







原文链接:https://aclanthology.org/P17-1152.pdf
ACL 2017
概述
对于自然语言推理任务,Bowman等人在2015年提出了一个大数据集,大多数工作就开始使用神经网络来对该任务进行训练。但作者认为序列模型的潜力还没有完全被挖掘,因此提出了一个基于chain LSTMs的序列模型,该模型比先前的模型效果都要好,另外融合循环结构后,性能得到进一步提升,特别是在纳入语法信息后达到了最好的结果。
介绍
自然语言推理(NLI)中一个任务是RTE(recognize textual entailment),就是判断两个句子之间的关系,存在三种情况:矛盾、无关以及蕴含。实际就是看在给定前提p的情况下,能不能推出假说h。例如以下例子:

前提p中表示部分航空公司发现即使调整了通货膨胀后成本增长仍高于预期,从中是可以推测出h这个假说的。
另外,作者认为语法和语义是密切相关的,所以在本文中作者也探究了语法信息对NLP任务的作用,讲语法信息进行编码融入到模型中。
方法
作者提出的模型结构主要包括:input encoding、local inference modeling和inference composition。如下图所示,左部分就是前面提到的序列模型ESIM(主要是使用语义信息来进行训练),右部分是在tree LSTMs中融合了语法信息的结构(主要是用语法信息来进行训练)。(可以只使用ESIM,也可以达到很好的效果,在加入了右边语法信息的结果后,结果会更好。如果两个模型都使用,作者称为HIM)
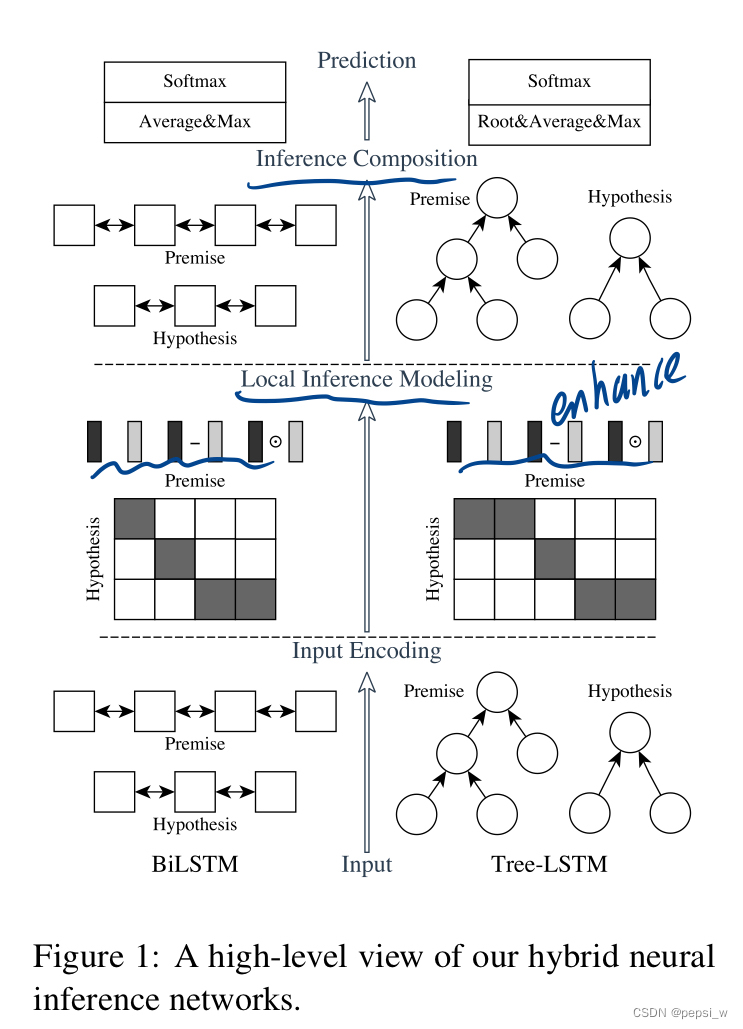
