




 本文介绍了如何在AWS上实施数据仓库解决方案,参考了一篇来自Towards Data Science的文章,涵盖了相关技术和步骤。
本文介绍了如何在AWS上实施数据仓库解决方案,参考了一篇来自Towards Data Science的文章,涵盖了相关技术和步骤。
aws数据仓库
In past posts, I’ve been talking about Data Warehouses, their basic architecture, and some basic principles that can help you to build one. Today, I want to show you an implementation of Data Warehouse on AWS based on a case study performed a couple of months ago.
在过去的文章中,我一直在谈论数据仓库,其基本体系结构以及一些可以帮助您构建数据仓库的基本原理。 今天,我想根据几个月前进行的案例研究,向您展示AWS上Data Warehouse的实现。
This implementation uses AWS S3 as the Data Lake (DL). AWS Glue as the Data Catalog. And AWS Redshift and Redshift Spectrum as the Data Warehouse (DW).
此实施使用AWS S3作为数据湖(DL)。 AWS Glue作为数据目录。 并将AWS Redshift和Redshift Spectrum用作数据仓库(DW)。
Note: This post can be confusing if you are not familiar with some of the terminology and concepts I’m using here. For further information about this terms and concepts I recommend you to take a look to other posts where these topics are addressed.
注意:如果您不熟悉我在这里使用的一些术语和概念,那么这篇文章可能会造成混淆。 有关此术语和概念的更多信息,建议您查看解决这些主题的其他文章。
建筑 (Architecture)
The architecture followed in this implementation is based on ELT processes. First, the data is extracted from sources, then is loaded into the Data Lake, and finally is transformed in the Data Warehouse.
此实现中遵循的体系结构基于ELT流程。 首先,从源中提取数据,然后将其加载到Data Lake中,最后在Data Warehouse中进行转换。
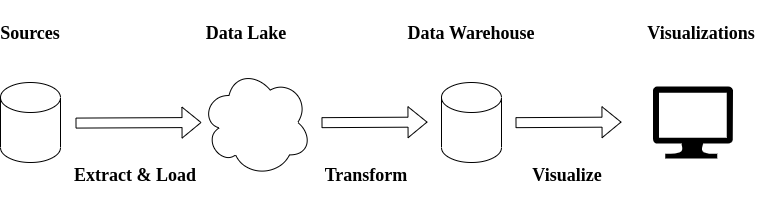
The implementation addressed in this post is based on a case study performed a couple of months ago — for more information check this post. The architecture looks like this:
这篇文章中介绍的实现基于几个月前进行的案例研究-有关更多信息,请查看这篇文章。 该架构如下所示:
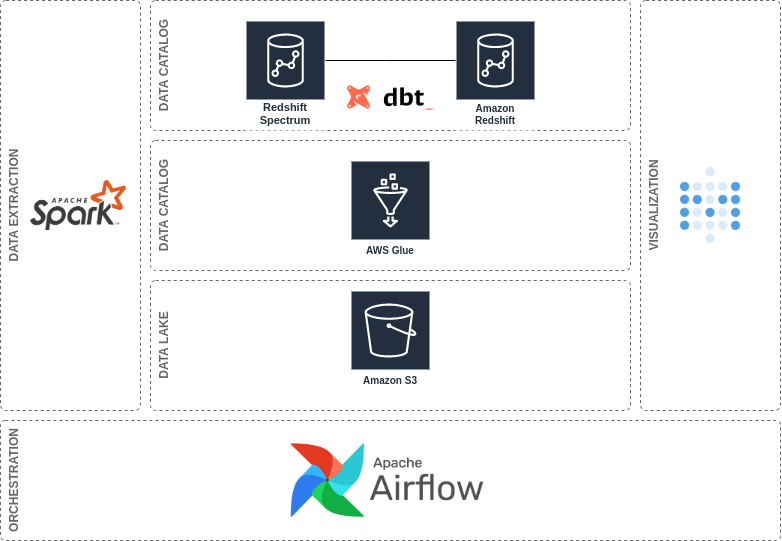
It uses AWS S3 as the DL. AWS Glue as the Data Catalog. And AWS Redshift and Redshift Spectrum as the DW.
它使用AWS S3作为DL。 AWS Glue作为数据目录。 而AWS Redshift和Redshift Spectrum作为DW。
Also, it uses Apache Spark for data extraction, Airflow as the orchestrator, and Metabase as a BI tool. But, particularly for this post, the scope is limited to the implementation of the DL and DW.
此外,它使用Apache Spark进行数据提取,使用Airflow作为协调器,使用Metabase作为BI工具。 但是,特别是对于此职位,范围仅限于DL和DW的实施。
数据湖 (Data Lake)
The first part of this case study is the Data Lake.
本案例研究的第一部分是数据湖。
A Data Lake is a repository where data from multiple sources is stored. It allows for working with structured and unstructured data.
Data Lake是一个存储多个来源数据的存储库。 它允许处理结构化和非结构化数据。
In this case study, the Data Lake is used as a staging area allowing for centralizing all different data sources.
在本案例研究中,Data Lake用作暂存区域,可以集中所有不同的数据源。
The data coming from these sources is stored in its original format. There are no transformation processes involved before loading the data into the Data Lake. So, it can be considered as an immutable staging area.
来自这些来源的数据以其原始格式存储。 将数据加载到Data Lake中之前,无需进行任何转换过程。 因此,可以将其视为不变的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 613
613

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









