







1 Introduction
两点contributions:
- We identified batch normalization and ReLU6 are the major root causes of quantization loss for MobileNetV1
- We proposed a quantization-friendly separable convolution, and empirically proved its effectiveness based on MobileNetV1 in both the float pipeline and the fixed-point pipeline
2 Quantization Scheme and Loss Analysis
2.1 TensorFlow 8-bit Quantization Scheme

2.2 Metric for Quantization Loss
量化引入了5种误差
- input quantization loss,
- weight quantization loss,
- runtime saturation loss,
- activation re-quantization loss,
- and possible clipping loss for certain non-linear operation
引入评价指标--Signal-to-Quantization-Noise Ratio (SQNR)
![]()
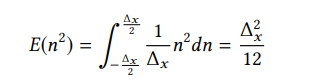
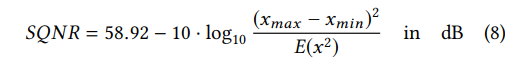
x: 信号 n:误差
SQNR与x的数据分布有很大关系,减小x的量化范围,提升x的能量可以SQNR(其实就是均匀分布的输入最好量化啊...)
2.3 Quantization Loss Analysis on MobileNetV1
2.3.1 BatchNorm in Depthwise Convolution Layer
先看batchnorm,可以如下表达

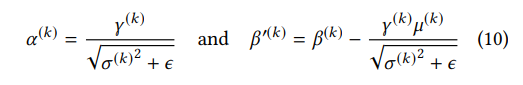
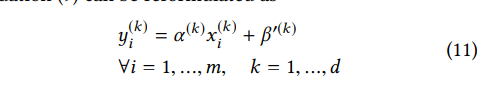
因为batchnorm是在channel维度做的,DW conv也是在channel维度。但是量化是在全部通道上做的,离群点很容易把数据分布带偏。比如下图,32个通道中有6个离群点,这6个离群点大大增加了量化范围,因为没有correlation channel的信息,DW conv很有可能造成在一些channel的输出是0,那么这些channel的方差也是0,根据式(10),会得到一个很大的α (k),过大的α (k)会损害较小α (k)量化后的表达。所以作者去掉了DW CONV后的BN和RELU6

为了展示每一层量化损失,画图

2.3.2 ReLU6 or ReLU
上图还能证明relu比relu6更适合量化。还是这个式子,来解释为什么relu比relu6好,因为relu6会截断信号,使得信号的能量减小。虽然http://www.cs.utoronto.ca/ kriz/conv-cifar10-aug2010.pdf证明relu6可以让模型更好的学习到稀疏特征,但会使得模型不易量化。
2.3.3 L2 Regularization on Weights
更小的weight更接近均匀分布,适合量化
4 Experimental Results
















 2372
2372











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









