








用于自然语言推理的增强型 LSTM
github: https://github.com/daiyizheng/shortTextMatch/blob/master/src/DL_model/classic_models/models/ESIM.py
本文作者提出了基于LSTM的ESIM模型,该模型优于之前所有的模型。ESMI主要通过链式LSTM(作者也提到了Tree LSTM结构的模型HIM,但是不是重点)与注意力结合的模型,是一个十分复杂但效果在当时很不错的模型。paper用到的数据集是SNI语料库,包含了两个句子和一个标签,这两个句子和标签分表示premise和hypothesis以及0(或者1)。ESIM模型通过预测两个句子的逻辑来判断其之间的关系。
ESIM模型主要由一下组件构成:
(1) input encoding(输入编码)
(2) local inference modeling(局部推理建模)
(3) inference composition(推理组件)

Input Encoding
使用双向LSTM(BiLSTM)作为NLI的基本构建模块之一。使用它来编码输入的premise和hypothesis,可以获得BiLSTM编码局部推理信息及其相互作用。公式如下:
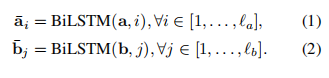
作者也使用了其他的LSTM变种模型,如GRU,但是效果不如LSTM。
Local Inference Modeling
对premise和hypothesis之间的局部次句推理进行建模是确定这两种陈述之间的整体推理的基本组成部分。
在做局部推理之前,需要将两个句子对齐,目前对齐方式有硬对齐或软对齐来关联premise和hypothesis之间的相关性。
本文作者使用软注意对齐层来计算, 通过将注意力权重计算为premise和hypothesis之间的隐藏状态
t
u
p
l
e
<
a
i
‾
,
b
j
‾
>
tuple<\overline{a_i}, \overline{b_j}>
tuple<ai,bj>的相似性。
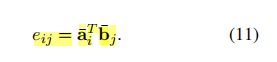
局部推理由上述计算出的注意权重
e
i
j
e_{ij}
eij决定,用于获得premise和hypothesis之间的局部相关性。然后进行两句话的局部推理,用之前得到的相似度矩阵,结合 a,b 两句话,互相生成彼此相似性加权后的句子,维度保持不变。如下公式:
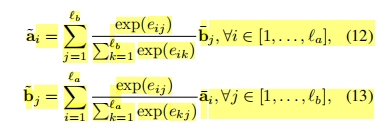
作者使用通过计算
t
u
p
l
e
<
a
‾
,
a
~
>
tuple<\overline{a} ,\widetilde{a}>
tuple<a,a
>以及
t
u
p
l
e
<
b
‾
,
b
~
>
tuple<\overline{b} , \widetilde{b}>
tuple<b,b
>的差值和元素级乘积。来增强局部推理信息。最后将四种向量拼接在一起,得到
m
a
,
m
b
m_a, m_b
ma,mb。如下公式:
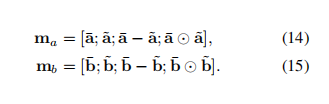
Inference Composition
这里作者再一次使用了LSTM对上下文进行推理. 其中,作者使用了不同的池化操作,包括MaxPooling 和 AvgPooling,最后接一层全连接层.
注意,作者没有使用SumPooling的原因是:模型对序列长度敏感,因此不鲁棒。

结论
作者提出了用于自然语言推理的神经网络模型,它获得了在SNLI基准测试上报告的最佳结果。结果该模型优于以前的模型,包括那些使用更复杂的网络架构的模型,这表明序列推理模型的潜力尚未得到充分利用。
















 976
976











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











