







1 决策树算法介绍
在机器学习的监督学习基础(Supervised learning)中,我们会学习到决策树(Decision Tree)算法,是一种以树结构形式表达的预测分析模型。根据处理数据类型的不同,决策树又为分类决策树与回归决策树。
1.1 决策树算法原理
对于决策树算法官方的回答为:
决策树构造的输入是一组带有类别标记的例子,构造的结果是一棵二叉树或多叉树。二叉树的内部节点(非叶子节点)一般表示为一个逻辑判断,如形式为a=aj的逻辑判断,其中a是属性,aj是该属性的所有取值:树的边是逻辑判断的分支结果。多叉树(ID3)的内部结点是属性,边是该属性的所有取值,有几个属性值就有几条边。树的叶子节点都是类别标记。
由于数据表示不当、有噪声或者由于决策树生成时产生重复的子树等原因,都会造成产生的决策树过大。因此,简化决策树是一个不可缺少的环节。寻找一棵最优决策树,主要应解决以下3个最优化问题 ①生成最少数目的叶子节点;②生成的每个叶子节点的深度最小;③生成的决策树叶子节点最少且每个叶子节点的深度最小。
简单总结:
这是来自百度百科,太复杂的讲解了。在我眼中,打个比方,漫威电影大家都看过吧。如何判断电影中超能力者是不是好人。通过直觉判断,这个命题首先得是超能力者,不是超能者判断为无;其次判断做没做好事,做了好事判断他是好人,没做好事也不能代表他不是好人,这我们就需要做进一步的判断了。通过这个例子我们就可以画出一棵超级简单的决策树。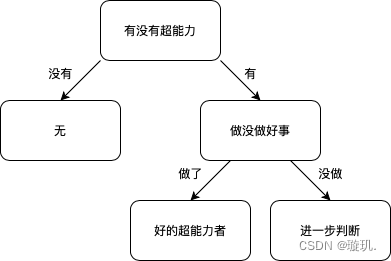
当然这些判断条件是根据我们的直觉进行选择进而判断的,而决策树算法的核心就是如何选择最优的划分属性,所谓的最优划分属性,对于二元分类而言,就是尽量使划分的样本属于同一类别,即“纯度”最高的属性。简而言之就是能让这个判断条件分出来的某一类对于分类正确而言 最不会出错。
于是我们可以概括出决策树算法的实现流程:
1. 进行数据的预处理,将类别数据转换为数字,将连续变量离散化。
2.特征选择:这是决策树算法的核心,常见的划分方式有信息增益,信息增益比,以及基尼指数
3.决策树构建,递归执行直到无法进行划分。
4.为了避免过拟合,需要进行剪枝(后面会单独一篇文章讲解剪枝)。
5.决策树的构建与评估。
1.2 特征的选择
1.2.1 熵和条件熵
熵是表示随机变量不确定性的度量,定义为:
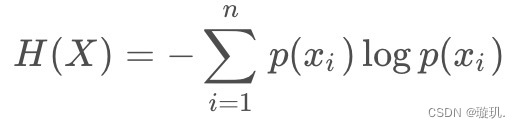
其中P(X)代表x在样本中的概率。熵越大说明数据集的不确定性也可以说混乱度越高。简单来说就是数据更加的杂乱无章。
条件熵:在已知某些信息的情况下,对于另一个随机变量的不确定性的度量,由以下表达:
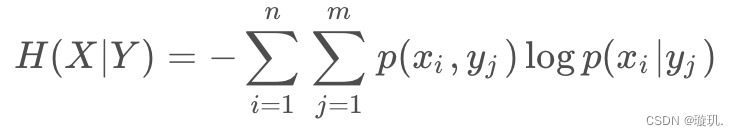
p(x,y)是同时满足条件x与y的样本在数据集中的概率。
1.2.2 信息增益
表示在已知某个特征的条件下,对数据集分类的不确定性减少的程度。信息增益越大,说明特征对分类的贡献越大。信息增益的计算公式为:
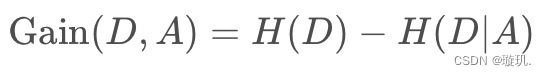
也就是样本熵减去对于某一特征而言的条件熵。
1.2.3 信息增益比
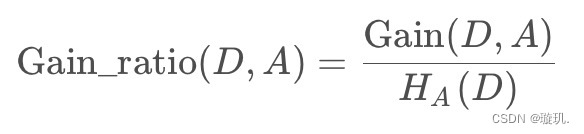
解决信息增益偏向选择取值较多的特征的问题。
1.2.4 基尼指数
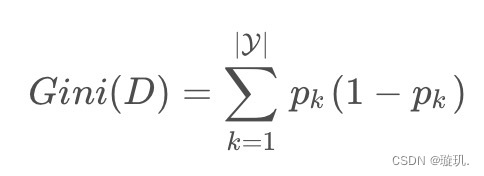
基尼指数是另一种用来衡量混乱度的指标,基尼指数越低以为着结点中样本趋向于属于同一类,以此将数据划分成更高的子集。
其中y是类别个数,pk是数据集中属于类别k的个数的占比。
2 代码实现
2.1 源代码的实现
实践才会出真知,了解了算法总是让人感觉脑子会了,但手不会,完整的通过设计程序过一遍算法流程才能更清晰明了的去理解算法过程。在这个模型源码实现中我们用到信息增益作为划分方式。
首先创建一个数据集,简单的分辨超能力者是否是好人进行决策树算法预测。
dataset = [[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']]
labels = ['hero','good thing']第一步定义函数计算熵值:
#计算熵
def Calculate(dataset):
n = np.shape(dataset)[0] #样本个数
labelcount = {} #对不同类进行计数
for feat in dataset:
currentlabel = feat[-1] #判断当前样本的类别
if currentlabel not in labelcount.keys():
labelcount[currentlabel] = 0
labelcount[currentlabel] += 1
shannon = 0 #初始化熵值
for i in labelcount: #迭代的是字典的键值
prob = float(labelcount[i] / n)
shannon -= prob * log(prob,2) #加总
return shannon
print(Calculate(Dataset))第二步定义切分数据集的函数,根据不同熵比较的出的最佳分类属性我们需要对样本进行切分,不断递归切分最后我们才能得到最终树的模型。
def splitDataset(dataset,axis,value):
retDataset = []
for i in dataset:
if i[axis] == value: #如果满足条件
reducedFeatVec = i[:axis]
reducedFeatVec.extend(i[axis+1:])
retDataset.append(reducedFeatVec)
return retDataset
#打个比方
dataset = [[1,1,'yes'],
[1,1,'yes'],
[1,0,'no'],
[0,1,'no'],
[0,1,'no']]
#将满足第0位特征为1的样本进行切分
splitDataset(dataset,0,1)运行得到如下结果:
[[1, 'yes'], [1, 'yes'], [0, 'no']]
