










写的目的
本篇想试试视觉训练的效果,感觉好像不是很好,不知道是我设置不对还是什么,大家可以自试试。

创建环境
首先还是创建新场景,新大脑,具体不在啰嗦了,同时创建一张RenderTexture图,见图:
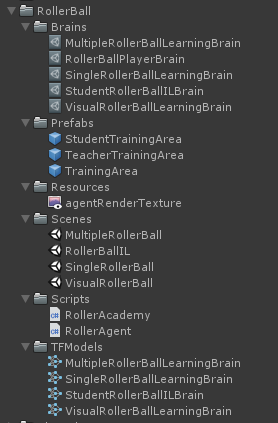
然后在场景中添加摄像机和显示摄像机看到的图
相关设置如下:


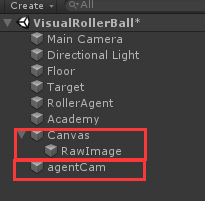
之后在代理脚本里也要添加渲染图,当然也可以添加相机,你可以自尝试:
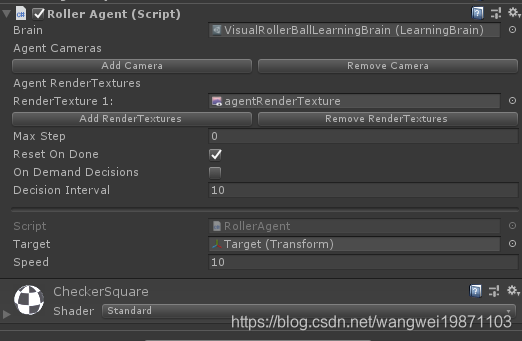
还要设置Brain,因为有了视觉,所以不需要向量观察量了:
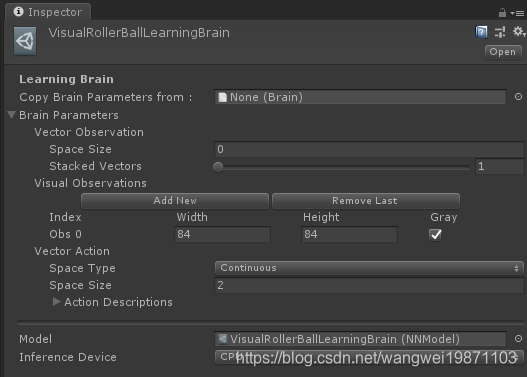
同时代理里也要注释掉,否则会报错:

之后还是像以前那样把Agent和Academy里的Brain都设置好进行训练。
在trainer_config.yaml里添加要训练的大脑,我是参考GridWorldLearning的参数的
VisualRollerBallLearningBrain:
batch_size: 32
normalize: false
num_layers: 1
hidden_units: 256
beta: 5.0e-3
gamma: 0.9
buffer_size: 256
max_steps: 5.0e5
summary_freq: 2000
time_horizon: 5
貌似结果不尽如人意啊,或许什么地方设置不对。如果熟悉的朋友请指教。

总结
结果好像有点差,不知道什么原因,我猜可能是因为仅仅凭一张图,很难知道到底要干什么,没有什么根据,CNN提取特征向量或许不是我们想要的,所以或许训练不起来的样子,或许是时间问题,要训练很长时间。
例子主要文件unity3D-ml-agent-0.8.1
好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,部分图片来自网络,侵删。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