premise a=(a1,,,ala),hypothesis b=(b1,,,blb),通过预训练的模型对其embedding进行初始化,最后得到两个句子逻辑关系之间的label y。
Input Encoding
作者将双向LSTM(BiLSTM)和Tree-LSTM作为两个模型的基本结构块,但在input encoding部分和inference information部分中有着不同的作用。
在ESIM中,使用BiLSTM来对输入的句子premise和hypothesis进行编码,文中对BiLSTM的具体结构没有进行具体介绍,实际就是将两个不同方向LSTM的隐状态进行concat作为最终的隐状态,另外作者提到这里使用其他循环记忆块(例如GRUs)进行代替的话,效果没有LSTMs好。
如下所示,使用表示BiLSTM对输入句子a在时间步i的隐藏状态,对b也同理。
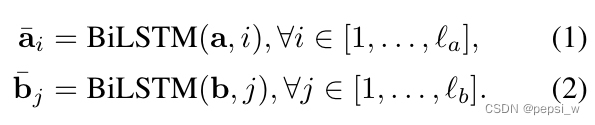
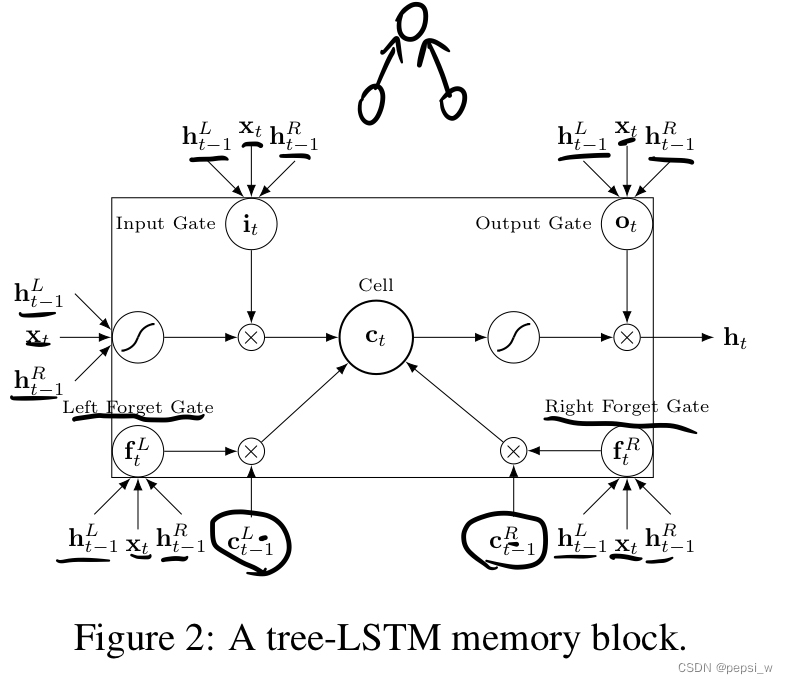
对于语法信息,使用树状的LSTM来对节点进行更新。在每个节点中,将向量Xt以及其左右子节点的隐状态作为输入计算该节点的隐向量ht,对于没有叶子的节点,使用(类似于unknown word)作为输入。具体结构以及计算公式如下图所示:
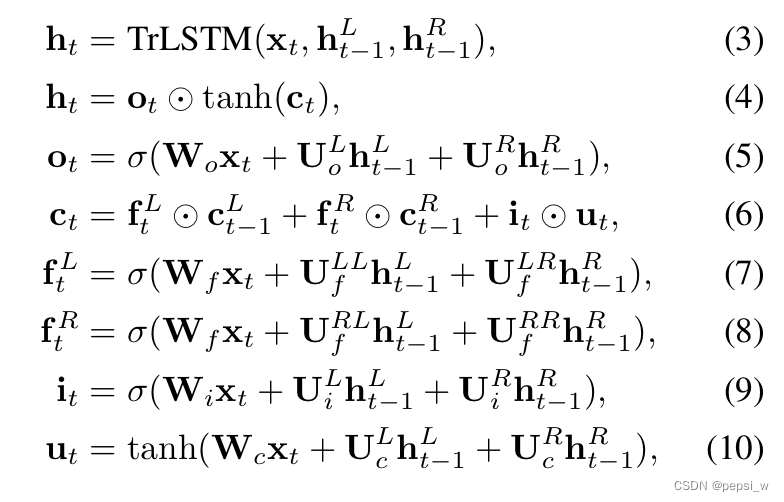
其中表示sigmoid函数,W,U都是可学习的权重矩阵。
Local Inference Modeling
感觉这部分就是得到词与词之间的soft attention,ESIM得到词与词之间语义信息的权重,而另一个使用语法信息的模型得到词与词之间语法关系的权重。
