







原文链接:
https://aclanthology.org/2021.naacl-main.5.pdf
ACL 2021
介绍
对于命名实体识别和关系提取,最近的研究要么在这两个任务上使用一个预训练结构,要么通过共享表征来进行多任务学习。作者认为实体模型和关系模型在上下文表征中学到了不同的信息,共享它们的表征会降低性能,因此探索了pipeline模型在该领域上的潜力。
作者将现有的联合模型分为两类:结构化预测和多任务学习。1)结构化预测方法将这两项任务放到一个统一的框架中,将原本的两个任务变成一个待解决的全局优化问题,并且在推理的时候使用束搜索或者强化学习来进行联合解码;2)多任务学习部分的模型建立两个模型用于实体识别和关系抽取,通过共享参数来进行优化。
方法
如下图所示,作者提出的方法主要包括两个模型:Entity model和Relation model。其中Entity model首先对输入的句子中的每一个span实体类型进行预测。在Relation model中对每一对候选实体独立地进行处理,插入额外的marker token,来强调主体、客体及其类型。
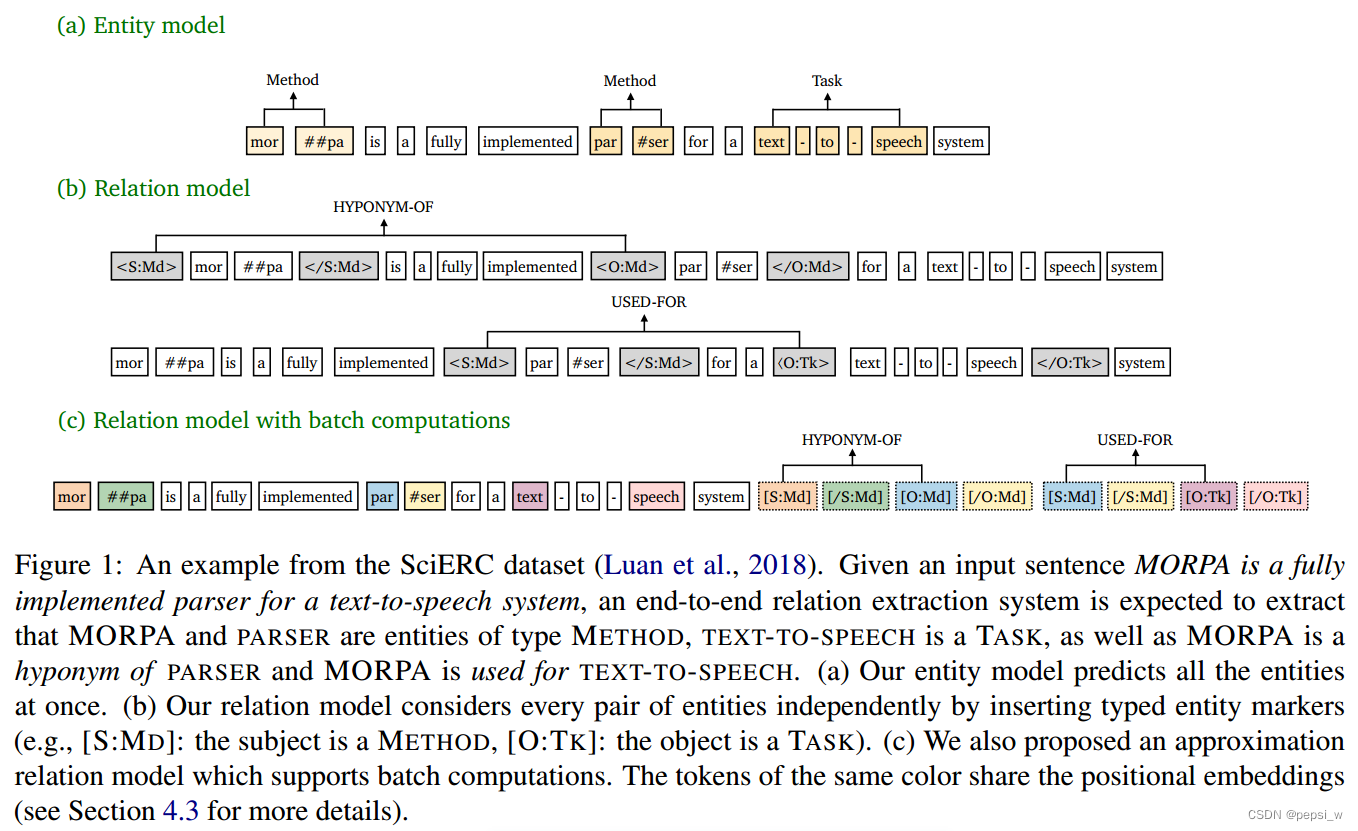
Entity model
实体模型是一个标准的跨区域(span-based)模型。对于输入的每个token(),使用预训练语言模型(如Bert)来得到一个包含上下文的表征
。一个跨度
的表征
的定义如下所示,其中
表示学到的具有跨度特征的embedding。
![]()
被送入到一个前馈神经网络来预测实体类型的分数。
Relation mode
关系模型就是预测输入的每对span之间的关系。作者认为这些表征都只能获取到每个独立实体周围的上下文特征,不能捕捉到这对span之间的关系,因此在不同的span上共享上下文表征可能是次优的。
与其它独立地处理每对span,并在输入层插入typed marker来强调主体、客体以及它们之间关系的模型不同。如上图中Relation mode中所示,具体的:
X表示输入的序列,一对主客体spans 、
的类型分别是