第三步选择最佳数据集最佳分类方式,这一函数与切分数据函数相互配合:
def chooseBest(dataset):
numFeatures = len(dataset[0])-1
baseEntropy = calcShannonEnt(dataset)
bestInfogain = 0.0 #初始化一个熵
bestFeature = -1 #初始化一个最佳分类属性
for i in range(numFeatures):
featList = [example[i] for example in dataset]
uniqueVals = set(featList)
newEntropy = 0
for value in uniqueVals:
subDataset = splitDataset(dataset,i,value) #满足条件的样本集合 例如性别属性分类,都是男性的样本集合
prob = len(subDataset)/float(len(dataset)) #男占总样本的比
newEntropy += prob * calcShannonEnt(subDataset)
infoGain = baseEntropy - newEntropy
if (infoGain > bestInfogain): #如果大于则替换最佳分类属性
bestFeature = i
return bestFeature最后一步就是创建我们最终的决策树,这需要用到递归算法,以及另一个自定义函数投票器进行解决:
#多数表决法
import operator
def majorityCnt(classList):
classCount = {}
for vote in classList:
if vote not in classCount.keys():
classCount[vote] = 0
classCount[vote] += 1
sortedClasscount=
sorted(classCount.items(),key=operator.itemgetter(1),reverse=True) #从大到小排列
return sortedClasscount[0][0]
def createTree(dataset,labels):
classlist = [example[-1] for example in dataset] #获得每个样本的分类集合
if classlist.count(classlist[0]) == len(classlist): #如果完全相同
return classlist[0] #所有类标签完全相同则返回类标签
if len(dataset[0]) == 1: #递归结束条件:属性都用完了
return majorityCnt(classlist)
bestFeat = chooseBest(dataset)#最好的分类属性索引
bestFeatLabel = labels[bestFeat]#找到分类属性对应的名称
myTree = {bestFeatLabel:{}} #创建树
del(labels[bestFeat]) #删除类集合中的这个类
featValues = [example[bestFeat] for example in dataset] #数据集合
uniqueVals = set(featValues) #去除重复值
print(uniqueVals)
for value in uniqueVals: #迭代这个属性的不同值
subLabels = labels[:] #剩下的属性
print(subLabels)
myTree[bestFeatLabel][value] = createTree(splitDataset(dataset,bestFeat,value),subLabels) #递归
return myTree以上就是代码算法实现的所有过程,在代码中我们选择的分类方式是增益熵算法,大家也可以根据不同的分类条件去修改代码。
2.2 调包实现
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
import numpy as np
# 加载数据集
X = np.array([1,1],[1,0],[1,0],[0,1],[0,1])
y = np.array([1,1,0,0,0])
# 构建决策树
hero = DecisionTreeClassifier()
hero.fit(X_train, y_train)
# 预测
y_pred = hero.predict(X_test)
# 评估性能
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy: ", accuracy)
调包实现决策树算法更加的简洁有效,也是在日常工作学习中最方便的方式。
3.决策树算法的优点与局限性
3.1 优点:
1. 简单:没错,决策树最主要的特征就是简单,模型简单,运算简单,对电脑的负载也不大。也可以处理高维数据,不需要进行降维,特征选择等操作,实在是易理解,易上手。
2.适用场景广:决策树不仅适用于二分类,多分类问题,回归问题也可以用到它,是一个万金油模型。
3.2 局限性:
1. 对样本数据要求高:决策树算法对输入数据的变化非常敏感。对于一些数据集而言会产生不一样的分类结果。
2.忽略属性之间的相关性:决策树算法假设每个特征在判断类别时都是独立的,忽略了特征之间的相关性。你向模型说什么特征它就会给你去分类什么特征,例如有现金多与有钱两个特征相关性极高,决策树默认两个特征都是独立。
4. 应用场景
1. 分类问题:例如垃圾邮件分类,你该不该向对方借钱评估。
2. 推荐系统:推荐你今天吃什么,你今天买什么。
3. 特征选择:选择什么特征对于数据集的分类是重要的哪些是可有可无的。
5. 参考资料
1. 机器学习实战(Machine learning in Action)
















 2105
2105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









