






01
—
注意事项
1.训练、验证、测试集必须分布相同,比如收集如下几个区域的用户数据,在分割训练、验证、测试集的时候不能将US 、UK 用于训练,India 验证,China 测试,这样的话由于各个地区分布不同,产生的结果也不好。更明智的做法是每个地区的数据单独分割训练、验证、测试集,保证数据同一分布。

3.什么时候改变验证集、测试集和性能度量指标?
1)实际应用的数据分布与验证/测试集分布不同
假设初始验证/ 测试集主要包含的是成年猫的图片。在猫的APP 中,发现用户上传更多的是小猫的图像。因此,验证/ 测试集分布并不能代表实际应用的数据分布。在这种情况下,需要验证/ 测试集以使其更具有代表性。2 )验证集过拟合 因为在训练过程中需要在验证集上重复评估,如果发现验证集性能远远优于测试集性能,则表明已经过拟合到验证集了,这时就需要获得一个新的验证集合。所以不要用测试集做关于算法的任何决定,包括是否回滚到前一周的系统。如果这样做,将会过拟合到测试集,测试集也就不能用来对系统性能进行完全无偏的估计。3 )度量标准衡量的东西不是项目需要优化的 假设在猫应用程序中,度量标准是分类准确率。根据该度量标准,分类器A 性能优于分类器B 。但是测试两种算法的过程中,发现分类器A 偶尔会将小黄图误分为猫图像。即使分类器A 更准确,偶尔错分小黄图会留下比较糟的印象,这意味着分类器A 的性能是不可接受的。这时需要改变评估标准。例如,可以对误分色情图片加重惩罚。
02
—
训练、验证、测试集分割代码实现
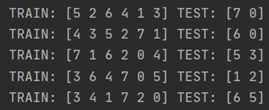
训练、测试集的划分:from sklearn.model_selection import StratifiedShuffleSplitimport numpy as npX = np.array([[1, 2], [3, 4], [1, 2], [3, 4], [1, 2],[3, 4], [1, 2], [3, 4]]) #训练数据集8*2y = np.array([0, 0, 1, 1,0,0,1,1]) #类别数据集8*1ss=StratifiedShuffleSplit(n_splits=5,test_size=0.3,train_size=0.7,random_state=0) #分成5组,测试比例为0.3,训练比例是0.7for train_index, test_index in ss.split(X, y): print("TRAIN:", train_index, "TEST:", test_index) #获得索引值 X_train, X_test = X[train_index], X[test_index] y_train, y_test = y[train_index], y[test_index] 输出:
Reference
深度学习课程 --吴恩达














 9378
9378











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









