






一、fer2013数据集介绍
-
数据规模:FER-2013数据集包含大约35,000张人脸图像,这些图像被标注了情感。
-
情感类别:数据集中的图像被分为七种基本情感类别:愤怒(Angry)、厌恶(Disgust)、恐惧(Fear)、快乐(Happy)、悲伤(Sad)、惊讶(Surprised)和中性(Neutral)。
-
多样性:数据集中的图像涵盖了不同年龄、性别和种族的人脸,这有助于训练更为泛化的情感识别模型。
-
标注:除了情感标注外,FER-2013数据集还提供了一些其他的面部属性标注,例如戴不戴眼镜、是否有胡须等。
-
图像质量:图像质量参差不齐,有些图像较为清晰,而有些则可能由于来源不同而质量较低。
-
研究应用:FER-2013数据集被广泛用于多种面部表情识别的研究中,包括深度学习模型的训练和验证。
-
数据集划分:通常,FER-2013数据集被分为训练集、验证集和测试集,以便研究人员可以训练和评估他们的情感识别模型。
-
挑战:FER-2013数据集中的挑战包括表情强度的变化、部分遮挡、图像尺度和方向的变化等。
-
获取方式:FER-2013数据集是公开的,可以通过其官方网站或研究论文提供的链接下载。
-
使用限制:尽管数据集是公开的,但在使用时仍需遵守相关的使用条款和条件,尤其是在商业用途中。
二、数据集处理
1、实验数据集
Fer2013人脸表情数据集由35886张人脸表情图片组成,其中,测试图(Training)28708张,公共验证图(PublicTest)和私有验证图(PrivateTest)各3589张,每张图片是由大小固定为48×48的灰度图像组成,共有7种表情,分别对应于数字标签0-6,具体表情对应的标签和中英文如下:0 anger 生气; 1 disgust 厌恶; 2 fear 恐惧; 3 happy 开心; 4 sad 伤心;5 surprised 惊讶; 6 normal 中性。

2、数据整理
(1)数据给的是一个csv文件,其中的表情数据并没有直接给图片,而是给了像素值,将fer2013.csv文件通过dataset_prepare.py文件转化为图片
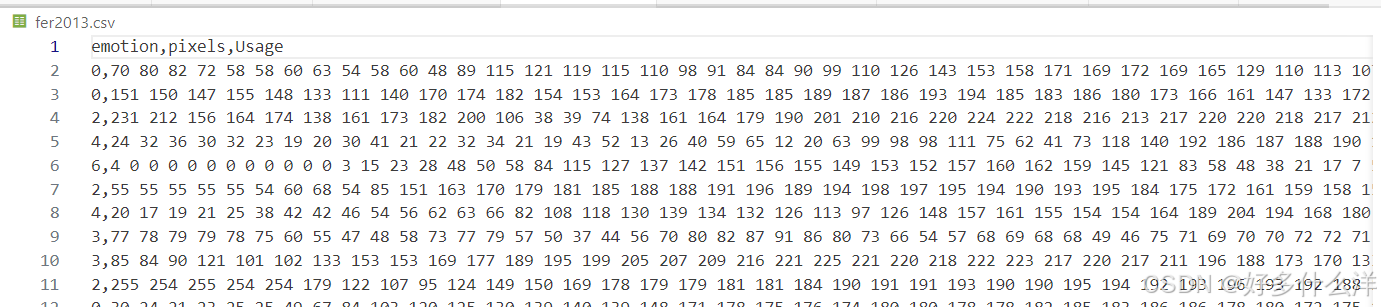

运行后的文件结构如下所示:
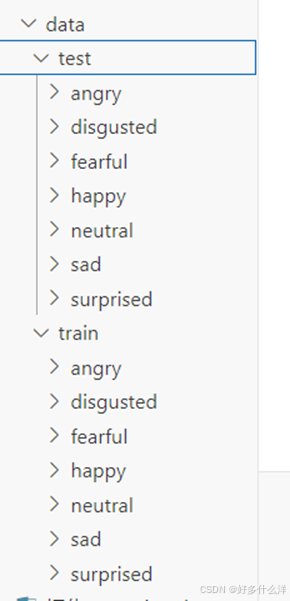
(2)修改训练集和验证集的路径

三、基于tensorflow模型训练
1、网络结构

上述是代码的卷积神经网络 ,结构如下:
- 输入层:接受48x48像素的灰度图像。
- 卷积层x3:包含三个卷积层,使用32、64和128个过滤器,卷积核大小为3x3,ReLU激活函数。
- 最大池化层x3:每个卷积层后面跟着一个2x2的最大池化层。
- Dropout层x2:在卷积层之后有两个Dropout层,丢弃率分别为0.25和0.5,用于正则化。
- 全连接层:一个具有1024个神经元的全连接层,ReLU激活函数。
- 输出层:一个具有7个神经元的全连接层,使用softmax激活函数,输出7种情绪的概率。
2、主要代码
ps:运行代码训练
python xxx.py --mode train
import numpy as np
import argparse
import matplotlib.pyplot as plt
import cv2
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten, Conv2D, MaxPooling2D
