







论文笔记:Extreme Learning Machine: A New Learning Scheme of Feedforward Neural Networks
Abstract:
前馈神经网络( feedforward neural networks)的学习速度比较慢,主要的原因可能是:1)广泛使用基于缓慢梯度的学习算法来训练神经网络。2)使用这种学习算法对网络的所有参数进行迭代调整。与传统的学习算法不同,本文针对单隐层前馈神经网络(SLFNs)提出了一种新的学习算法——极限学习机(ELM),它可以动态地选择输入权值并解析地确定输出权值。从理论上讲,该算法在极快的学习速度下提供了最佳的泛化性能。实验结果表明,该算法在某些情况下具有较好的泛化性能,比传统的前馈神经网络学习算法学习速度快得多。
一、Introduction
前馈神经网络逼近能力的研究主要集中在两个方面:紧输入集的普遍逼近( universal approximation on compact input sets)和有限集的逼近(approximation in a finite set)。许多研究者已经探索了标准多层前馈神经网络的普遍逼近能力。在真实的应用程序中,神经网络在有限训练集训练。在有限训练集函数近似,黄和Babri[4]表明sigle-hidden层前馈神经网络(SLFN)最多N隐藏神经元和几乎任何非线性激活函数可以学习N截然不同的观测误差为零。需要注意的是,在以往所有的理论研究工作中,以及几乎所有的前馈神经网络的实际学习算法中,都需要调整输入权值(将输入层与第一个隐含层连接起来)。
前馈网络的所有参数都需要进行调整,因此存在不同参数层(权重和偏差)之间的差异。几十年来,基于梯度下降的方法主要应用于各种前馈神经网络的学习算法中。在任意选取输入权值和隐层偏差后,SLFNs可以简单地看作一个线性系统,通过隐层输出矩阵的简单广义逆运算,可以解析地确定SLFNs的输出权值(连接隐层和输出层)。基于这一概念,本文提出了一种简单的SLFNs学习算法——极限学习机(extreme learning machine, ELM),其学习速度比传统的前馈网络学习算法(如反向传播算法)快数千倍,同时具有更好的gener- alization性能。与传统学习算法不同的是,该学习算法不仅趋向于训练误差最小,而且权值范数最小。Bartlett关于前馈神经网络的泛化性能的理论[9]指2出,当前馈神经网络达到较小的训练误差时,权值的范数越小,网络的泛化性能越好。因此,本文提出的学习算法对于前馈神经网络具有较好的泛化性能。

最大的创新点:
1)输入层和隐含层的连接权值、隐含层的阈值可以随机设定,且设定完后不用再调整。这和BP神经网络不一样,BP需要不断反向去调整权值和阈值。因此这里就能减少一半的运算量了。
2)隐含层和输出层之间的连接权值β不需要迭代调整,而是通过解方程组方式一次性确定。研究表明,通过这样的规则,模型的泛化性能很好,速度提高了不少。
总之:ELM最大的特点就是对于传统的神经网络,尤其是单隐层前馈神经网络(SLFNs),在保证学习精度的前提下比传统的学习算法速度更快。
二、Preliminaries
*(一)、摩尔-彭若斯广义逆(Moore-Penrose 'Generalized Inverse)
通常情况下如果没有特别指明,矩阵的伪逆就是指摩尔-彭若斯广义逆。广义逆有时也被当作摩尔-彭若斯广义逆的同义词用。摩尔-彭若斯广义逆常应用于求非一致线性方程组的最小范数最小二乘解(最小二乘法),并使得解的形式变得简单。矩阵的摩尔-彭若斯广义逆在实数域和复数域上都是唯一的,并且可以通过奇异值分解求得。
令PS表示到向量空间S上的正交投影。对于任意一个m乘n的复矩阵A,设R(A)表示A的值域空间。摩尔于1935年证明矩阵A的广义逆矩阵G必须满足的条件:
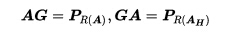
以上两个条件称为摩尔条件。满足摩尔条件的矩阵G称为矩阵A的摩尔逆矩阵。这样定义显然不方便使用,彭若斯于1955年提出了定义广义逆矩阵的另外一组条件:

以上四个条件常称摩尔-彭若斯条件。满足全部四个条件的矩阵G,就称为A的摩尔-彭若斯广义逆矩阵,记作A+。从摩尔-彭若斯条件出发,彭若斯推导出了摩尔-彭若斯广义逆的一些性质:
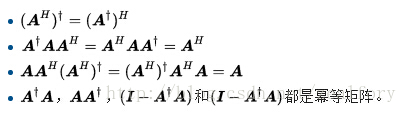
广义逆的满秩算法的计算:

