







原文链接:https://openaccess.thecvf.com/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf
文章概述
本文为了解决较深网络难以训练的问题,提出了残差学习框架(residual learning framework),在该框架中每一层不直接学习上一层的输出,而是学习上一层已经学到的部分与label之间的残差。该框架在ImageNet数据集上使用了152层的残差网络,比VGG深8倍,但其具有较低的复杂度和更高的准确性。该模型在ILSVRC 2015分类任务中获得了第一名,在其他数据集上的表现也很好。
介绍
如下图所示,在没有使用残差函数的普通网络中,可以看出随着层数的增加,无论是测试精度还是训练精度都不如浅一点的网络表现好。

假设在一个浅的网络中叠加层数得到一个深的网络,按道理这个深的网络前面层数可以跟浅网络学到一样的东西,多叠加的层数只是做一个identity mapping(恒等映射),那深层的网络性能是不会比浅层网络差的。但实验表明深层次的网络性能会出现退化现象,(就是明明有更好的解存在,但是却找不到)。这里作者提出残差学习框架,显示的构造一个identity mapping,使得更深的网络不会比浅层网络的性能更差。
假设期望的底层映射表示为H(x),但这时让它去学习映射F(x)=H(x)-x,即H(x)=F(x)+x。在实际编码中,该映射可以被一种叫做快捷连接(shortcut)的来实现,这个结构不会增加任何要学习的参数,也不会让计算复杂的变高,并且文章指出这种Residual结构的网络非常容易优化,而且随着网络层数越深,网络性能越好。
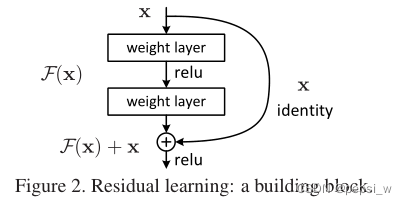
方法
残差学习
如果期望的潜在映射为H(x),与其让F(x) 直接学习潜在的映射,不如去学习残差H(x)−x,即F(x):=H(x)−x,这样原本的前向路径上就变成了F(x)+x,用F(x)+x来拟合H(x)。作者认为这样可能更易于优化,因为相比于让F(x)学习潜在映射,让F(x)学习成0要更加容易。这样,对于冗余的层,只需F(x)→0就可以得到恒等映射,性能不减。
其实这里残差学习收敛更快,实质是因为在训练中的梯度保持得比较好,不会出现梯度消失这类情况。假设g(x)为原始的一个小网络,增加层数后输出就为f(g(x)),这里对x进行求导,是f(x)对x求导乘上g(x)对x进行求导,新加的层越多,这里算梯度累乘就越多。由于梯度的值是比较小的,越深的层进行累乘后就会导致越来越小,这也是梯度消失的原因。
加上残差块后,输出就为f(g(x))+g(x),对其使用链式法则进行求导得到的结果就会比不使用残差快的结果大,因为这个始终加了一个g(x)对x的导数,一般浅层网络的这个梯度对相对大一些,所以就可以保持一个比较好的梯度进行收敛。
shortcut的恒等映射
一般一层的残差模块可以表示为如下公式,这里x和y分别是某一层输入和输出的向量,函数F(x, {Wi})表示要学习的残差映射。
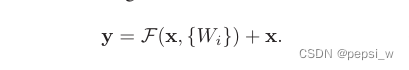
这里的shortcut connection既没有引入额外的参数,也没有引入计算的复杂性。但当改变输入/输出通道时,我们可以通过shortcut connection进行线性投影Ws,以匹配尺寸。

网络结构
作者这里使用了两个模型进行对比,一个是没有使用残差块的plain network,该网络基于左边的VGG网络进行设计,另 一个基于该普通网络加上shortcut connection。当输入输出通道数没有改变时,使用上面的第一个公式,当输入输入通道数增加时,采取两种方法:1)直接使用0来对增加的通道进行填充,在图中以实线来表示,这个方法没有引入额外的参数。2)使用第二个公式来进行通道数的匹配(具体通过1✖1的卷积来完成),在图中以虚线进行表示。具体结构如下:

