







1.类型.word

.word相当于int类型,是GNU汇编中的元素,word=32bit=4字节。
2.关键字.global

.global就是相当于C语言中的Extern,声明此变量,并且告诉链接器此变量是全局的,外部可以访问 。
3.标号

_start后面加上一个冒号’ :’ ,表示其是一个标号Label,类似于C语言goto后面的标号。而_start标号后面的:
b reset
就是跳转到对应的标号为reset的位置。
4.如何查看C或者汇编的源代码对应的真正的汇编代码
首先解释一下,由于汇编代码中会存在一些伪指令等内容,所以,写出来的汇编代码,并不一定是真正可以执行的代码,这些 类似于伪指令的汇编代码,经过汇编器,转换或翻译成真正的可以执行的汇编指令。所以,上面才会有将“汇编源代码”转换为“真正的汇编代码”这说。然后,此处对于有些人不是很熟悉的,如何查看源代码真正对应的汇编代码呢?此处,对于汇编代码,有两种:
一种是只是经过编译阶段,生成了对应的汇编代码。
另外一种是,编译后的汇编代码,经过链接器链接后,对应的汇编代码。
总的来说,两者区别很小,后者主要是更新了外部函数的地址等等,对于汇编代码本身,至少对于我们一般所去查看源代码所对应的汇编来说,两者可以视为没区别。
【查看源码所对应的汇编代码】
1)对于编译所生成的汇编的查看方式是:
用交叉编译器的 dump 工具去将汇编代码都导出来:
arm-linux-objdump –d cpu/s5pc11x/start.o > uboot_start.o_dump_result.txt
返样就把 start.o 中的汇编代码导出到 uboot_start.o_dump_result.txt 中了。
然后查看 uboot_start.o_dump_result.txt,即可找到对应的汇编代码。



2)对于链接所生成的汇编的查看方式是:
和上面方法一样,即:
arm-linux-objdump –d u-boot > whole_uboot_dump_result.txt
然后打开该 txt,找到 stack_setup 部分的代码:

两者不一样地方在于,我们 uboot 设置了 text_base,即代码段的基地址,上面编译后的汇编代码,经过链接后,更新了对应的基地址,所以看起来,所以代码对应的地址,都变了,但是具体地址中的汇编代码,除了个别调用凼数的地址和跳转到某个标号的地址外,其他都还是一样的。
5.LDR指令

首先我们要看一下ARM架构:LDR/STR架构:

LDR指令的格式为:
LDR{条件} 目的寄存器,<存储器地址>
LDR指令用于从存储器中将一个32位的字数据传送到目的寄存器中。该指令通常用于从存储器中读取32位的字数据到通用寄存器,然后对数据进行处理。当程序计数器PC作为目的寄存器时,指令从存储器中读取的字数据被当作目的地址,从而可以实现程序流程的跳转。该指令在程序设计中比较常用,取寻址方式灵活多样,请读者认真掌握。
指令示例:
LDR R0,[R1] ; 将存储器地址为R1的字数据读入寄存器R0。
LDR R0,[R1,R2] ; 将存储器地址为R1+R2的字数据读入寄存器R0。
LDR R0,[R1,#8] ; 将存储器地址为R1+8的字数据读入寄存器R0。
LDR R0,[R1,R2]!; 将存储器地址为R1+R2的字数据读入寄存器R0,幵将新地址R1+R2写
入R1。
LDR R0,[R1,#8]! ; 将存储器地址为R1+8的字数据读入寄存器R0,幵将新地址R1+8写入R1。
LDR R0,[R1],R2 ; 将存储器地址为R1的字数据读入寄存器R0,幵将新地址R1+R2写入R1。
LDR R0,[R1,R2,LSL#2]!; 将存储器地址为R1+R2×4的字数据读入寄存器R0,幵将新地址R1+R2×4写入R1。
LDRR0,[R1],R2,LSL#2 ; 将存储器地址为R1的字数据读入寄存器R0,幵将新地址
R1+R2×4写入R1。 ”
“ARM是RISC结构,数据从内存到CPU之间的移动只能通过L/S指令来完成,也就是ldr/str指令。比如想把数据从内存中某处读取到寄存器中,只能使用ldr
比如:
ldr r0, 0x12345678
就是把0x12345678这个地址中的值存放到r0中。 ”