from tensorflow.keras.optimizers import Adam
from keras.preprocessing.image import ImageDataGenerator
import os
os.environ['TF_CPP_MIN_LOG_LEVEL'] = '2'
ap = argparse.ArgumentParser()
ap.add_argument("--mode", help="train/display")
mode = ap.parse_args().mode
def plot_model_history(model_history):
fig, axs = plt.subplots(1,2,figsize=(15,5))
axs[0].plot(range(1,len(model_history.history['accuracy'])+1),model_history.history['accuracy'])
axs[0].plot(range(1,len(model_history.history['val_accuracy'])+1),model_history.history['val_accuracy'])
axs[0].set_title('Model Accuracy')
axs[0].set_ylabel('Accuracy')
axs[0].set_xlabel('Epoch')
axs[0].set_xticks(np.arange(1,len(model_history.history['accuracy'])+1))
axs[0].legend(['train', 'val'], loc='best')
axs[1].plot(range(1,len(model_history.history['loss'])+1),model_history.history['loss'])
axs[1].plot(range(1,len(model_history.history['val_loss'])+1),model_history.history['val_loss'])
axs[1].set_title('Model Loss')
axs[1].set_ylabel('Loss')
axs[1].set_xlabel('Epoch')
axs[1].set_xticks(np.arange(1,len(model_history.history['loss'])+1))
axs[1].legend(['train', 'val'], loc='best')
fig.savefig('plot.png')
plt.show()
train_dir = r'C:\Users\w\OneDrive\桌面\课程实习2024\data\train'
val_dir = r'C:\Users\w\OneDrive\桌面\课程实习2024\data\test'
num_train = 28709
num_val = 7178
batch_size = 64
num_epoch = 200
train_datagen = ImageDataGenerator(rescale=1./255)
val_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(48,48),
batch_size=batch_size,
color_mode="grayscale",
class_mode='categorical')
