







 本文介绍了如何使用Scrapy爬取微博内容和评论,并结合Redis实现重复内容的过滤。通过分析微博移动端URL的规律,构建爬虫抓取数据,然后利用Redis的Set集合特性进行去重,确保数据的唯一性。
本文介绍了如何使用Scrapy爬取微博内容和评论,并结合Redis实现重复内容的过滤。通过分析微博移动端URL的规律,构建爬虫抓取数据,然后利用Redis的Set集合特性进行去重,确保数据的唯一性。
工作原因需要爬取微博上相关微博内容以及评论。直接scrapy上手,发现有部分重复的内容出现。(标题重复,内容重复,但是url不重复)
1.scrapy爬取微博内容
为了降低爬取难度,直接爬取微博的移动端:(电脑访问到移动版本微博,之后F12调出控制台来操作)
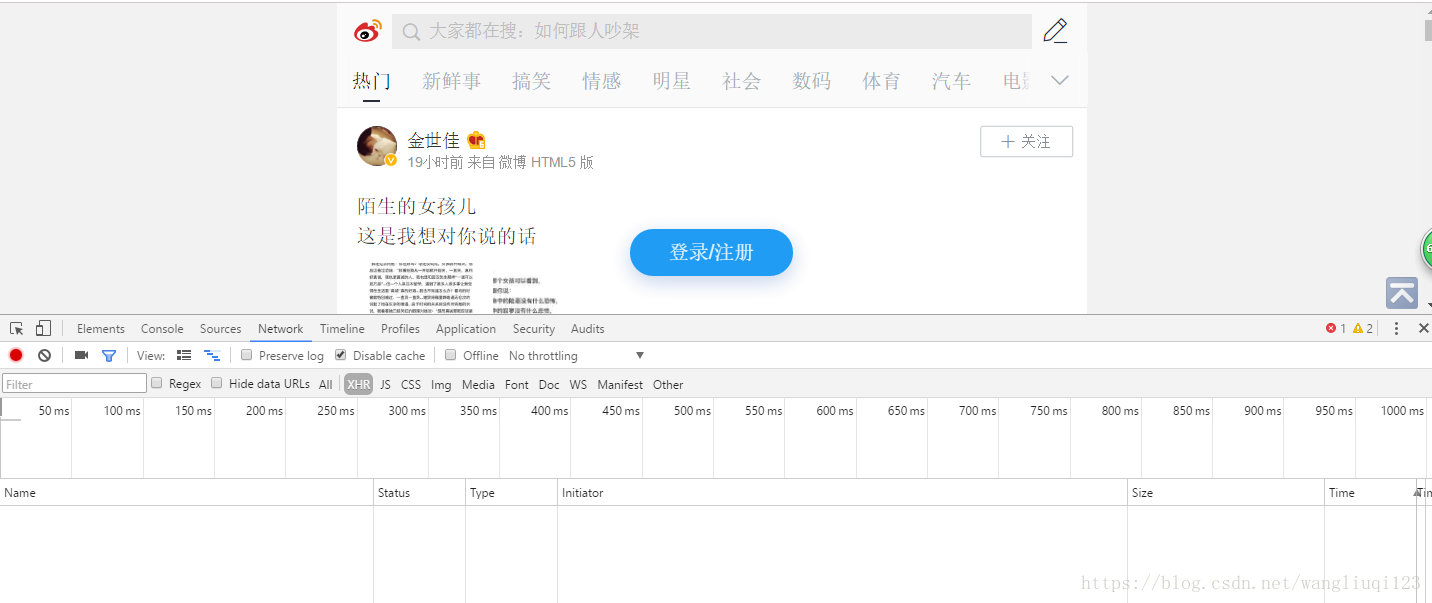
点击搜索栏:输入相关搜索关键词:
可以看到微博的开始搜索URL为:https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E8%8C%83%E5%86%B0%E5%86%B0&page_type=searchall
我们要搜索的“范冰冰” 其实做了URL编码:
class SinaspiderSpider(scrapy.Spider):
name = 'weibospider'
allowed_domains = ['m.weibo.cn']
start_urls = ['https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E8%8C%83%E5%86%B0%E5%86%B0&page_type=searchall']
Referer = {"Referer": "https://m.weibo.cn/p/searchall?containerid=100103type%3D1%26q%3D"+quote("范冰冰")}
def start_requests(self):
