






 本文介绍了如何使用爬虫技术从巨潮资讯网上获取信息,重点在于正则表达式的非贪婪匹配应用,涉及re库、sub函数、字符串处理以及selenium webdriver的使用。
本文介绍了如何使用爬虫技术从巨潮资讯网上获取信息,重点在于正则表达式的非贪婪匹配应用,涉及re库、sub函数、字符串处理以及selenium webdriver的使用。
今天分享一下对巨潮资讯网一些信息的爬取是如何做的,首先选择这个网站是因为网站内容还是相对来说比较简单的,主要是页面的元素比较容易定位的。主要用到的知识点还是用到“非贪婪匹配符号”的应用。
核心:
正则库:import re
非贪婪匹配:.*?
正则函数:sub()
符号处理:strip()、split()
其他库:selenium webdriver(是从浏览器操作的,这个是必须要有的)
实现过程如下:
from selenium import webdriver
import re
def getContents(keyword):
browser = webdriver.Chrome()
url = 'http://www.cninfo.com.cn/new/fulltextSearch?notautosubmit=&keyWord=' + keyword
browser.get(url)
data = browser.page_source
browser.quit()
# 正则表达式处理
p_title = '<span title="" class="r-title">(.*?)</span>'
p_href = '<a target="_blank" href="(.*?)" data-id='
p_date = '<span class="time">(.*?)</span>'
title = re.findall(p_title, data)
href = re.findall(p_href, data)
date = re.findall(p_date, data, re.S) # 注意(.*?)中有换行(/n),而常规的(.*?)匹配不了换行,所以需要加上re.S取消换行的影响
for i in range(len(title)):
title[i] = re.sub(r'<.*?>', '', title[i])
href[i] = 'http://www.cninfo.com.cn' + href[i]
href[i] = re.sub('amp;', '', href[i])
date[i] = date[i].strip() # 清除空格和换行符
date[i] = date[i].split(' ')[0] # 只取“年月日”信息,不用“时分秒”信息
print(str(i + 1) + '.' + title[i] + ' - ' + date[i])
print(href[i])
keywords = ['理财', '现金管理', '金融风暴'] #关键字可以是多种形式的
for i in keywords:
getContents(i)
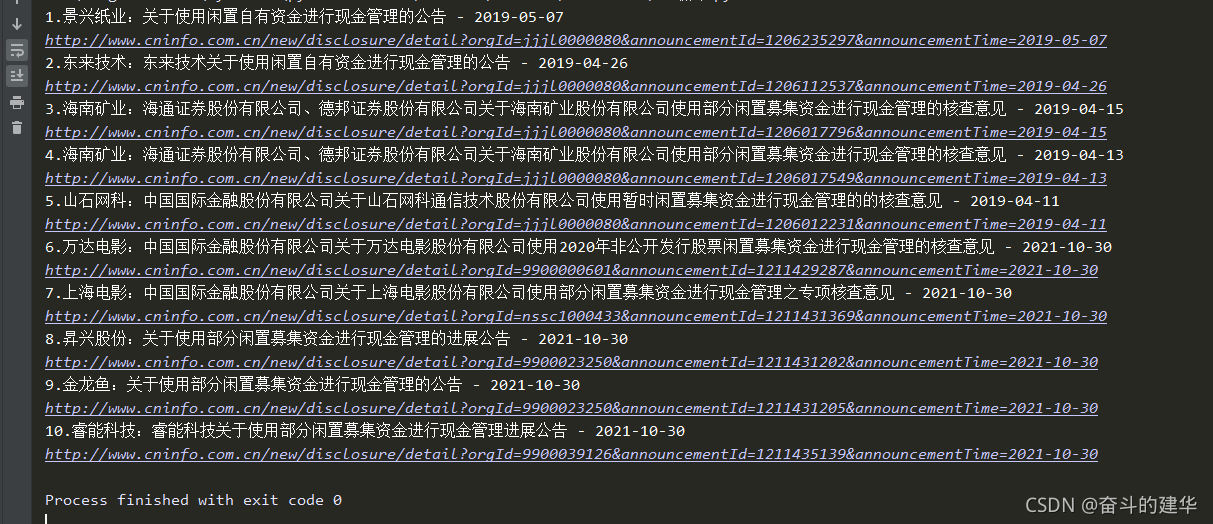
效果:


















 1624
1624

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