(二)、一般线性系统的最小范数最小二乘解(minimum Norm Least- Squares Solution of General Linear System)

三、Extreme Learning Machine原理
上文已经简要介绍了一般线性系统Ax = y的摩尔-彭罗斯逆和最小范数最小二乘解,现在我们可以提出一个极端带N个隐藏神经元的单层前馈网络(SLFNs)的快速学习算法,隐藏层的数据要小于训练样本的数目。


ELM算法的基本步骤:

四、 Performance Evaluation
(一)、函数逼近基准问题
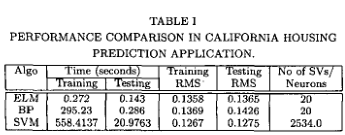
California Housing是一个从StatLib库中获得的数据集。预测加州房价有20640个观测值。有关变量的信息是通过1990年人口普查中加州的所有街区组收集的。在这个样本中,一个街区组平均包括1425.5个人,他们生活在一个地理位置紧凑的地区。自然,所包括的地理区域与人口密度成反比。以经纬度为度量单位,计算每个块组的质心之间的距离。所有报告自变量和因变量零项的块组都被排除在外。最后的数据包含了9个变量的20,640个观察值。对所有算法进行了50次试验。时间和均方根值(RMS)如下表所示。
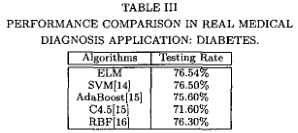
(二)、与实际医疗诊断应用的基准
新提出的ELM算法和许多其他流行算法的性能比较已经用于一个真实的医学诊断问题:糖尿病,使用的是应用物理实验室(Johns Hopkins university, 1988)生产的“Pima Indians糖尿病数据库”。根据世界卫生组织的标准(例如,糖尿病患者是否表现出糖尿病。在每个试验中,分别随机选择75%和25%的样本进行训练和测试。将SVM算法参数C调优设置为:C = 10,其余参数默认设置。
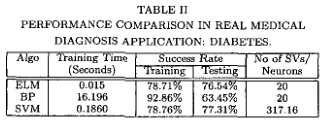
成功的概率表
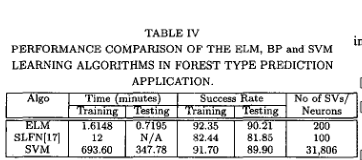
**(三)、用真实世界的大型复杂应用程序进行基准测试
我们还测试了ELM算法在大型复杂应用程序(如Forest)中的性能
植被类型预测!
森林覆被类型预测是一个极其复杂的分类问题,分为7类。30×30米细胞的森林覆盖类型取自美国林务局(USFS)区域2资源信息系统(IUS)数据。每个观察有581,012个实例(观察结果)和54个属性。为了与以前的工作进行比较,同样地,它被修改为一个二元分类问题,目标是将第2类与其他6类分开。训练数据10万,测试数据481012。支持向量机的参数为C = 10, y = 2。森林覆被类型预测是一个极其复杂的分类问题,分为7类。30×30米细胞的森林覆盖类型取自美国林务局(USFS)区域2资源信息系统(IUS)数据。每个观察有581,012个实例(观察结果)和54个属性。为了与以前的工作进行比较[l7],同样地,它被修改为一个二元分类问题,目标是将第2类与其他6类分开。训练数据10万,测试数据481012。支持向量机的参数为C = 10, y = 2。人们花费了很长时间来寻找支持向量机的合适参数。
Discussions and Conclusions
极限学习机(ELM)相对于单隐藏层前馈神经网络(SLFNs)的优点
(1)ELM的学习速度非常快,通过表4可以发现ELM的学习速度是SVM的学习速度的430倍。
(2)ELM不仅倾向于达到最小的训练误差,而且倾向于达到最小的权值范数。因此,所提出的ELM对于前馈神经网络具有较好的泛化性能
(3)ELM学习算法可用于训练具有不可微激活函数(nondifferentiable activation functions. )的单隐藏层神经网络。
(4)ELM学习算法看起来比大多数前馈神经网络的学习算法简单得多
参考博文:
https://blog.csdn.net/google19890102/article/details/18222103?utm_source=copy















 1203
1203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









