






简介:
基于Django的admin后台,将之前写的一个爬虫集成到项目当中,爬虫抓取公司信息,存表,web端展示与调度管理,使用账号登陆认证。如果只是完成数据web展示跟调度的话,前端我觉着完全可以不写,只用admin(太懒了是吧,实际原因是前端是目前知识盲区而已~~)
组件:Python3.10 + Django3 + Celery
特点:
web端管理:在web端定时调度,并且可以手动启动,停止
页面设计:
首页: 是展示数据的页面,①按各爬虫模块,分别展示最近更新数据的企业列表。指标:公司总数及增长率、
调度管理页: 查看正在运行的调度
爬虫配置页: 配置爬虫参数,比如运行需要的cookie,数据库等。
难点:
调度管理页面模板的设计与开发,其中已经借用了admin、flower的管理后台,未实现的是爬取记录的实时获取
调度管理交互相关的后台,页面开发。
主要页面展示:
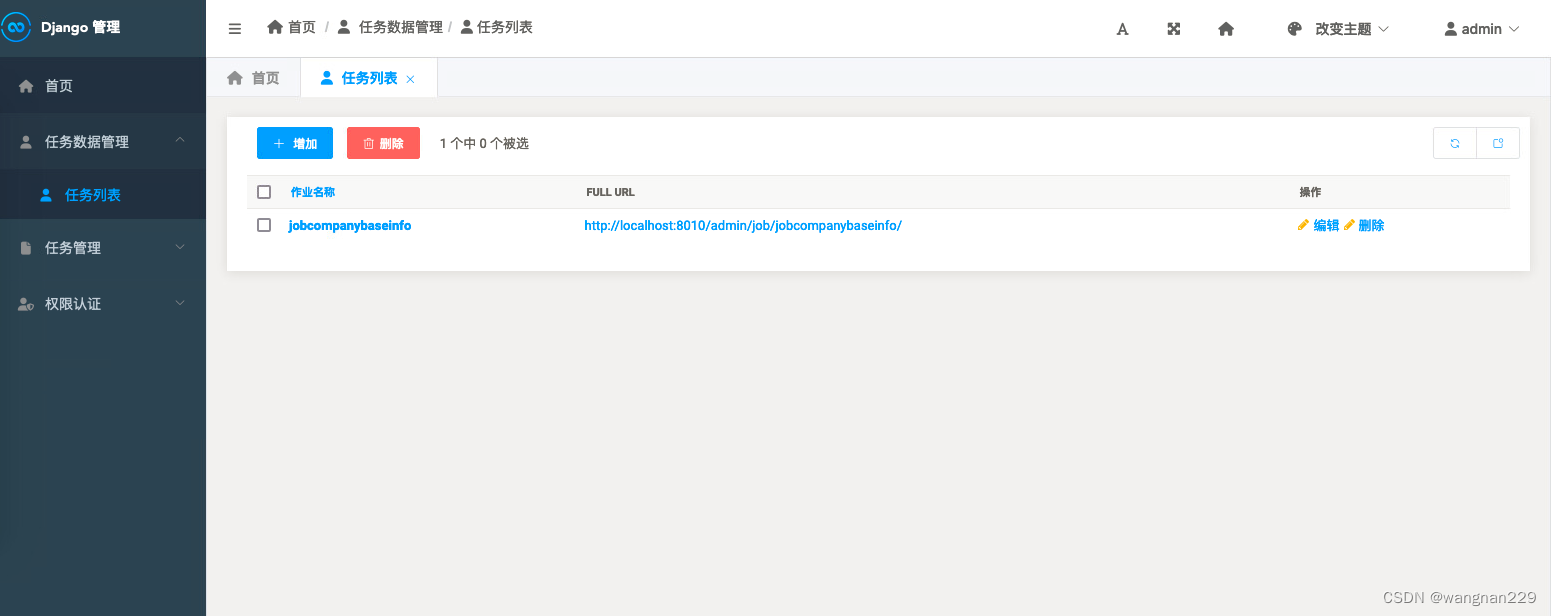 
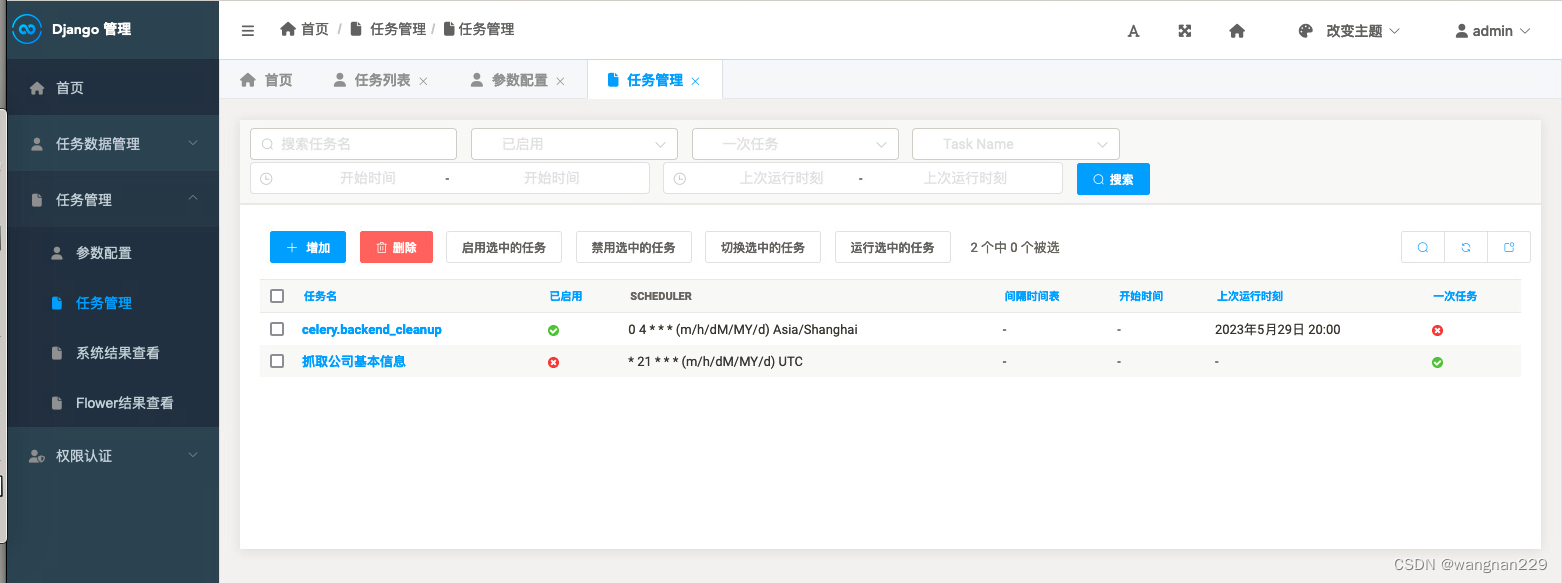 ## 简单总结
## 简单总结
这是可以作为一个练手的小项目,代码结构很简单,但也是有些实用的地方,比如你可以爬虫任务在跑着,然后刷新页面后出现抓取的最新时间倒序排的数据,还是感觉不错。
接下来,我们每天定时调度后产生数据,不能让他们静静的躺在数据库里了,得ETL,得分析,这是后面要写的了。今天收工先。

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









