







目标:
针对mongodb搭建校内搜索引擎——内容查询与排序1.0进行改进
概要:
在已经存储好数据的情况下,运用BM25算法对查询的语句和网页的相关度进行相关度的计算。在实践中运用BM25算法,从1.0版本到2.0版本大大提高的查询的速度,普遍提高了1个量级,有些情况下可以优化提速两个量级。优化基于查询相关度计算,使整体运行速度加快。
实现过程:
版本2.0及思考:
在版本1.0的情况下,我的问题出在获得的url列表过大,导致计算的数目过多,并且在计算相关度时,对词语和url相关度的计算需要动态获得。解决办法是改变数据库的结构,使得词语与url的相关度可以事先计算好,静态存储然后直接调用(前提是对算法准确,不会修改,副作用是大量数据更新耗时),然后设置相应的阈值,如果词语“南京大学”在我获得的url中相关度最高是2.0,那么我选择提取相关度与“南京大学”相关且大于2.0/10(这里的阈值可以动态调整),可以大致想象,对排序前面的结果无影响(结果如此),而且大大加快运行速度。
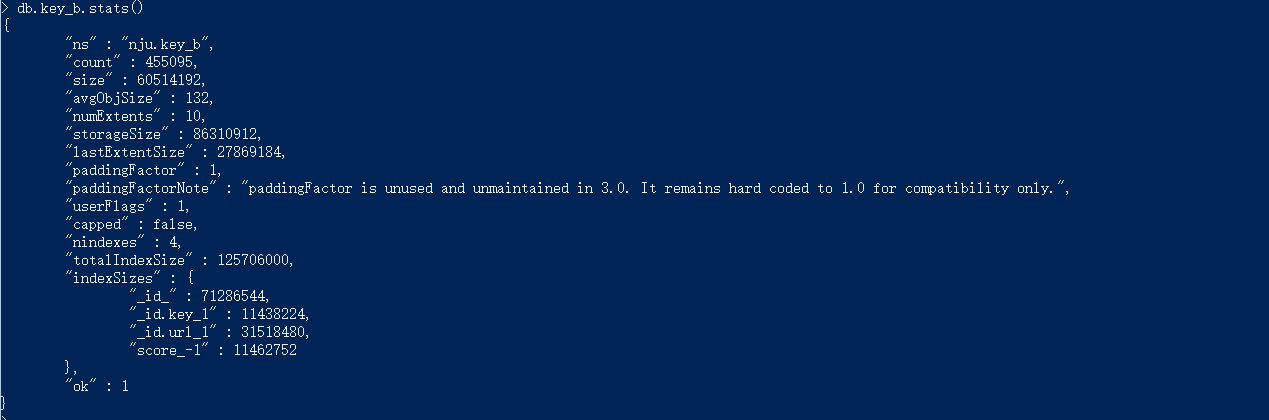
版本2.0的数据库结果如下:

复合的id 中url是链接,key是关键词,score是相关度,相对于1.0的数据库结果,将其打散,同时对url,key,score分别建立索引,副作用是更新会更慢。
数据库的情况如下:
代码如下:
import pymongo
import time
import jieba
import jieba.analyse
import sys
from functools import wraps
reload(sys)
sys.setdefaultencoding("utf-8")
setence=sys.argv[1]
connection=pymongo.MongoClient("mongodb://localhost")
db=connection.nju
key=db.key_b
def fn_timer(function): #计算时间
@wraps(function)
def function_timer(*args, **kwargs):
t0 =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1598
1598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









