







全文摘要
该论文提出了一种基于动态切片与预训练模型的代码漏洞检测方法,旨在解决传统基于深度学习的漏洞检测模型存在的问题,如准确性低、可扩展性差等。该方法通过动态切片获取包含路径特征的语句块,并利用预训练模型的语义提取能力将其表示为二维张量。然后,将代码结构和语义特征编码成灰度图像中的像素值,并借助Swin Transformer的特征提取能力,实现更准确的漏洞检测。实验结果表明,该方法能够有效降低误报率和漏报率,提高漏洞检测的准确性和可靠性。
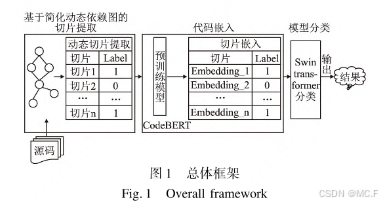
论文实验
作者进行了三个对比实验来评估基于动态切片与预训练模型的代码漏洞检测方法的有效性:
-
实验一:该实验研究了基于动态切片与预训练模型的代码漏洞检测方法是否适用于多种漏洞类型。作者选取了4种漏洞类型和一个混合数据集进行实验,并选定了5个常用维度进行实验。实验结果表明,本文漏洞检测方法在代码嵌入时选取适当的高度能够提高检测的准确率,选取合适的张量高度,对不同的漏洞类型,本文检测方法都具有较好的适应性,准确率都可达94%以上。
-
实验二:该实验比较了Swin Transformer模型和其他3个分类模型(ResNet、MobileNet、ViT)的分类性能。实验结果表明,Swin Transformer在准确率、查准率和F1分数等指标上优于其他3个模型,其F1分数达到了93%以上,而另外3个分类模型的F1得分都不足90%,这表明Swin Transformer在各项性能指标上相对于其他模型都有显著的优势。
-
实验三:该实验将本文方法DyNSliceVuln与目前较为先进的漏洞检测方法进行对比(SySeVR、VulDeepEcker、VulCNN)。实验结果表明,本文方法DyNSliceVuln在F1得分和准确率上皆比VulDeepEcker、SySeVR和VulCNN高,F1分数分别高出13.38%、7.8%和5.02%,与此同时,准确率也分别提高了6.07%、3.37%和1.42%。本文方法DyNSliceVuln相比于VulDeepEcker、SySeVR使用的动态切片,同时考虑了控制流与数据流信息,更重要的在于考虑了路径执行情况,DyNSliceVuln比SySeVR、VulDeepEcker、VulCNN包含更多的程序语义。同时结合本文实验2结果可见,使用SwinTransformer模型作为漏洞特征提取器和分类器,借助SwinTransformer的自注意力机制以及局部感知机制,去捕获动态切片中的重要特征,提取相关漏洞的关键信息,可实现更准确地进行漏洞检测。
文章优点
- 论文提出了一种基于预训练模型和动态切片的代码漏洞检测方法,具有更高的准确性和效率。
- 动态切片能够反映程序的运行状态,能够检测到一些只有在特定运行状态下才会发生的错误,比静态切片更具实际意义。
- 基于预训练模型的代码嵌入方式能够更好地保留程序的语义信息,结合动态切片可以实现更加有效的漏洞检测。
方法创新点
- 通过引入预训练模型的方式,使得代码嵌入过程更加有效,能够更好地保留程序的语义信息。
- 利用动态切片技术,能够更好地反映程序的运行状态,能够检测到一些只有在特定运行状态下才会发生的错误,提高了漏洞检测的准确性。
未来展望
- 可以进一步探索如何优化动态切片算法,提高其性能和准确性。
- 可以考虑将其他机器学习或深度学习技术应用于代码漏洞检测中,以提高检测效果。
- 可以探索如何将这种方法应用到更大规模的软件系统中,并解决大规模数据处理和计算资源消耗等问题。

















 3503
3503

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









