







在数据挖掘比赛中,很重要的一个技巧就是要确定训练集与测试集特征是否同分布,这也是机器学习的一个很重要的假设。但很多时候我们知道这个道理,却很难有方法来保证数据同分布。除了KS检验、overlap rate、KL散度、KDE核密度估计外,对抗验证Adversarial validation是利用机器学习模型去检测分布是否一致
1. KS检验
KS是一种非参数检验方法,可以在不知道数据具体分布的情况下检验两个数据分布是否一致。当然这样方便的代价就是当检验的数据分布符合特定的分布事,KS检验的灵敏度没有相应的检验来的高。在样本量比较小的时候,KS检验作为非参数检验在分析两组数据之间是否不同时相当常用。
举个例子,对于数据集 {1.26, 0.34, 0.70, 1.75, 50.57, 1.55, 0.08, 0.42, 0.50, 3.20, 0.15, 0.49, 0.95, 0.24, 1.37, 0.17, 6.98, 0.10, 0.94, 0.38},先对其排序为 {0.08, 0.10, 0.15, 0.17, 0.24, 0.34, 0.38, 0.42, 0.49, 0.50, 0.70, 0.94, 0.95, 1.26, 1.37, 1.55, 1.75, 3.20, 6.98, 50.57}。其中比0.24小的一共有4个,占数据集的 1/5,所以0.24的累积分布值是0.2,依次类推我们可以画出累积分布图。
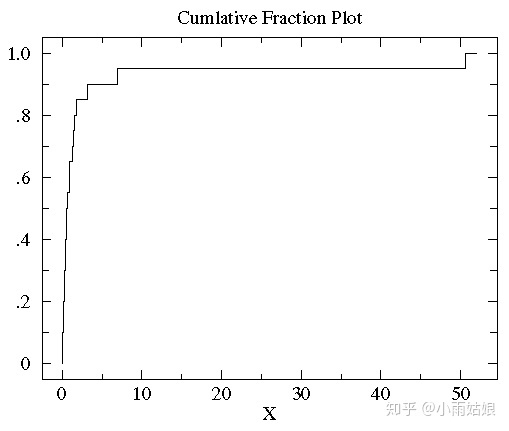
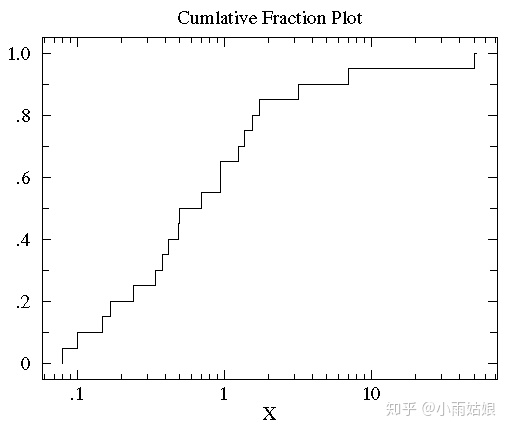
对于累积分布图取Log变换
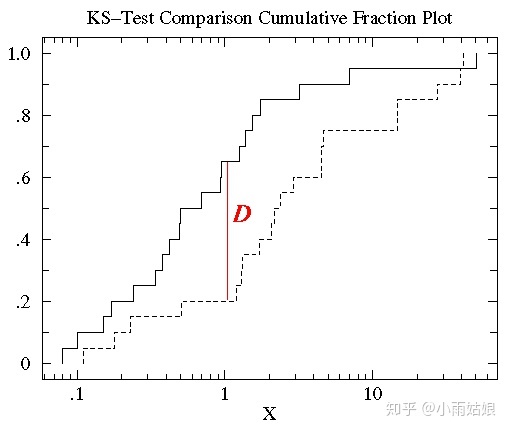
通过两个数据的累积分布图直接最大垂直距离描述两数据的差异
实际操作可以直接调用Python scipy库中封装好的函数
from scipy.stats import ks_2samp
ks_2samp(train[col],test[col]).pvalue
ks检验一般返回两个值:D和p值
其中D表示两个分布之间的最大距离,所以D越小,因为这两个分布的差距越小,分布也就越一致
p值,也就是假设检验里面的p值,那么原假设是什么呢,原假设是“待检验的两个分布式同分布”,如果p值大于0.05(当然,你也可以选择0.01或者0.10,这都取决于你的要求),那么就不能拒绝原假设。所以p越大,越不能拒绝原假设,两个分布越是同分布.
从以上可以看出,D值小和p值大,并不矛盾
2. overlap rate
https://zhuanlan.zhihu.com/p/82435050
对于类别型变量检验同分布,我们可以对其进行编码然后KS检测,或者选择通过特征重合率来进行检测,通过特征重合率检测的思想是检测训练集特征在测试集中出现的比率,举个例子:
训练集特征:[猫,狗,狗,猫,狗,狗,狗,猫]
测试集特征:[猫,猫,鱼,猪,鱼,鱼,猪,猪]
即使该特征在训练集表现很好,但在测试集上的用处并不大,因为重合率仅有1/4,反而会导致过拟合或者模型忽略到其他更有用的特征。
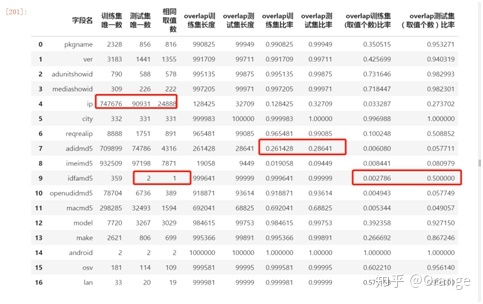
这个信息非常重要,通过这个观察取值个数,取值交叉,我么去判断一个特征的有用性,上述表可以看出
1- idfamd5极低特征交叉数几乎就是一个垃圾的特征了,因为训练集邮359个取值,而测试集则只有2个取值,训练集合测试集相同的取值只有一个而这个取值是empty。。。等于说两者没有交叉的取值,所以这个基本就是一个废特征;
2- adidmd5极低特征交叉率几乎又是一个垃圾的特征了,20%多的训练测试分别交叉,这样的类别特征如果不处理绝对有猫腻,要么过拟合,要么过拟合,有什么处理?要么不交叉的全部取nan,毕竟树模型在分裂的时候一般是往最优方向去分裂的;但是…nan过多,每次都最优分裂,可能也会过拟合?所以另一种可能方式是赋值 ‘-9999’,这个作用则是用来避免每个样本都去单独对待,而是在同一个维度上这个特征这些取值有了统一的特质;
3. KL散度
https://www.jianshu.com/p/43318a3dc715
KL 散度是一种衡量两个概率分布的匹配程度的指标,两个分布差异越大,KL散度越大。注意如果要查看测试集特征是否与训练集相同,P代表训练集,Q代表测试集,这个公式对于P和Q并不是对称的。