validation_generator = val_datagen.flow_from_directory(
val_dir,
target_size=(48,48),
batch_size=batch_size,
color_mode="grayscale",
class_mode='categorical')
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3), activation='relu', input_shape=(48,48,1)))
model.add(Conv2D(64, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(128, kernel_size=(3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(1024, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(7, activation='softmax'))
if mode == "train":
model.compile(loss='categorical_crossentropy',optimizer=Adam(lr=0.0001, decay=1e-6),metrics=['accuracy'])
model_info = model.fit(
train_generator,
steps_per_epoch=num_train // batch_size,
epochs=num_epoch,
validation_data=validation_generator,
validation_steps=num_val // batch_size)
plot_model_history(model_info)
model.save_weights(r'C:\Users\w\OneDrive\桌面\课程实习2024\模型训练历史\model_20.h5')
elif mode == "display":
model.load_weights(r'C:\Users\w\OneDrive\桌面\课程实习2024\模型训练历史\model_20.h5')
cv2.ocl.setUseOpenCL(False)
emotion_dict = {0: "Angry", 1: "Disgusted", 2: "Fearful", 3: "Happy", 4: "Neutral", 5: "Sad", 6: "Surprised"}
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
facecasc = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = facecasc.detectMultiScale(gray,scaleFactor=1.3, minNeighbors=5)
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y-50), (x+w, y+h+10), (255, 0, 0), 2)
roi_gray = gray[y:y + h, x:x + w]
cropped_img = np.expand_dims(np.expand_dims(cv2.resize(roi_gray, (48, 48)), -1), 0)
