









概括:
BM25算法通过加入文档权值和查询权值,拓展了二元独立模型的得分函数。这种拓展是基于概率论和实验验证的,并不是一个正式的模型。BM25模型在二元独立模型的基础上,考虑了单词在查询中的权值以及单词在文档中的权值,拟合综合上述考虑的公式,并通过实验引入经验参数。
BM25的原始公式为:
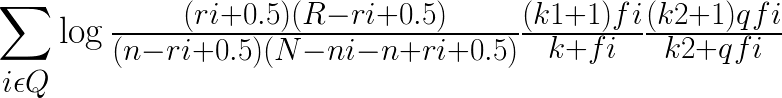
log后有三部分组成,其中,第一部分是二元独立模型的计算得分
二元独立模型介绍:
有两个假设:
假设一:二元假设
类似于布尔模型的方法,一篇文章由特征表示时,以特征“出现”和“不出现”两种情况表示,亦可以理解成特征“相关”和“不相关”。
假设二:词汇独立性假设
所谓独立性假设,是指文档里出现的单词之间没有任何关联,任一个单词在文章中的分布率不依赖于另一个单词是否出现,这个假设明显与事实不符,但是为了简化计算,很多地方需要做出独立性假设,这种假设是普遍的。
在以上两个假设的前提下,二元独立模型即可以对两个因子P(D|R)和P(D|NR)进行估算(条件概率),举个简单的例子,文档D中五个单词的出现情况如下:{1,0,1,0,1} 0表示不出现,1表示出现。用Pi表示第i个单词在相关文档中出现的概率,在已知相关文档集合的情况下,观察到文档D的概率为:
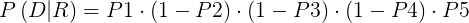
对于因子P(D|NR),用Si表示第i个单词在不相关文档中出现的概率,在以知不相关文档的情况下,观察到文档D的概率为:
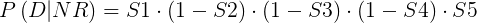
观察得:
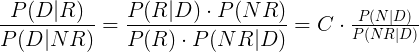
并且带入Pi,Si可得:
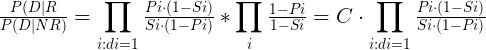
为了方便计算,对上述公式两边取log,得到:
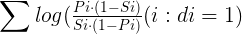
那么如何估算概率Si和Pi呢,如果给定用户查询,我们能确定哪些文档集合构成了相关文档集合,哪些文档构成了不相关文档集合,那么就可以用如下的数据对概率进行估算:

根据上表可以计算出Pi和Si的概率估值,为了避免log(0),对估值公式进行平滑操作,分子+0.5,分母+1.0
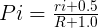
在我们不知道哪些文档相关,哪些文档不相关的情况下,将相关文档数R及包含查询词相关文档数r设为0,那么第一部分退化成:
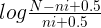
代入公式1变为:
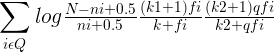
三个自由调节参数
在公式: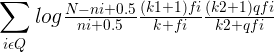
第二个组成部分是查询词在文档 D 中的权值,其中 fi代表了单词在文档 D 中的词频,k1和 K 是经验参数。第三个组成部分是查询词自身的权值,其中 qfi代表查询词在用户查询中的词频,如果查询较短小的话,这个值往往是 1,k2是经验参数在第二个计算因子中,K 因子代表了对文档长度的考虑,它用来利用文档长度归一化 tf 因子。 公式(7)所示 K 的计算公式中 ,dl 代 表 文 档 D 的 长 度 , 而 avdl 则 代 表 文 档 集 合 中所有文档的平均长度,k1和 b 是经验参数。 其中参数 b 是调节因子,极端情况下,将 b 设定为 0,则文档长度因素将不起作用,经验表明一般将 b 设定为 0.75 会获得较好的搜索效果。
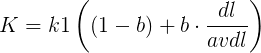
BM25 公式中包含 3 个自由调节参数 ,除了调节因子 b 外 ,还有针对词频的调节因子 k1和 k2。 k1的作用是对查询词在文档中的词频进行调节,如果将 k1设定为 0,则第二部分计算因子成了整数 1,即不考虑词频的因素,退化成了二元独立模型。 如果将 k1设定为较大值, 则第二部分计算因子基本和词频 fi保持线性增长,即放大了词频的权值,根据经验,一般将 k1设定为 1.2。调节因子 k2和 k1的作用类似,不同点在于其是针对查询词中的词频进行调节,一般将这个值设定在 0 到 1000 较大的范围内。之所以如此,是因为查询往往很短,所以不同查询词的词频都很小,词频之间差异不大,较大的调节参数数值设定范围允许对这种差异进行放大。
参考:搜索之BM25和BM25F模型,
基于 Lucene 的 BM25 模型的评分机制的研究(范晨熙 黄理灿 李雪利)














 9008
9008











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









