







引用他人的一篇文章
http - 什么是WebSocket,它与HTTP有何不同?_个人文章 - SegmentFault 思否
HTTP协议
HTTP是单向的,客户端发送请求,服务器发送响应。举例来说,当客户端向服务器发送请求时,该请求以HTTP或HTTPS的形式发送,在接收到请求后,服务器会将响应发送给客户端。每个请求都与一个对应的响应相关联,在发送响应后客户端与服务器的连接会被关闭。每个HTTP或HTTPS请求每次都会新建与服务器的连接,并且在获得响应后,连接将自行终止。HTTP是在TCP之上运行的无状态协议,TCP是一种面向连接的协议,它使用三向握手方法保证数据包传输的传递并重新传输丢失的数据包。
HTTP可以运行在任何可靠的面向连接的协议(例如TCP,SCTP)的上层。当客户端将HTTP请求发送到服务器时,客户端和服务器之间将打开TCP连接,并且在收到响应后,TCP连接将终止,每个HTTP请求都会建立单独的TCP连接到服务器,例如如果客户端向服务器发送10个请求,则将打开10个单独的HTTP连接。并在获得响应后关闭。
理解上面这段关于 HTTP的描述时我觉得还要了解一下HTTP长连接的概念,以及HTTP与TCP的关系,简单概括一下就是:
HTTP协议的长连接和短连接,实质上是TCP协议的长连接和短连接。- 每个
HTTP连接完成后,其对应的TCP连接并不是每次都会关闭。从HTTP/1.1起,默认使用长连接,用以保持连接特性。使用长连接的HTTP协议,会在响应头有加入这个头部字段:Connection:keep-alive - 在使用长连接的情况下,当一个网页打开完成后,客户端和服务器之间用于传输
HTTP数据的TCP连接不会关闭,如果客户端再次访问这个服务器上的网页,会继续使用这一条已经建立的连接。Keep-Alive不会永久保持连接,它有一个保持时间,可以在不同的服务器软件(如Apache,Nginx,Nginx中这个默认时间是 75s)中设定这个时间。实现长连接要客户端和服务端都支持长连接。 HTTP属于应用层协议,在传输层使用TCP协议,在网络层使用IP协议。IP协议主要解决网络路由和寻址问题,TCP协议主要解决如何在IP层之上可靠的传递数据包,使在网络上的另一端收到发端发出的所有包,并且顺序与发出顺序一致。TCP有可靠,面向连接的特点。
HTTP消息信息是用ASCII编码的,每个HTTP请求消息均包含HTTP协议版本(HTTP/1.1,HTTP/2),HTTP方法(GET/POST等),HTTP标头(Content-Type,Content-Length),主机信息等。以及包含要传输到服务器的实际消息的正文(请求主体)。HTTP标头的大小从200字节到2KB不等,HTTP标头的常见大小是700-800字节。当Web应用程序在客户端使用更多cookie和其他工具扩展代理的存储功能时,它将减少HTTP标头的荷载。

