







提起大数据,不得不提由IBM提出的关于大数据的5V特点:Volume(大量)、Velocity(高速)、Variety(多样)、Value(低价值密度)、Veracity(真实性),而对于大数据领域的从业人员的日常工作也与这5V密切相关。大数据技术在过去的几十年中取得非常迅速的发展,尤以Hadoop和Spark最为突出,已构建起庞大的技术生态体系圈,以实时计算的Flink正在悄然崛起,在未来会占主导地位。
首先通过一张图来了解一下目前大数据领域常用的一些技术,当然大数据发展至今所涉及技术远不止这些。
BigData Stack:
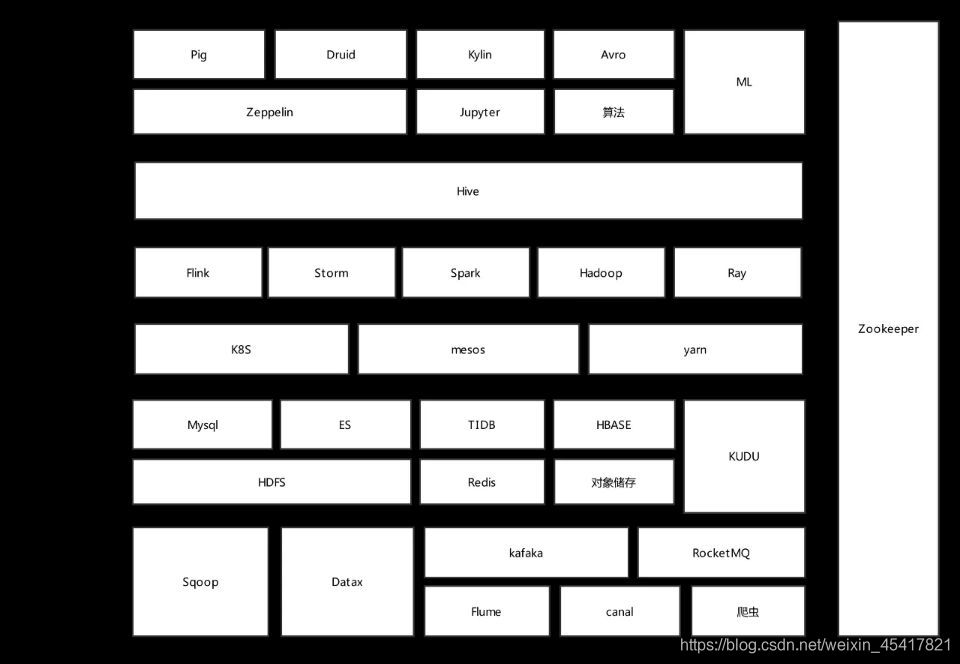
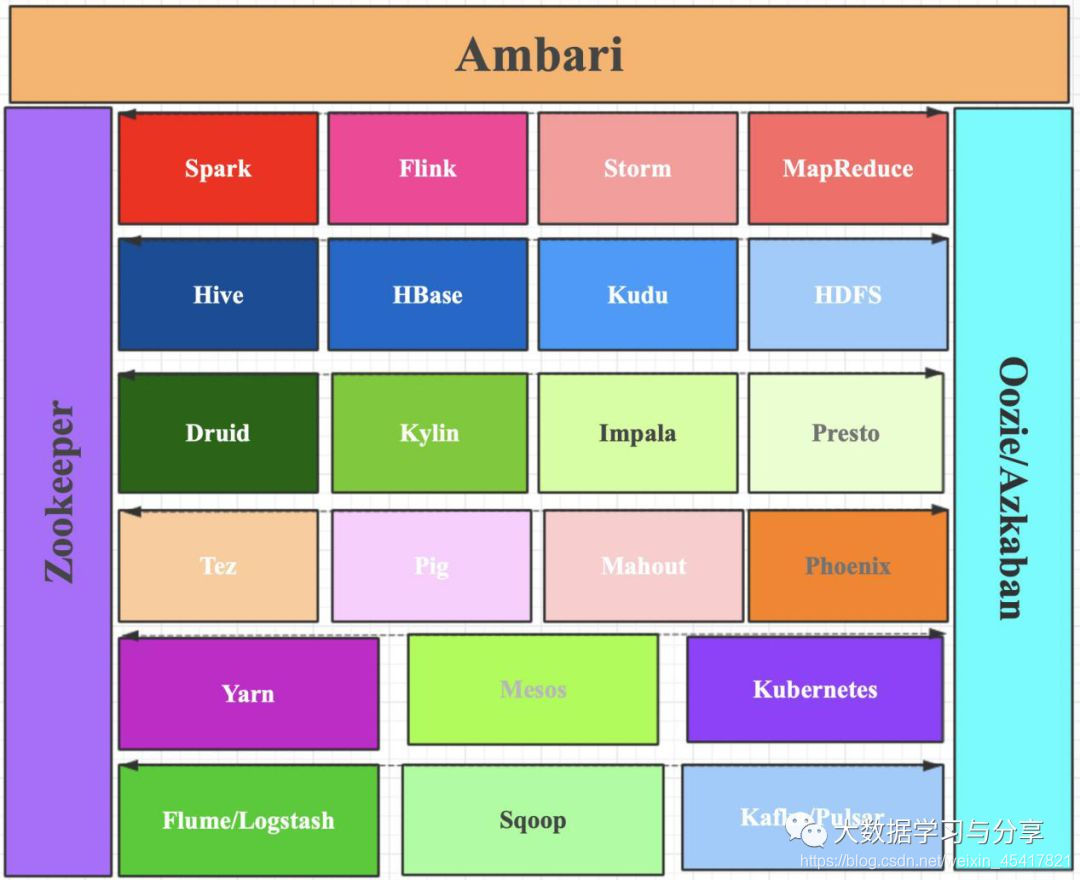
成为大数据开发工程师必备的常用技术栈
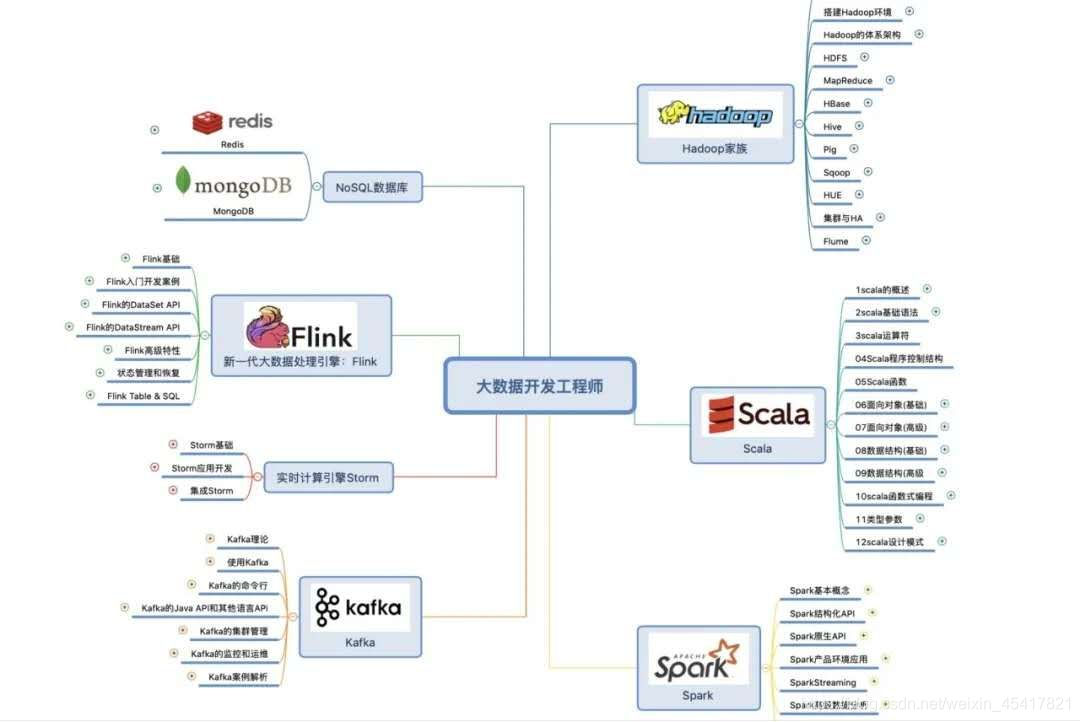
下面分不同层介绍各个技术,当然各个层并不是字面意义上的严格划分,如Hive既提供数据处理功能也提供数据存储功能,但此处将其划为数据分析层中
1. 数据采集和传输层
- Flume
Flume一个分布式、可靠的、高可用的用于数据采集、聚合和传输的系统。常用于日志采集系统中,支持定制各类数据发送方用于收集数据、通过自定义拦截器对数据进行简单的预处理并传输到各种数据接收方如HDFS、HBase、Kafka中。之前由Cloudera开发,后纳入Apache
- Logstash
ELK工作栈的一员,也常用于数据采集,是开源的服务器端数据处理管道
- Sqoop
Sqoop主要通过一组命令进行数据导入导出的工具,底层引擎依赖于
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2883
2883

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