在本文中,计算premise和hypothesis之间的相似度:
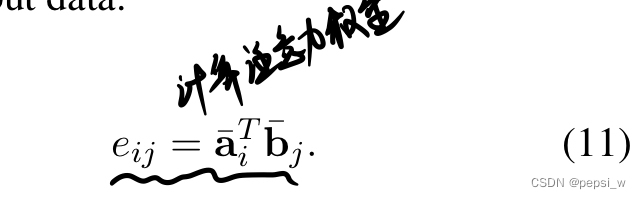
在ESIM中,将上诉相似度eij用于premise中单词的隐状态和hypothesis中相关的语义信息计算,即使用
中相关的向量来表示
。

在语法树中,是对PCFG语法分析器(相关链接:使用Stanford Parser的PDFG算法进行句法分析 - 灰信网(软件开发博客聚合))得到局部短语以及从句的关系进行注意力分数计算。与ESIM中差不多,只是将和
(前提和假说中的embedding)替换成tree-LSTM中对应叶节点的隐状态(由公式3计算得到)。
为了使得元祖中元素之间关系(标签中的三种,矛盾、无关、蕴含)更加明显,作者将和
的差值和点积进行与其自身进行concat,对得到的local inference 信息进行增强:
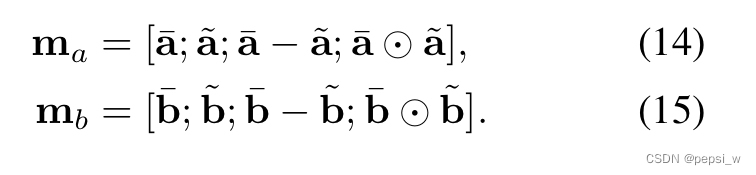
作者认为这是一种高层次的信息交互,另外,作者也将该元祖作为输入,传入一个前馈神经网络中,将最后一层的隐状态添加到上诉concatenation中,但实验结果表明这并没什么用。
Inference Composition
在ESIM中依旧使用BiLSTM对ma和mb的上下文信息进行捕获,计算与前面的公式1和公式2类似。另一个模型中,使用以下公式进行树节点的更新:
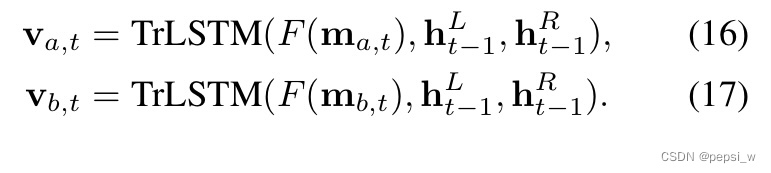
为了减少计算量,这里的F是只有一层带有ReLu激活函数的前馈神经网络。
最后通过一个pooling层后传入到分类器中对最终结果进行推测,本文中作者使用了avg和max两种pooling方式,如下所示(对于树结构的模型,在公式20中使用根结点的隐状态进行计算):