、
。定义文本marker
、
、
、
,将其插入到主体和客体的起始位置。
表示修改后的序列:
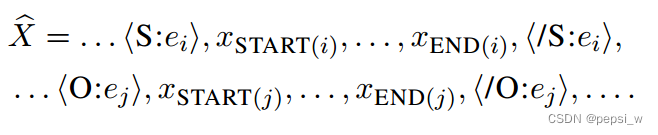
将作为输入送入到第二个预训练好的encoder,用
表示输出的表征,将两个起始位置的输出进行concate,来得到跨度对的表征。
![]()
最后将这个表征送入到一个前馈神经网络来预测关系类型的分数。
虽然使用额外的标记来强调主客体的方法不是一个很大的创新点,因为在之前的关系分类任务中,该方法就已经被提及。但是大多数的关系分类任务只关注与在输入序列中给定的主客体对,其有效性还没有在端到端的设置中得到评估,而且之前端到端的模型仅通过使用辅助loss的方法来将实体关系信息映射到关系模型中。
Cross-sentence context
目前存在不少工作使用cross-sentence来提高模型的性能,由于预训练模型能够独立的捕获到较远范围内的信息,作者在实体模型和关系模型中仅通过一个固定大小的窗口来获取上下文的cross-sentence,即输入一个有n个词的句子,分别用前后文中的(W-n)/2个词来增加输入。
Training & inference
对于实体模型和关系模型,使用特定任务损失来对预训练模型进行微调,并两个模型都使用交叉熵损失:
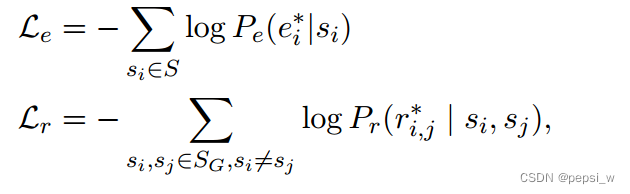
其中、
分别表示
的真实类别和
的真实关系。
Differences from DYGIE++
作者还与DYGIE++模型进行了对比,存在以下差异:
1)对实体模型和关系模型分别使用分开的encoder,而不是通过多任务学习的方式。
2)关系模型中的上下文表征通过使用text marker针对每一对span
3)对于cross-sentence,没有应用图传播和束搜索等方法,仅通过扩展其他额外信息来进行融合。
因此作者提出的模型更简单,并且效果也不错。
Efficient Batch Computations
由于本文提出的模型对于每对span都是独立地插入实体标记,但作者想要在同一句子中的不同span,只进行一次计算,于是在原始模型上进行了两个修改来实现近似计算。
