








 超级会员免费看
超级会员免费看
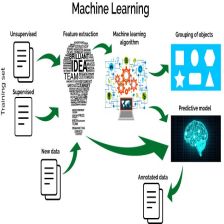
文章大纲
聚类与分类是数据挖掘中常用的两个概念,它们的算法和计算方式 有所交叉和区别。一般来说分类是指有监督的学习,即要分类的样本是 有标记的,类别是已知的;聚类是指无监督的学习,样本没有标记,根 据某种相似度度量把样本聚为k类。
聚类,顾名思义就是把一组对象划分成若干类,并且每个类中对象 之间的相似度较高,不同类中对象之间相似度较低或差异明显。聚类是 无监督学习的一种。 聚类的目的是分析出相同特性的数据,或样本之间能够具有一定的 相似性,即每个不同的数据或样本可以被一个统一的形式描述出来,而 不同的聚类群体之间则没有此项特性。 聚类与分类有着本质的区别,一个属于无监督学习,而一个属于有 监督学习。监督学习的意思是指,有着特定的目标或者明确的区别,即 人为可分辨。无监督学习则没有特定的规则和区别。 聚类与分类的不同之处在于,聚类算法在工作前并不知道结果如 何,不会知道最终将数据集或样本划分成多少个聚类集,每个聚类集之 间的数据有何种规则。聚类的目的在于发现数据或样本属性之间的规律,可以通过何种函数关系式进行表示。
聚类的要求是统一聚类集之间相似性最大,而不同聚类集之间相似 性最小。
聚类分析计算方法主要有如下几种:
- 划分算法
- 层次算法
- 密度算法
- 图论聚类法 <

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 993
993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