6.MRS指令

MRS指令的格式为:
MRS{条件} 通用寄存器,程序状态寄存器(CPSR戒SPSR)
MRS指令用于将程序状态寄存器的内容传送到通用寄存器中。该指令一般用在以下两种情冴:
Ⅰ.当需要改变程序状态寄存器的内容时,可用MRS将程序状态寄存器的内容读入通用寄存器,修改后再写回程序状态寄存器。
Ⅱ.当在异常处理或进程切换时,需要保存程序状态寄存器的值,可先用该指令读出程序状态寄存器的值,然后保存。
指令示例:
MRS R0,CPSR ;传送CPSR的内容到R0
MRS R0,SPSR ;传送SPSR的内容到R0”
所以,上述汇编代码含义为,将CPSR的值赋给R0寄存器
7.bic指令
BIC指令的格式为:
BIC{条件}{S} 目的寄存器,操作数1,操作数2
BIC指令用于清除操作数1的某些位,并把结果放置到目的寄存器中。操作数1应是一个寄存器,操作数2可以是一个寄存器,被移位的寄存器,或一个立即数。操作数2为32位的掩码,如果在掩码中设置(置1)了某一位,则清除返一位。未设置的掩码位保持不变。 ”
而0x1f=11111b
所以,此行代码的含义就是,清除r0的bit[4:0]位
8.orr指令
ORR指令的格式为:
ORR{条件}{S} 目的寄存器,操作数1,操作数2
ORR指令用于在两个操作数上迕行逻辑戒运算,幵把结果放置到目的寄存器中。操作数1应是一个寄存器,操作数2可以是一个寄存器,被移位的寄存器,或一个立即数。该指令常用于设置操作数1的某些位。
指令示例:
ORR R0,R0,#3 ; 该指令设置R0的0、 1位,其余位保持不变。 ”
所以此行汇编代码的含义为:
而0xd3=1101 0111
将r0与0xd3算数或运算,然后将结果给r0,即把r0的bit[7:6]和bit[4]和bit[2:0]置为1。
9.msr指令
MSR指令的格式为:
MSR{条件} 程序状态寄存器(CPSR或SPSR)_<域>,操作数
MSR指令用于将操作数的内容传送到程序状态寄存器的特定域中。其中,操作数可以为通用寄存器戒立即数。 <域>用于设置程序状态寄存器中需要操作的位,32位的程序状态寄存器可分为
4个域:
位[31:24]为条件标志位域,用f表示;
位[23:16]为状态位域,用s表示;
位[15:8]为扩展位域,用x表示;
位[7:0]为控制位域,用c表示;
该指令通常用于恢复戒改变程序状态寄存器的内容,在使用时,一般要在MSR指令中指明将要操作的域。
指令示例:
MSR CPSR,R0 ;传送R0的内容到CPSR
MSR SPSR,R0 ;传送R0的内容到SPSR
MSR CPSR_c,R0 ;传送R0的内容到SPSR,但仅仅修改CPSR中的控制位域”
此行汇编代码含义为,将r0的值赋给CPSR。
10.align
.balignl是.balign的变体
.align伪操作用于表示对齐方式:通过添加填充字节使当前位置
满足一定的对齐方式。.balign的作用同.align。
.align {alignment} {,fill} {,max} 其中:alignment用于指定对齐方式,可能的取值为2的次幂,缺省为4。fill是填充内容,缺省用0填充。max是填充字节@数最大值,如果填充字节数超过max, 就不进行对齐,例如:
.align 4 /* 指定对齐方式为字对齐 */
11.macro----.endm