yield Request(url="https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D"+quote("范冰冰")+"&page_type=searchall&page=1",headers=self.Referer,meta={"page":1,"keyword":"范冰冰"})
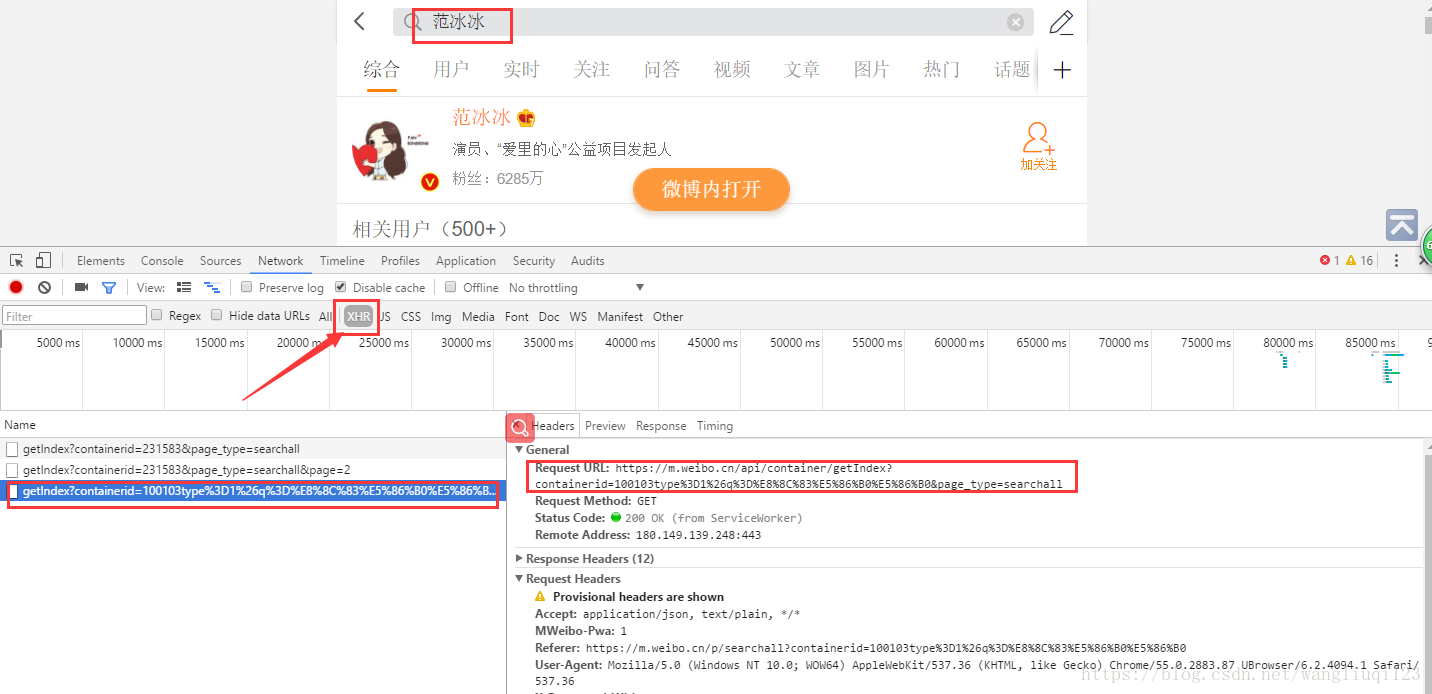
之后我们滚动往下拉发现url是有规律的:
https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E8%8C%83%E5%86%B0%E5%86%B0&page_type=searchall&page=2
https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E8%8C%83%E5%86%B0%E5%86%B0&page_type=searchall&page=3
https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E8%8C%83%E5%86%B0%E5%86%B0&page_type=searchall&page=4
https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E8%8C%83%E5%86%B0%E5%86%B0&page_type=searchall&page=5
https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E8%8C%83%E5%86%B0%E5%86%B0&page_type=searchall&page=6
https://m.weibo.cn/api/container/getIndex?containerid=100103type%3D1%26q%3D%E8%8C%83%E5%86%B0%E5%86%B0&page_type=searchall&page=7在原来的基础上新增了一个参数“&page=2” 这些参数从哪里来的呢?我们如何判断多少页的时候就没有了呢?