prediction = model.predict(cropped_img)
maxindex = int(np.argmax(prediction))
cv2.putText(frame, emotion_dict[maxindex], (x+20, y-60), cv2.FONT_HERSHEY_SIMPLEX, 1, (255, 255, 255), 2, cv2.LINE_AA)
cv2.imshow('Video', cv2.resize(frame,(1600,960),interpolation = cv2.INTER_CUBIC))
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
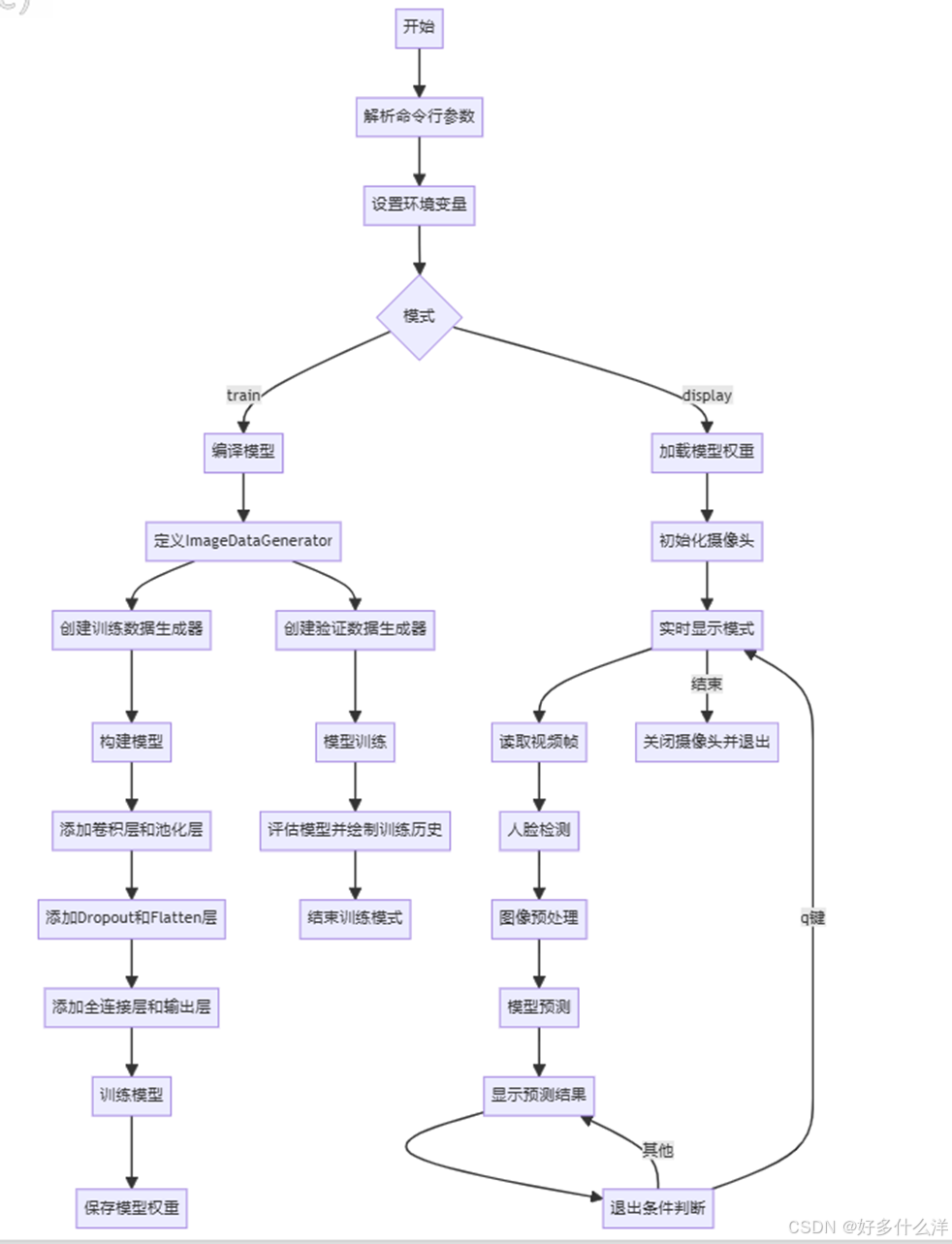
cv2.destroyAllWindows()代码实现了基于tensorflow框架的深度学习情感识别系统,具有两种操作模式:"train" 和 "display",如下是代码的流程图。
3、模型训练
①epoch=20:从acc曲线和loss曲线看,随着epoch增大,准确率在提高,决定调大epoch观察训练集和测试集上的loss及acc
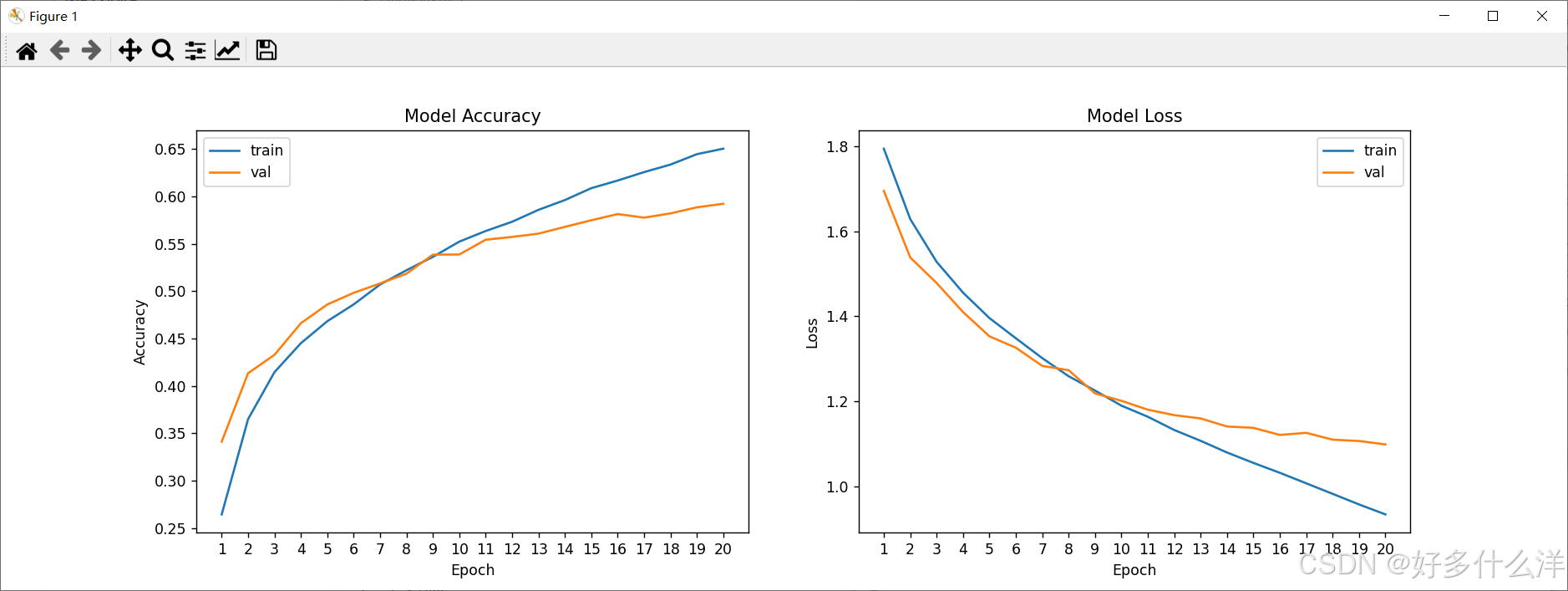
②epoch=200
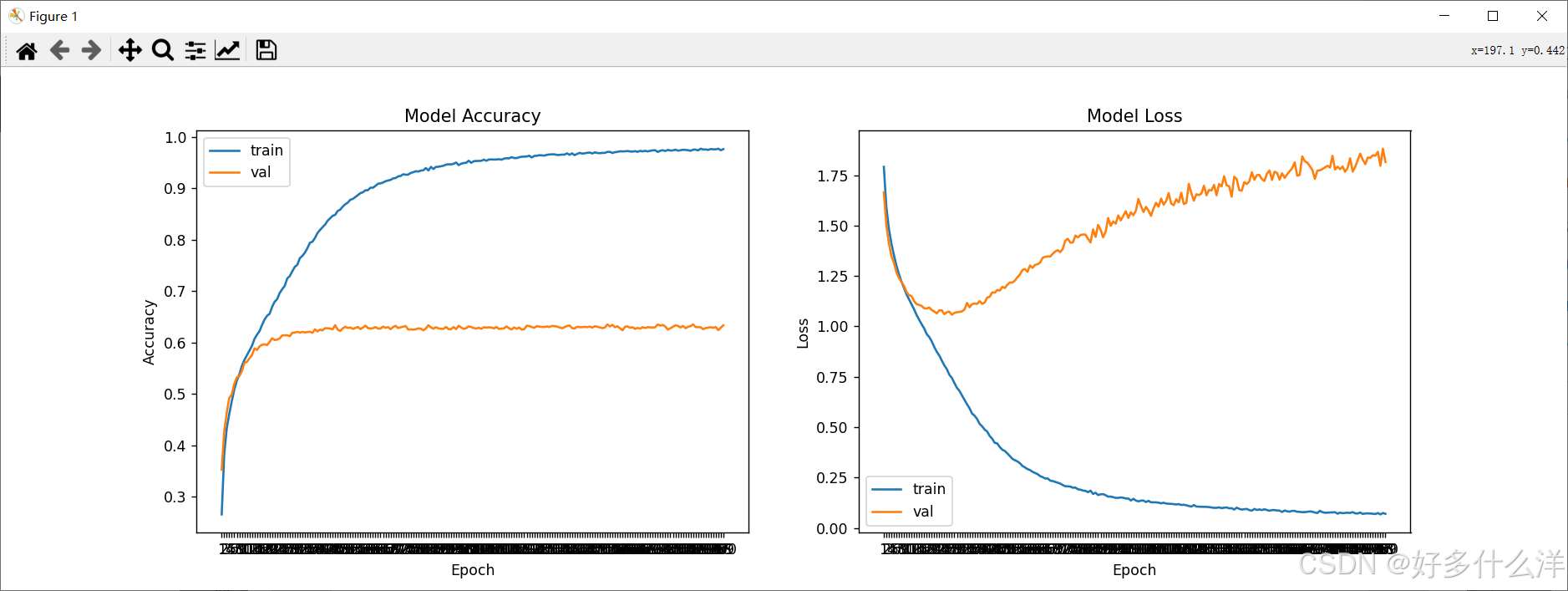

实验结果:在训练集上的准确率accuracy: 0.9761,在测试集上的准确率val_accuracy: 0.6335。
从曲线图可以看出:从epoch=60开始,在测试集上的精度没有增长同时loss曲线增加,说明模型在未见数据集上的训练精度已经达到最高了,但是测试集的训练精度随着epoch增加在不断增大。说明模型在训练集上效果好,泛化能力也不错
将训练好的保存的权重文件,利用模式中的“display”模式,打开电脑的摄像头,得到如下的结果,经过观察,得到的面部表情分析基本是正确的,说明模型的预测能力不错。
python xxx.py --mode display
四、基于pytorch训练模型
网络结构上,与基于tensorflow的结构相同,差异是PyTorch使用nn.Module作为模型的基础类,而TensorFlow使用Sequential模型或函数式API。
1、主要代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torchsummary import summary
import argparse
import matplotlib.pyplot as plt
import cv2
import numpy as np
# 设备选择
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 解析命令行参数
parser = argparse.ArgumentParser()
parser.add_argument("--mode", choices=["train", "display"], help="train/display")
args = parser.parse_args()
mode = args.mode
# 定义转换操作,将图像转换为PyTorch需要的格式
transform = transforms.Compose([
transforms.Resize((48, 48)),