WebSocket协议
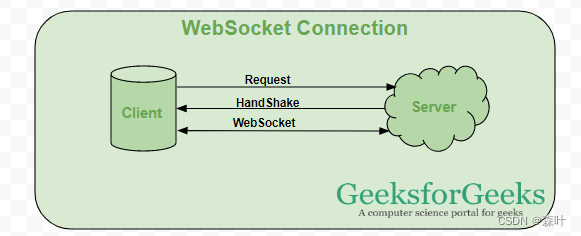
WebSocket是双向的,在客户端-服务器通信的场景中使用的全双工协议,与HTTP不同,它以ws://或wss://开头。它是一个有状态协议,这意味着客户端和服务器之间的连接将保持活动状态,直到被任何一方(客户端或服务器)终止。在通过客户端和服务器中的任何一方关闭连接之后,连接将从两端终止。
让我们以客户端-服务器通信为例,每当我们启动客户端和服务器之间的连接时,客户端-服务器进行握手随后创建一个新的连接,该连接将保持活动状态,直到被他们中的任何一方终止。建立连接并保持活动状态后,客户端和服务器将使用相同的连接通道进行通信,直到连接终止。
新建的连接被称为WebSocket。一旦通信链接建立和连接打开后,消息交换将以双向模式进行,客户端-服务器之间的连接会持续存在。如果其中任何一方(客户端服务器)宕掉或主动关闭连接,则双方均将关闭连接。套接字的工作方式与HTTP的工作方式略有不同,状态代码101表示WebSocket中的交换协议。
是不是没看懂?
简单概括
1. http 和 websocket 都是一种传输协议,协议的意思就是 A 和 B 两人沟通一件事时,A 和 B 互相不认识,也没见过面,怎么沟通呢,两个人都看一个说明书,按照说明书跟对方说话,说明书就是协议;
2. Websocket是http协议的一个补充,如果在第一次聊天时,你要跟对方报姓名,电话,职业等等,若这个过程只是一来一回就结束了,那么还是有必要的,但是如果你想跟对方多聊几句话,每次说话都要报姓名,电话,职业等,你觉得是不是很别扭,浪费自己的时间?并且服务端的机制还是遇到http这种协议,处理完,就将这个人消息从内存里删除了,根本没有考虑再聊的情况。
3. Websocket 为了能在自报家门后,还能让服务端别忘了自己,则在http协议上增加了两个标签,有了这两个标签,第一次通信后,服务端不会立马把这个客户端信息删除,而是保留着,留着下次客户端进来后再沟通,因此一个Websocket通信会有onconnect这个环节,也即http的request/response概念,如果这里你就告诉客户端,你不接受,也即close(一般是鉴权不成功,鉴权和http鉴权一个样,一旦这里disconnected,那么就不存在后续的onmessage了)。
Upgrade: websocket
Connection: upgrade4. 一旦onconnect成功之后,那么之后就不再传输一堆header标签了,而是直接发送二进制字符串,想发什么随便你们,此时就是onmessage事件来回沟通了,在onmessage传输过程中,你可以自定义一些json格式,方便你和服务端沟通,但是这必须要前后端达成一致协议才行,甚至如何加密,你们也可以自己定。在这个过程中,仍然可以主动切断connect链接,例如服务端发现有两个客户端在使用,则主动发起了close事件,客户端onclose接收到后,会对服务端这种主动关闭,做出一定的反应;
这样描述是不是更明确了?
上面是宏观代码层面的描述,我们再从微观上来描述下通信过程?
之前以长连接和短链接的方式来描述这个过程不够形象,通信过程并非是管道中的水,理解为一直流淌的水就会加大理解难度,Java中的数据流就是就是这个概念,但是数据流只是看起来像,就如光波和光粒子的概念,到最底层来理解时,仍然还是以抛数据球的方式来理解,必定过程是分离的,而不是一直传输着的。
TCP的三次握手,就是一个抛球的概念,将一堆数据打包成一个球,来回抛三次,然后客户端和服务端就知道两者之间信道通畅无阻塞,此时再开始抛http数据球,服务端接到客户端发过来的http数据球,解析之后经过一阵倒腾,把结果数据打成球,再抛给客户端,服务端是不会记忆客户端抛过来的HTTP数据包的;
HTTP1.1协议中,一次request必须等待response回来后再发出去下一个request这是串联的过程,不能一下子先抛过去多个request过去,为啥呢?因为早期的那批程序员以同步方式思考,一步一步按顺序来,没兼容批量搞事情(批量这个过程因为涉及到底层二进制问题应该很难,看http2协议中对帧这个概念就是流来标识的,我们这里就把帧理解为一个标识就够了),因此在http协议包里面标识,如果连续抛了多个request过去,同时返回来多个response,客户端就不知道是谁的response包了。要想加快这个过程,就要多开几个TCP三次握手的停靠点,每个停靠点都是同步串行的,加在一起就是并行了,这种方式速度也挺快,chrome浏览器就是这么做的,但是对于一张大图片来说,就很慢很慢,为啥?因为图片是流,现在一张图片都几M,一张图片的传输又不能拆成几次来请求,这就只能有等了,但如果一次性发送10个请求每个请求1M,因为图片是随机像素点的加载模式,那么图片就可以从模糊逐渐变为清晰,如果10个包都被抛过来了,那么整张图片就清晰了,否则模糊着也能识别。
HTTP2最大的改进,就是加了一个帧,名字起得很晦涩,实际上就是增加了一些标识,用于区分多次request,进而让连续发过去的request能够让服务端进行隔离,这一整套方法就叫做帧,且这个标识还可以回收使用,具体就是一个数字,有了数字,就有了名字,连续抛三个球过去,只要服务端带着这个帧返回来,客户端就能知道谁是谁的货,就不会分发出错;
WebSocket又是怎么回事呢?
抛的http包,服务端是不会在意的,服务端只管处理一下数据然后加上帧就抛回来了,这样可以大大减轻服务端的压力,因为服务端压根就没想过要跟客户端再有交互,就像柜台上的公务员,只负责收集数据,然后给你一个盖了章的回执,这事就归档了,不会再主动联系你。除非你提交的文件里,有个后续给通知的要求。
websocket就是有后续通知,协议里面有个标识,叫upgrade,表达的意思是这个协议还是http协议,但是接下来,你还得跟我保持联系,所以服务端不能干完这个事情就结束了。接下来,还需要继续沟通。但联系之前不需要再提交一遍申请文件(也即不需要打成HTTP包抛过来)了。
因此,服务端会保留下客户端的标识,这个标识往往叫做fd。而保存客户端的信息就增加了服务端的内存消耗,表现在公务员哪里就是公务员要记着这件事,以方便后续与你沟通。按此推理,如果客户端不能友好的给服务端发送关闭请求,那么服务端在没有心跳机制下,服务端的内存有溢出的风险。
















 1549
1549











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