打开我们最开始的那条URL:
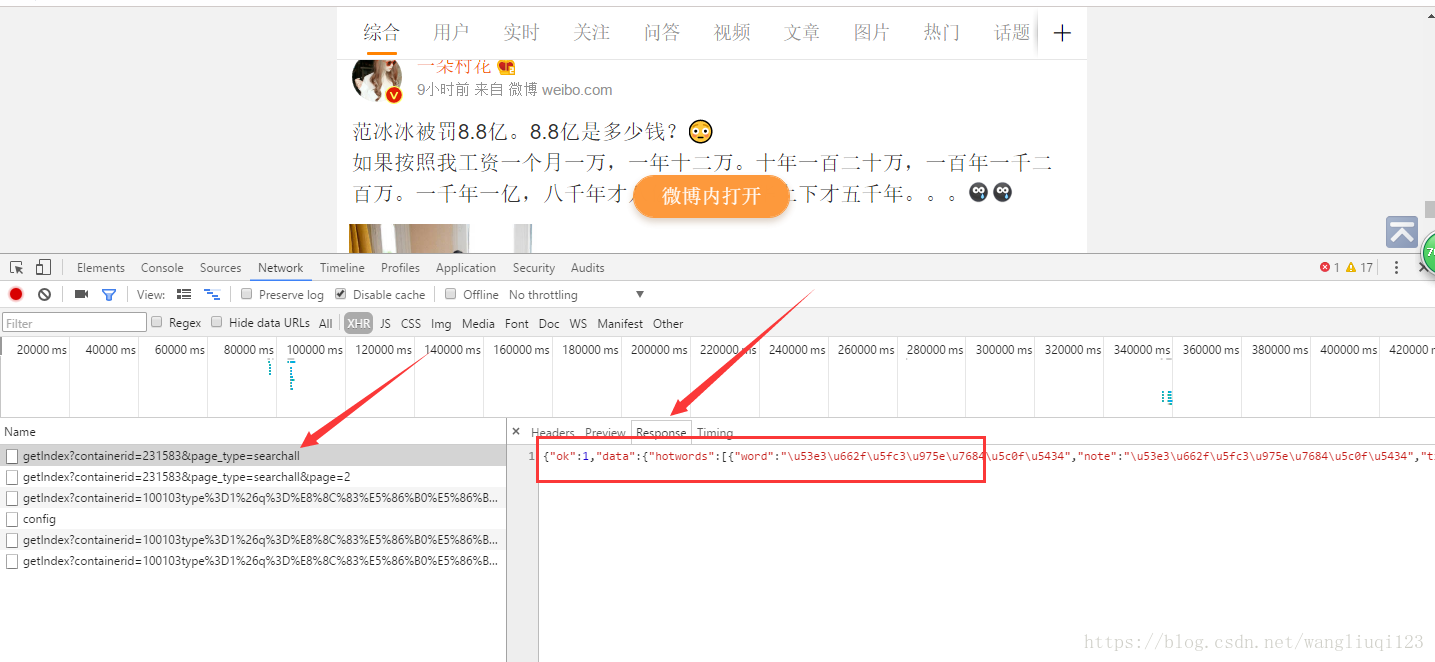
复制这段json,然后通过下面两个网站格式化一下,便于我们观察规律:
Unicode 转中文:http://www.atool.org/chinese2unicode.php
Json在线格式化:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 344
344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









