelaw, Casey; Kehlenbeck, Alex; Petrovic, Nemanja; Ungar, Lyle. Web-scale named entity recognition. Proceeding of the 17th ACM conference on Information and knowledge mining - CIKM '08 (New York, New York, USA: ACM Press). 2008. doi:10.1145/1458082.1458102.
[14] Jain, Alpa; Pennacchiotti, Marco. Domain-independent entity extraction from web search query logs. Proceedings of the 20th international conference companion on World wide web - WWW '11 (New York, New York, USA: ACM Press). 2011. doi:10.1145/1963192.1963225.
[15] Li, Yang; Wang, Chi; Han, Fangqiu; Han, Jiawei; Roth, Dan; Yan, Xifeng. Mining evidences for named entity disambiguation. Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining (New York, NY, USA: ACM). 2013-08-11. doi:10.1145/2487575.2487681.
[16] Wong, Wilson; Liu, Wei; Bennamoun, Mohammed. Ontology learning from text. ACM Computing Surveys. 2012-08, 44 (4): 1–36. ISSN 0360-0300. doi:10.1145/2333112.2333115.
[17] What Is a Knowledge Graph? Examples, Uses & More. | Built In


















 1167
1167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