实验结果
1,ImageNet 2012数据集
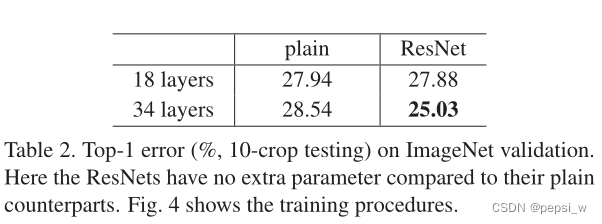
分别使用18层和34层的plain network进行实验,结果如下图所示。图中虚线表示在训练集误差,实现表示测试集上的误差。可以看出,这里34层的plain network无论在训练集还是测试集上的误差都高于18层的网络。并且残差网络层数越深效果越好,残差网络比plain network收敛更快。

具体数字如下表所示,这里的ResNet中对于通道数增加的shortcut connection选择第一种方式,即用0来进行填充。18层的plain network 和残差网的精度相当,但18层的ResNet收敛得更快(由上图可知)。当网 "不是太深 "时(这里是18层),目前的SGD求解器仍然能够找到平原网的良好解决方案。在这种情况下,ResNet通过在早期阶段提供更快的收敛来缓解优化。
作者还对shortcut connection增加通道的不同方式进行了对比,ResNetA表示使用0来进行填充,ResNetB表示对于通道数增加的层数使用1✖1的卷积来进行投影。ResNetC表示所有层都使用1✖1的卷积来进行投影。可以看出C的结果略好于A和B,作者认为这是投影捷径所引入的额外参数导致的。

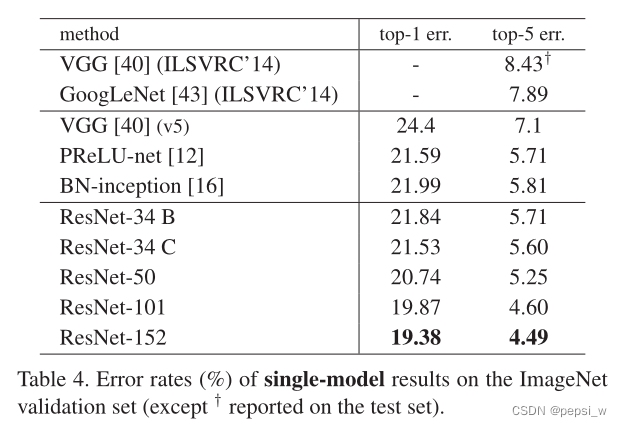
作者将ResNet18和Resnet34种残差层的两个3*3的卷积,换成了一个两个1*1和一个3*3的卷积,得到一个50层的ResNet

这些模型在ImageNet验证误差如下表所示,可以看出,Resnet的层数越深,得到的效果越好。
2,CIFAR-10数据集
作者还在CIFAR-10这个数据集上对不同深度的plain network和ResNet进行了实验,结果如下所示。(该数据集较小,跑起来更加的容易,通过在该数据集上的表现来看这个更深网络的具体内容( Our focus is on the behaviors of extremely deep networks))

下图显示了各层响应的标准偏差,即每个3×3层的输出,在BN之后和其他非线性(ReLU/添加)之前。对于ResNets,这种分析揭示了残差函数的响应强度。可以看出ResNets的反应通常比对应得plain network要小,即残差函数通常可能比非残差函数更接近于零。另外较深的ResNet的反应幅度较小。

3,PASCAL和MS COCO
作者最后还提出该网络在目标检测方面也有一个较好的效果,如下表所示:

总结
该论文提出了一种残差块结构,解决了在深度神经网络中由于梯度消失或梯度爆炸导致的网络难以训练的问题,以及更深的层次反而导致网络性能下降问题。














 702
702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