transforms.Grayscale(),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 定义数据集
train_dataset = datasets.ImageFolder(root=r'C:\Users\w\OneDrive\桌面\课程实习2024\data\train', transform=transform)
val_dataset = datasets.ImageFolder(root=r'C:\Users\w\OneDrive\桌面\课程实习2024\data\test', transform=transform)
# 数据加载器
train_loader = DataLoader(dataset=train_dataset, batch_size=64, shuffle=True)
val_loader = DataLoader(dataset=val_dataset, batch_size=64, shuffle=False)
class CNNModel(nn.Module):
def __init__(self):
super(CNNModel, self).__init__()
self.conv1 = nn.Conv2d(1, 32, kernel_size=3, padding=1)
self.conv2 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.dropout = nn.Dropout(0.25)
self.fc1 = nn.Linear(64 * 12 * 12, 128)
self.fc2 = nn.Linear(128, len(train_dataset.classes))
def forward(self, x):
x = self.pool(nn.functional.relu(self.conv1(x)))
x = self.pool(nn.functional.relu(self.conv2(x)))
x = self.dropout(x)
x = x.view(x.size(0), -1)
x = nn.functional.relu(self.fc1(x))
x = self.dropout(x)
x = self.fc2(x)
return x
model = CNNModel().to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.0001)
# 训练模型
def train_model(model, train_loader, val_loader, optimizer, criterion, num_epochs=200):
history = {'train_loss': [], 'train_acc': [], 'val_loss': [], 'val_acc': []}
model.train()
for epoch in range(num_epochs):
running_loss = 0.0
correct = 0
total = 0
for i, (images, labels) in enumerate(train_loader):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
# 计算准确率
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 打印每个 batch 的进度和准确率