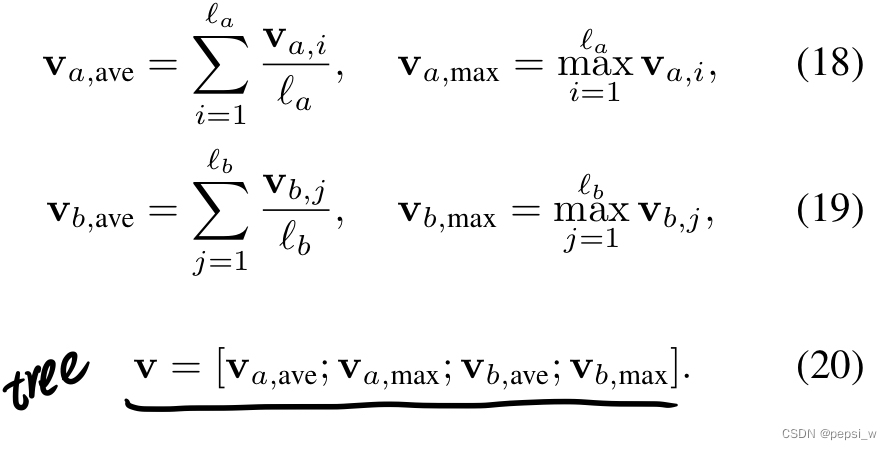
整个模型使用多分类的交叉墒损失来进行训练。可以只使用ESIM模型的结果,也可以对两个模型最后的预测结果进行赋权来得到最后的结果。
实验
本文实验使用Bowman等人在2015年提出的SNLI(Stanford Natural Language Inference)数据集,移除了其中一些无法确定的数据。与之前提出的模型进行对比,实验结果如下:

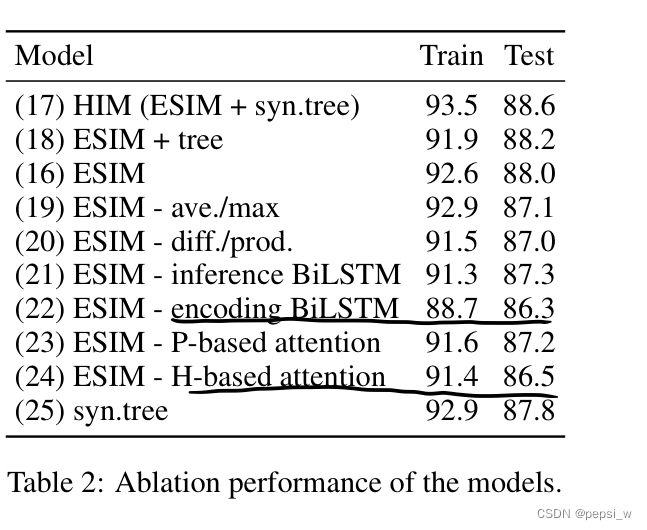
作者对模型中的主要部分进行了消融实验,结果如下:
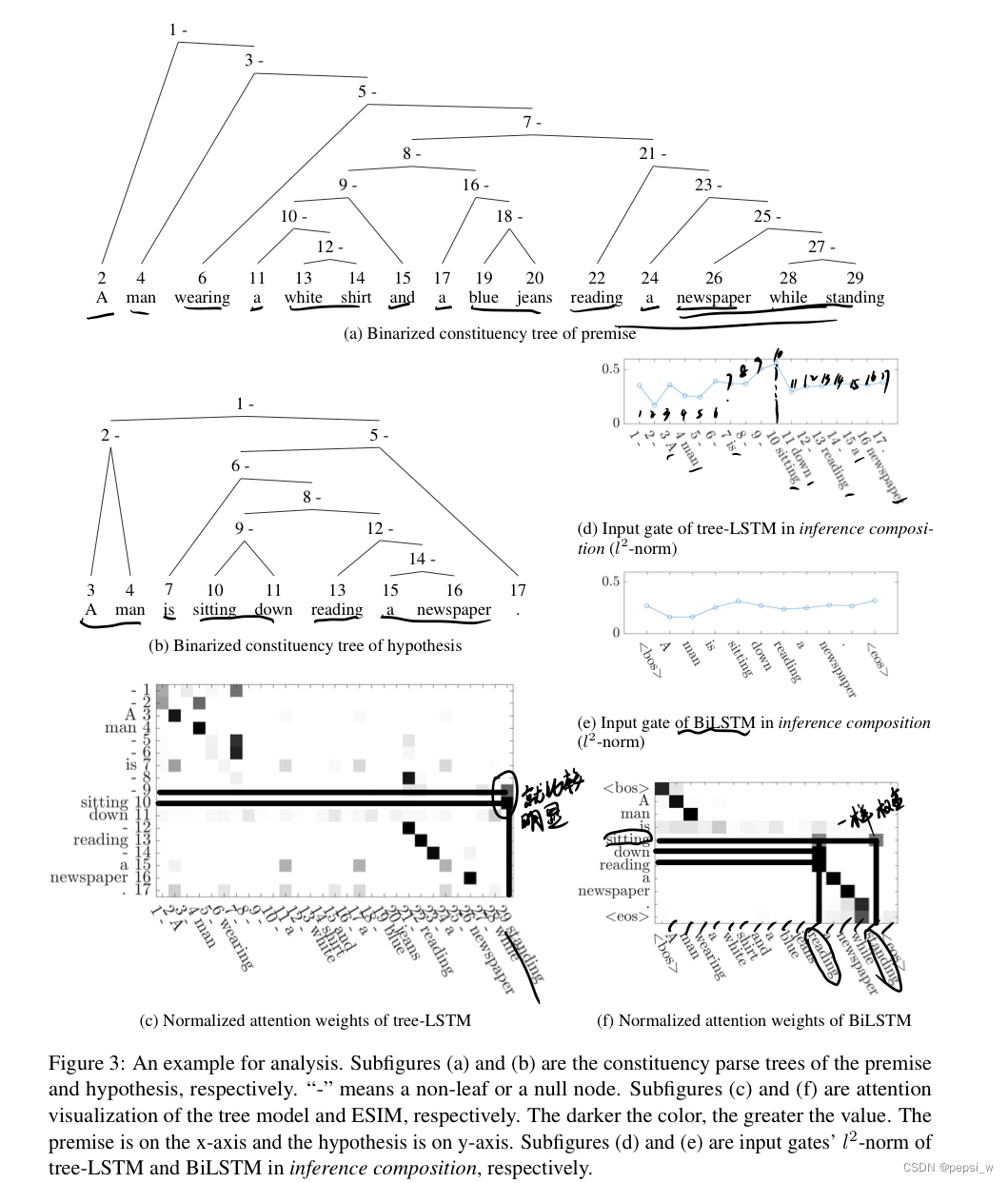
作者对Tree-LSTM和BiLSTM中各个词之间的注意力分数进行了可视化和分析:
总结
本文提出了一个序列模型,在SNLI数据集上达到了目前最好的效果,在结合语法信息后达到效果会更好。作者认为序列模型的潜力害没有完全被发掘出来,未来将进一步探索使用额外信息(例如Word-Net和contrasting-meaning embedding)来帮助词级别的推理关系。
(不知道为啥,这篇论文看完后花了接近一天的时间来写这篇博客,其实模型也不是很难,可能是我表述能力的问题吧!就是我能大概知道这个模型是怎么训练的,但是跟着论文来写一遍的时候还是会很慢很慢🥹)















 748
748











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









