









前言
最近在看SSD的论文和他的keras的源码,网上我也查了,细讲keras源码的比较少,我打算啃一下源码,这样自己也加深印象,顺便和前面的Faster RCNN源码比对一下,看看哪些思路是类似的,哪些是特别的。同时也想把这些东西分享下,希望对学习SSD的人有用吧,其实我也很想网上有比较完整的源码解析,这样对于读论文和理解这个算法有很大的帮助,因为很多时候你看论文,看上去很像自己懂了,其实真要你去做,你是无从下手的,毕竟这些算法的实现是有门槛和难度的,可不是一般的程序,其中的很多思想和工程的技巧也是值得我们学习的,另外我不打算讲SSD的论文,因为网上很多了,可以自己去看,我只会提到一些源码中的实现对应的论文的内容。
运行
我们在看源码之前当然是先要把源码下下来,然后能运行起来看看效果,这样我们才可以放心的去分析源码,对吧,所以我们先去下载,keras版的有好多,我们下比较经典的吧:
github源码
里面有很多模型参数下载,我就先提供一个VGG_VOC0712_SSD_300x300_iter_120000.h5,我们可以跑起来的:
链接:https://pan.baidu.com/s/16hqhCguEU7cghWuSs3fqBQ&shfl=sharepset
提取码:1mia
voc数据集地址
我们可以看看keras版的大致文件:

里面有一些python源码文件,也有jupyter notebook的文件:
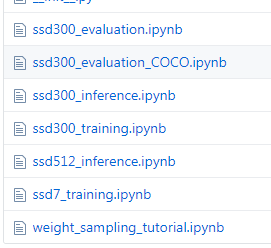
我们要跑的就是在jupyter notebook上的:

我们打开jupyter notebook选取ssd300_inference.ipynb后有几个需要注意的地方,可以顺序下来运行,但是不要运行加载与训练模型1.1.2这个cell,这个貌似是加载整个模型的文件,但是我们再github下载的貌似都是模型参数文件,所以会报错,:

还要注意数据集的路径,下载完数据集后,要修改成你自己的:

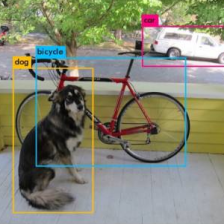
之后应该就是一步步往下执行啦,最后你会看到:


当然你可以改这两个参数,来改变测试的图片,表示每次几张图,你要看第几张:

最基本的先运行起来,这样就成功了一半,后面慢慢根据论文分析源码,后面我会继续分析训练源码的,加油吧。

好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,部分图片来自网络,侵删。















 1371
1371











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