1)不再将实体标记直接插入到原始句子中,而是将marker的位置编码与相应span的开始结束token联系起来。
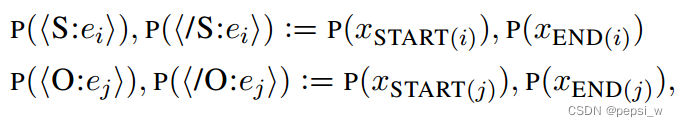
2)在注意力层增加了一个约束,使得文本token只关注文本token而不去关注mark token,而实体marker token能够关注所有的文本token 以及同一个span的四个mark 标记。这样一来,就能重复利用所有文本token的计算,即只需运行一次关系模型就能对同一句子中的多span进行批量处理。如图1中c部分所示,将所有mayker标记添加到句子末尾,形成批量处理一系列span的输入。

实验
对比实验
作者提出的PURE与其他模型的在ACE05、ACE04、SciERC三个数据集中进行实验,结果如下所示:
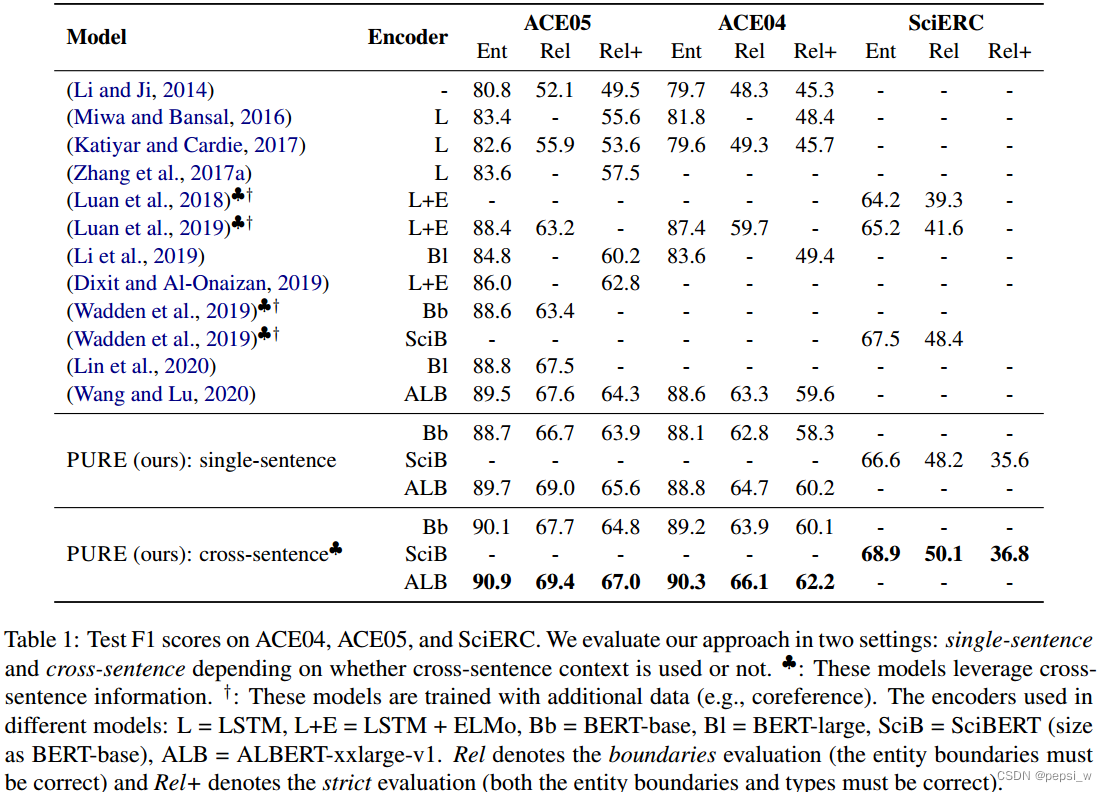
可以看出作者提出的PURE比之前的模型在各个数据集上表现都要好,在使用cross-sentence后,更是得到了进一步的提高。对于实体识别,作者提出的模型在这三个数据集上分别有1.4%、1.7%、1.4%的提升,表明cross-sentence信息对于实体模型是有帮助的,并且预训练的transformer encoder 能够独立地从大文本中捕获较长范围内的信息。比起之前使用全局特征和复杂的网络结构实现的最好效果,作者提出的模型更加简单,并且在三个数据集上都有了较大的提升。
对文中提出的近似计算进行了实验,结果如下所示:
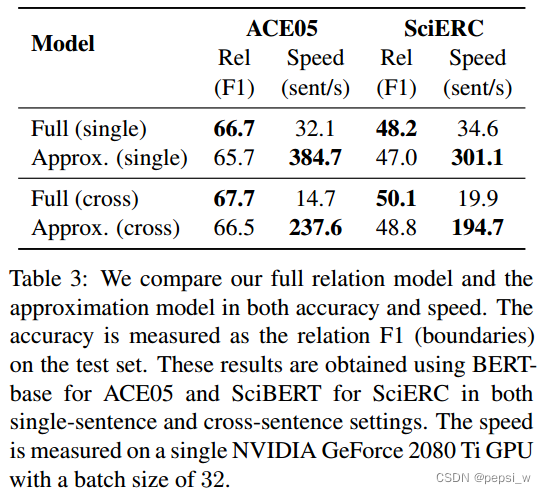
可以看出近似计算的速度提高了10倍左右,并且F1最多下降了1.2%。
消融实验
对输入的不同变体(即使用不同的marker 形式)进行了实验,结果如下所示:
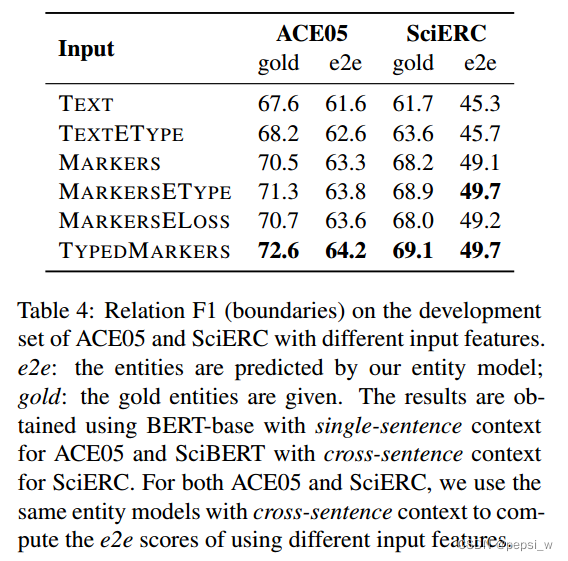
不同的marker token比标准的text表征效果要好,表明针对不同的spans学习不同表征的重要性。