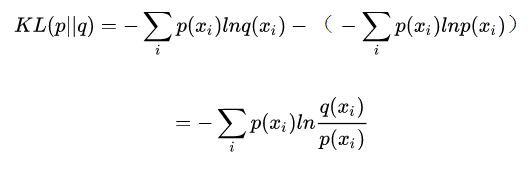
4. KDE 核密度估计
https://blog.csdn.net/pipisorry/article/details/53635895
KDE核密度估计,看起来好像是统计学里面一个高端的非参数估计方法。大概就是通过一个核函数把一个频率分布直方图搞成平滑的了。
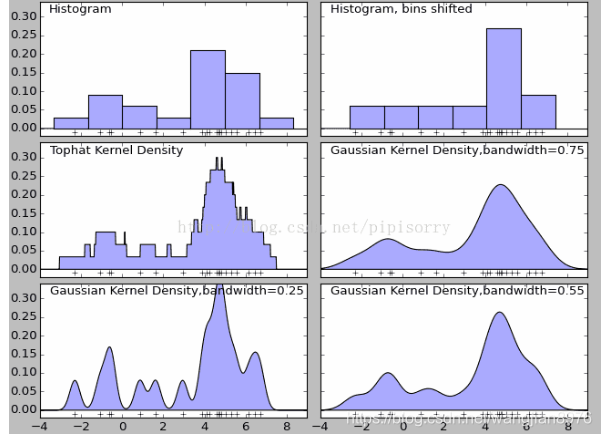
一般都是这么用的,从seaborn中找到KDE plot这个方法,然后把测试集和训练集的特征画出来,看看图像不像,不像的直接扔了就行。
>>> import numpy as np; np.random.seed(10)
>>> import seaborn as sns; sns.set(color_codes=True)
>>> mean, cov = [0, 2], [(1, .5), (.5, 1)]
>>> x, y = np.random.multivariate_normal(mean, cov, size=50).T
>>> ax = sns.kdeplot(x)
5. 对抗验证Adversarial validation
对抗验证是模型验证的一种,通常,我们在训练模型的时候,不会将所有的数据用于训练,而是留出部分数据(验证集)用于评估模型的效果,这样做可以一定程度减少过拟合,经常会使用的到的交叉验证有:留出法 (holdout cross validation),k 折交叉验证(k-fold cross validation)。对其中的留出法作简单举例说明:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
以上为留出法,留出20%作为验证集。
什么是对抗验证?对抗验证是什么?怎么用?如何实现?
对抗验证,通常是在发现在训练集上模型表现得非常好,AUC非常高,此时如果采用k-fold交叉验证,模型在验证集上却表现非常糟糕。一种可能性就是训练集与测试集相差非常大。就如同许多数据科学竞赛都面临着测试集与训练集明显不同的问题(这违反了“相同分布”的假设)。因此很难建立一个具有代表性的验证集。
对抗验证,选择与测试样本最相似的训练样本,并将其作为验证集。这个方法的核心思想是训练一个分类器来区分训练/测试样本。相反,理想情况下,来自同一分布的训练和测试样本,验证误差就可以很好地估计测试误差,分类器就可以很好地泛化到未发现的测试样本。
此时,你心里肯定有很多疑问,比如,这样选择的话,那岂不是过度拟合测试集了吗?
对抗验证在训练集和测试集分布“不同”的情况下,它做的选择是,宁可过拟合和测试集最相似的训练样本(用于验证),也不去过拟合那些与测试集相去甚远的样本,通过这个方法降低模型的置信度,从而降低AUC。
这么做会达到什么目的呢?这样做的结果是,我模型训练的效果可以与模型测试的效果相匹配,降低模型训练表现特别好,而测试时一团糟的情况。
实现步骤:
1.合并训练集和测试集,并且将训练集和测试集的标签分别设置为0和1;
2.构建一个分类器(CNN,RNN或者决策树等),用于学习the different between testing and training data;
3.观察AUC,理想的状况是在0.5左右(0.5说明训练集与测试集基本是同分布的,AUC越高说明训练集与测试集有很大分别)。
4.找到训练集中与测试集最相似的样本(most resemble data),作为验证集,其余的作为训练集;
5.构建一个用于训练的模型(CNN,RNN或者决策树等);
由此,我们用训练好的二分类模型对训练集进行预测,然后输出预测概率,根据这个概率为训练集设置权重(概率越接近1代表训练集分布更接近测试集),这样就可以强行过拟合到测试集上!对于非线上测试型的数据挖掘比赛应该会有比较大的提升!
Kaggle Adversarial validation
Adversarial Validation example for VSB Power Line Fault Detection
fastml














 993
993











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