if (i+1) % 10 == 0: # 每10个batch打印一次
acc = 100 * correct / total # 计算当前 epoch 到目前为止的准确率
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {loss.item():.4f}, Acc: {acc:.2f}%')
# 平均训练损失和准确率
avg_train_loss = running_loss / (i + 1)
train_acc = 100 * correct / total
history['train_loss'].append(avg_train_loss)
history['train_acc'].append(train_acc)
# 验证模型
avg_val_loss, val_acc = validate_model(model, val_loader, criterion)
history['val_loss'].append(avg_val_loss)
history['val_acc'].append(val_acc)
# 每个 epoch 结束后打印损失和准确率
print(f'Epoch {epoch+1}/{num_epochs} Train Loss: {avg_train_loss:.4f}, Train Acc: {train_acc:.2f}% Val Loss: {avg_val_loss:.4f}, Val Acc: {val_acc:.2f}%')
# 保存模型权重
torch.save(model.state_dict(), r'C:\Users\w\OneDrive\桌面\课程实习2024\模型训练历史\model_pytorch_200.pth')
return history
def validate_model(model, val_loader, criterion):
model.eval()
running_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
running_loss += loss.item()
# 计算准确率
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 平均验证损失和准确率
avg_loss = running_loss / len(val_loader)
val_acc = 100 * correct / total
model.train()
return avg_loss, val_acc
def plot_model_history(history):
fig, axs = plt.subplots(1, 2, figsize=(15, 5))
axs[0].plot(history['train_loss'], label='Train Loss')
axs[0].plot(history['val_loss'], label='Val Loss')
axs[0].set_title('Model Loss')
axs[0].set_ylabel('Loss')
axs[0].set_xlabel('Epoch')
axs[0].legend(loc='best')
plt.show()
if mode == "train":