联合模型的一个主要论点就是,将两个任务之间的交互进行建模能够得到更好的效果。作者对本文提出的模型是否也存在这样的情况进行了实验,结果如下所示。
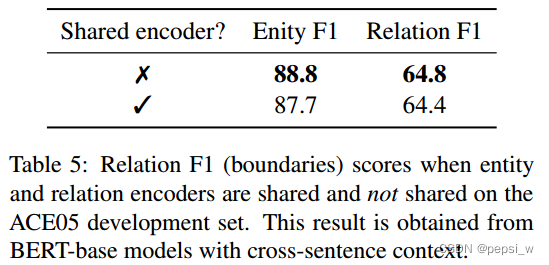
结果表明只是简单的共享encoder会损害两个任务上的F1,作者认为这是1因为两个任务拥有不同的输入形式,要求不同的特征。因此使用两个单独的encoder能够更好的学习特定任务的特征。
对cross-sentence中的窗口W的大小进行了实验,结果如下所示:
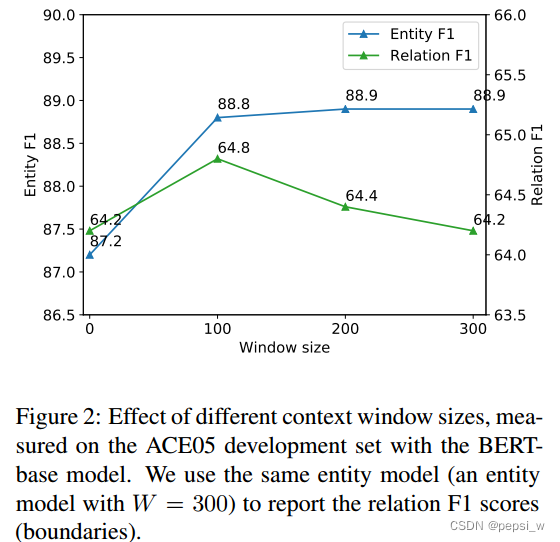
在实体模型中,w=300时,效果最好;关系任务中,w=100效果最好。
缓解误差传播的尝试
pipeline模型存在误差传播的问题,在本文的模型中,训练关系模型使用正确的实体,在推理时使用实体模型预测出的实体,这可能会导致训练和测试之间的矛盾。作者尝试了一些方法来解决这个问题:
1)首先研究在训练阶段也使用预测的实体是否能够缓解这个问题,作者使用十倍的交叉验证,结果该方法还损害了模型的性能,作者猜测是因为在训练过程中引入了额外的噪音。(实验具体结果如后所示)
2)考虑在训练和测试时,在关系模型中使用更多span。主要是因为目前的pipline方法,如果正确的实体并不够完整(就是没有推理出来的多),关系模型就没办法得到所有可能的关系。使用束搜索时,系数为0.4时效果最好。因此还探索了几种不同关系模型中的span编码方式。结果如下所示,可以看见这些改变都没有带来什么提升。

总结
本文作者提出了一个pipeline的模型PURE,相对于之前的jointly模型更加简单高效,(也算是为pipeline扳回一局吧)。感觉全文的创新点好像不是很突出(个人拙见),但是实验部分比较完善的,争对pipeline的传播误差问题,也尝试了两种方法,虽然好像并没有什么效果,但是感觉作者的工作还量还挺多的。


















 3118
3118

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