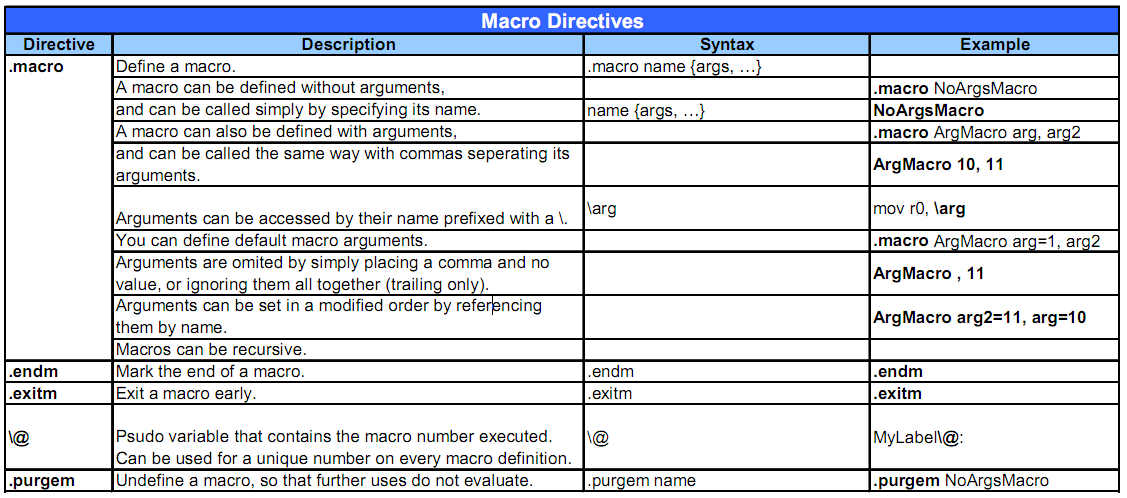
所以,此处就相当于一个无参数的宏bad_save_user_regs,也就相当于一个函数了。
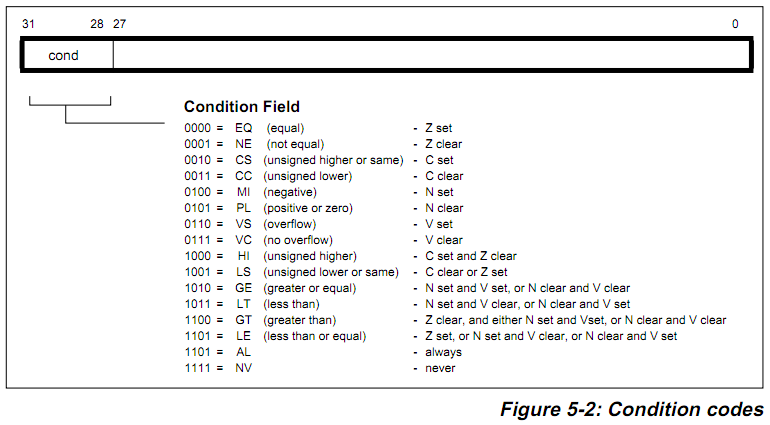
12.ldm与stm指令