history = train_model(model, train_loader, val_loader, optimizer, criterion, num_epochs=200)
plot_model_history(history)
elif mode == "display":
model.load_state_dict(torch.load(r'C:\Users\w\OneDrive\桌面\课程实习2024\模型训练历史\model_pytorch_200.pth', map_location=device))
model.eval()
emotion_labels = ['Angry', 'Disgusted', 'Fearful', 'Happy', 'Neutral', 'Sad', 'Surprised']
face_cascade = cv2.CascadeClassifier(cv2.data.haarcascades + 'haarcascade_frontalface_default.xml')
cap = cv2.VideoCapture(0)
while True:
ret, frame = cap.read()
if not ret:
break
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, scaleFactor=1.1, minNeighbors=5)
for (x, y, w, h) in faces:
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
roi_gray = gray[y:y+h, x:x+w]
roi_gray = cv2.resize(roi_gray, (48, 48), interpolation=cv2.INTER_AREA)
roi_gray = roi_gray.astype('float') / 255.0
roi_gray = np.expand_dims(roi_gray, axis=0)
roi_gray = np.expand_dims(roi_gray, axis=0)
roi_tensor = torch.from_numpy(roi_gray).float().to(device)
with torch.no_grad():
preds = model(roi_tensor)
_, predicted = torch.max(preds, 1)
emotion_label = emotion_labels[predicted.item()]
cv2.putText(frame, emotion_label, (x, y-10), cv2.FONT_HERSHEY_SIMPLEX, 0.9, (0, 255, 0), 2)
cv2.imshow('Emotion Detector', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()2、运行结果
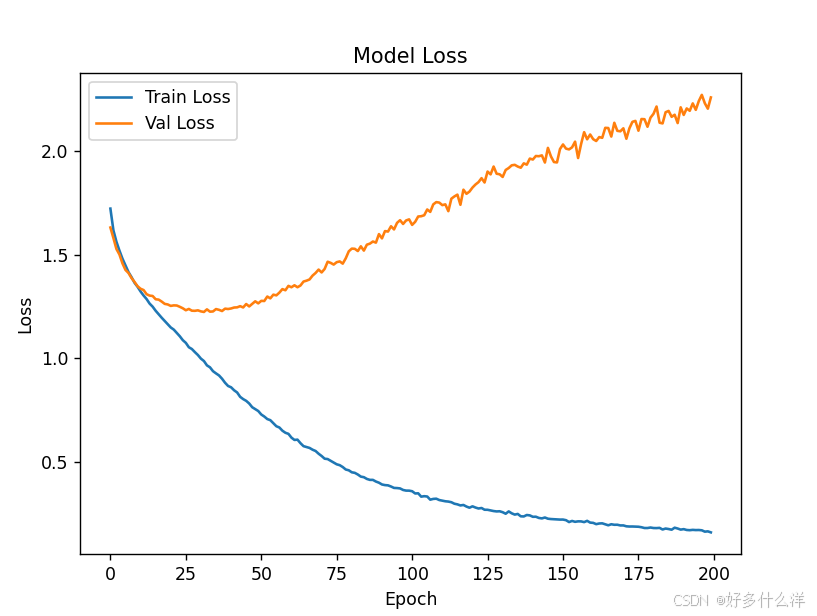

Train Acc: 94.30%, Val Acc: 55.56%
相较于tensorflow,两者都进行200轮训练结果差别不大
如果您对面部表情识别或深度学习有任何想法或疑问,欢迎在评论区分享。让我们一起探讨这个领域的无限可能!!


















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









