







隐马尔科夫链主要是两部分:
第一部分:与传统马尔科夫过程一样,都是一个状态转移矩阵,假设是:当前状态只与前一状态有关;
第二部分:在某一状态下会有一个对应的观测模型,不同状态有不同的观测模型;
这点与GMM都是一种两级跳的思想,只是GMM选定的高斯分布之间没有关联,我这次哪个高斯部件来生成与上次选择没有关系,但是HMM前后有关系,不过只有一阶;
用一个图表示如下:
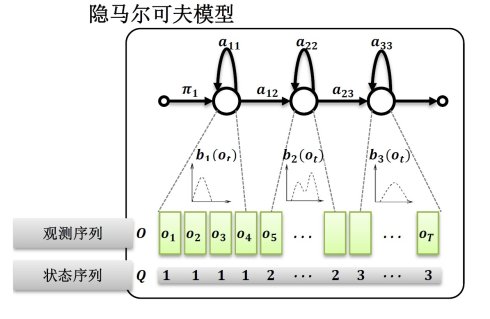
(图片来源于互联网)
观测序列为o1 o2 o3.......oT 每个观测序列的背后都有一个隐含状态,而且这些隐含状态之间有个跳转概率,每个状态对应一个概率密度函数,该状态依据这个概率密度函数来生成观测值;说他是隐马尔科夫链,正是因为,这个马尔科夫过程隐藏在观测值的背后;
HMM有三个参数:
1)初始状态概率 pi ;
2)状态之间的概率转移矩阵A;
3)每个状态对应的生成观测模型B ;
有了这三个参数,我们就能完整的描述一个隐马尔科夫链。
关于这个模型,必然有其应用,其对应的三个问题如下:
1)概率计算的问题:最简单的,我给定HMM的参数,求出观测序列o1 o2 o3.......oT 的概率;
2)学习问题:我给出观测序列o1 o2 o3.......oT 求出这个隐马尔科夫模型的三个参数,这是个最大似然估计的问题;
3)解码问题:给出观测序列o1 o2 o3.......oT,求这个观测背后的状态序列s1 s2 s3.......sT。
对于第一个问题:(概率计算问题)
1)直接计算法

pi为初始状态概率,中间的S是隐含状态,因为对应的S状态序列可能有多种可能性(假设有N种可能状态,序列长度为K,那么就有N的T次方个可能的状态序列),因而对这个公式求和是一个非常复杂的事情。因而这个方法仅仅作为理论推导使用,并不实用;
2)前向算法
这种算法类似于动态规划,每一步利用前一步的结果,这样就不需要重复计算,说他是前向算法,源于其一步一步向前递推的过程,动态规划的算法最重要的是要考虑好,每一步我要保存什么数据,这个数据对下一次的计算有用
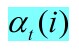
用来存储时间截止时间为t ,且 t 时刻状态为 i,且观测现象为o(t) 的概率,那么根据递推我们能得到
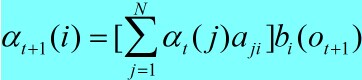
aji代表状态转移矩阵中从状态 j 转到状态 i 的概率 bi(o(t+1))代表状态为 i 的时候观察值为o(t+1)的概率,通过这个简单的递推我们能得到
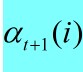
综上我们根据观测序列求出每一步的alpha
最后我们要求的值

代码如下:
#include<iostream>
using namespace std;
typedef struct namuna
{
double *pi; //初始向量转移矩阵
double **A; //状态转移矩阵
double **B; //状态->现象转移矩阵
int NumofState; //状态数目
int NumofObs; //观测现象数目
namuna(int NumofState_Input,int NumofObs_Input)
{
if (NumofObs_Input<=0||NumofState_Input<=0)
{
return;
}
NumofState=NumofState_Input;
NumofObs=NumofObs_Input;
pi=new double[NumofState];
A=(double **)new int[NumofState];
for (int i=0;i<NumofState;i++)
{
A[i]=new double[NumofState];
}
B=(double **)new int[NumofState];
for (int i=0;i<NumofState;i++)
{
B[i]=new double[NumofObs];
}
}
~namuna()
{
delete []pi;
for (int i=0;i<NumofState;i++)
{
delete []A[i];
}
delete []A;
for (int i=0;i<NumofState;i++)
{
delete []B[i];
}
delete []B;
}
}Namuna;
//输出在给定模型参数情况下,当前观测序列出现的概率
double HMMQX(Namuna &namuna_Input,int *pObs,int nLenofObsSeq);
int main()
{
Namuna nam(3,2);
nam.pi[0]=0.2;nam.pi[1]=0.4;nam.pi[2]=0.4;
nam.A[0][0]=0.5;nam.A[0][1]=0.2;nam.A[0][2]=0.3;
nam.A[1][0]=0.3;nam.A[1][1]=0.5;nam.A[1][2]=0.2;
nam.A[2][0]=0.2;nam.A[2][1]=0.3;nam.A[2][2]=0.5;
nam.B[0][0]=0.5;nam.B[0][1]=0.5;
nam.B[1][0]=0.4;nam.B[1][1]=0.6;
nam.B[2][0]=0.7;nam.B[2][1]=0.3;
int pObs[3]={0,1,0};
cout<<HMMQX(nam,pObs,3);
getchar();
return 0;
}
//pObs存储的是时间为t时候的观测值
double HMMQX(Namuna &namuna_Input,int *pObs,int nLenofObsSeq)
{
int StateNum=namuna_Input.NumofState;
double **Alpha=(double **)new int[nLenofObsSeq];
for (int t=0;t<nLenofObsSeq;t++)
{
Alpha[t]=new double[StateNum];
}
for (int i=0;i<StateNum;i++)
{
Alpha[0][i]=namuna_Input.pi[i]*namuna_Input.B[i][pObs[0]];
}
for (int t=1;t<nLenofObsSeq;t++)
{
for (int i=0;i<StateNum;i++)
{
double tempSum=0.0;
for (int j=0;j<StateNum;j++)
{
tempSum+=Alpha[t-1][j]*namuna_Input.A[j][i];
}
Alpha[t][i]=tempSum*namuna_Input.B[i][pObs[t]];
}
}
double dRes=0.0;
for (int i=0;i<StateNum;i++)
{
dRes+=Alpha[nLenofObsSeq-1][i];
}
return dRes;
}3)后向算法
第二个问题:(学习问题)
1)监督学习算法
2)非监督学习算法 Baum-Welch算法,EM在HMM中的具体实现
第三个问题:(解码问题)
1)近似算法
2)维特比算法(这是很厉害的一个算法)
具体的以后再补充。(未完待续)















 5090
5090

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