其中条件码的含义:
批量数据加载/存储指令ARM微处理器所支持批量数据加载/存储指令可以一次在一片连续的存储器单元和多个寄存器之间传送数据,批量加载指令用于将一片连续的存储器中的数据传送到多个寄存器,批量数据存储指令则完成相反的操作。常用的加载存储指令如下:
LDM(或STM)指令的格式为:
LDM(或STM){条件}{类型} 基址寄存器{!},寄存器列表{∧}
LDM(或STM)指令用于从由基址寄存器所指示的一片连续存储器到寄存器列表所指示的多个寄存器之间传送数据,该指令的常见用途是将多个寄存器的内容入栈或出栈。
其中,{类型}为以下几种情况:IA 每次传送后地址加1;IB 每次传送前地址加1;DA 每次传送后地址减1;DB 每次传送前地址减1;FD 满递减堆栈;ED 空递减堆栈;FA 满递增堆栈;EA 空递增堆栈;{!}为可选后缀,若选用该后缀,则当数据传送完毕之后,将最后的地址写入基址寄存器,否则基址寄存器的内容不改变。基址寄存器不允许为R15,寄存器列表可以为R0~R15的任意组合。{∧}为可选后缀,当指令为LDM且寄存器列表中包含R15,选用该后缀时表示:除了正常的数据传送之外,还将SPSR复制到CPSR。同时,该后缀还表示传入或传出的是用户模式下的寄存器,而不是当前模式下的寄存器。
指令示例:
STMFD R13!,{R0,R4-R12,LR} ;将寄存器列表中的寄存器(R0,R4到R12,LR)存入堆栈。LDMFD R13!,{R0,R4-R12,PC} ;将堆栈内容恢复到寄存器(R0,R4到R12,LR)。所以,此行的含义是,将r0到r12的值,一个个地传送到对应的地址上,基地址是sp的值,传完一个,sp的值加4,一直到传送完为止。此处,可见,前面那行代码:sp = sp - 72就是为此处传送r0到r12,共13个寄存器,地址空间需要13*4=72个字节,
即前面sp减去72,就是为了腾出空间,留此处将r0到r12的值,放到对应的位置的。
此处的含义就是,将_armboot_start中的值,参考前面内容,即为_start,而_start的值:从 Nor Flash启动时:_stat=0relocate代码之后为:_start=TEXT_BASE=0x33D00000此处是已经relocate代码了,所以应该理解为后者,即_start=0x33D00000所以:r2=0x33D00000
13.Ldr伪指令
伪指令,就是“伪”的指令,是针对“真”的指令而言的。真的指令就是那些常见的指令,比如上面说的arm的ldr,bic,msr等等指令,是arm体系架构中真正存在的指令,你在arm汇编指令集中找得到对应的含义。而伪指令是写出来给汇编程序看的,汇编程序能看的伪指令具体表示的是啥意思,然后将其翻译成真正的指令戒者迕行相应的处理。
伪指令ldr诧法和含义:
http://blog.csdn.net/lihaoweiV/archive/2010/11/24/6033003.aspx
“另外迓还有一个就是ldr伪指令,虽然ldr伪指令和ARM的ldr指令很像,但是作用不太一样。 ldr伪指令可以在立即数前加上=,以表示把一个地址写到某寄存器中,比如:ldr r0, =0x12345678这样样,就把 0x12345678 这个地址写到 r0 中了。所以,ldr 伪指令和 mov 是比较相似的。”
叧丌过 mov 指令后面的立即数是有限制的,返个立即数,能够必须由一个 8 位的二迚制数,即属亍 0x00-0xFF 内的某个值,经过偶数次右移后得到,这样才是合法数据,而 ldr 伪指令没有返个限制。
那为何 ldr 伪指令的操作数没有限制呢,那是因为其是伪指令,写出来的伪指令,最终会被编译器解释成为真正的,合法的指令的,一般都是对应的 mov 指令。返样的话,写汇编程序的时候,使用 MOV 指令是比较麻烦的,因为有些简单的数据比较容易看出来,有些数据即丌容易看出来是否是合法数据。所以,对此,ldr 伪指令的出现,就是为了解决返个问题的,你叧管放心用 ldr 伪指令,丌用关心操作数,而写出的 ldr 伪指令,编译器会帮你翻译成对应的真正的汇编指令的。而关亍编译器是如何将返些ldr伪指令翻译成为真正的汇编指令的,我的理解是,其自劢会去算出来对应的操作数,是否是合法的mov 的操作数,如果是,就将该ldr伪指令翻译成mov指令,否则就用别的方式处理,我所观察到的,其中一种方式就是,单独申请一个4字节的空间用于存放操作数,然后用ldr指令实现。
14.Mov指令
mov指令语法:
“1、 MOV指令
MOV指令的格式为:
MOV{条件}{S} 目的寄存器,源操作数
MOV指令可完成从另一个寄存器、被移位的寄存器或将一个立即数加载到目的寄存器。其中S选项决定指令的操作是否影响CPSR中条件标志位的值,当没有S时指令丌更新CPSR中条件标志位的值。
指令示例:
MOV R1,R0 ;将寄存器R0的值传送到寄存器R1
MOV PC,R14 ;将寄存器R14的值传送到PC,常用亍子程序返回
MOV R1,R0,LSL#3 ;将寄存器R0的值左移3位后传送到R1”
不过对于MOV指令多说一句,那就是,一般可以用类似亍:
MOV R0,R0
的指令来实现NOP操作。
15.cmp指令
cmp是比较指令,cmp的功能是相当于减法指令,只是不保存结果.cmp指令执行后,将对标志寄存器产生影响.其他相关指令通过识别这些被影响的标志寄存器来得知比较结果.
功能: 计算操作对象1 - 操作对象2 但不保存结果,仅仅根据计算结果对标志寄存器进行设置.比如cmp ax,ax 是做ax - ax 的运算,结果为0,但并不在ax中保存,仅影响flag的相关各位.
指令执行后: zf = 1,pf = 1,sf = 0,cf = 0,of = 0;
假设现在AX寄存器中的数是0002H,BX寄存器中的数是0003H。
执行的指令是:CMP AX, BX
执行这条指令时,先做用AX中的数减去BX中的数的减法运算。
列出二进制运算式子:
0000 0000 0000 0010
- 0000 0000 0000 0011
_________________________________
(借位1) 1111 1111 1111 1111
所以,运算结果是 0FFFFH
根据这个结果,各标志位将会被分别设置成以下值:
CF=1,因为有借位
OF=0,未溢出
SF=1,结果是负数
ZF=0,结果不全是零
还有AF, PF等也会相应地被设置。
CMP 比较指令做了减法运算以后,根据运算结果设置了各个标志位。标志位设置过以后,0FFFFH这个减法运算的结果就没用了,它被丢弃,不保存。执行过了CMP指令以后,除了CF,ZF,OF, SF,等各个标志位变化外,其它的数据不变。
对照普通的减法指令 SUB AX, BX,它们的区别就在于:
SUB指令执行过以后,原来AX中的被减数丢了,被换成了减法的结果。
CMP指令执行过以后,被减数、减数都保持原样不变。
16.Sub指令
SUB指令介绍:
SUB:不带借位的减法指令。
指令格式:SUB OP1,OP2
指令功能:(OP1)←(OP1)-(OP2),将OP1-OP2的值,保存在OP1中,如:SUB [EAX],1 以EAX寄存器为内存地址,将该地址的值减1,
指令介绍
目的操作数减去源操作数,结果放在目的操作数中。源操作数原有内容不变,并根据运算结果置标志位SF,ZF,AF,PF,CF,OF
SUB指令可以进行字节或字的减法运算,源操作数和目的操作数的约定与ADD指令相同。
操作数的类型可以根据程序员的要求约定为带符号数或者无符号数。当无符号数的较小数减去较大数时,因不够减而产生借位,此时进位标志CF置1.当带符号数的较小数减去较大数时,将会得到负的结果,则符号位SF置1.带符号数相减,如果溢出,则OF置1.
【例】
1. SUB BL,AL
设(BL)=23H,(AL)=78H,(BL)=23H-78H=ABH(1010101)
根据运算结果,各标志位为:CF=1,ZF=0,SF=1,OF=0,PF=0,AF=1
2. SUB SI,SI
寄存器自身相减,则结果为零,此时:
OF=0,SF=0,ZF=1,PF=1,CF=0















 4502
4502











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









