








目录
一、引言
通过前面的学习,我们已然了解到现代神经网络精髓之一的梯度下降算法。但是如果仔细观察我们设计的预测函数,你就会发现这是一个非常危险和不完善的模型。比如在另外一片海域里,豆豆的大小和毒性的关系是这样的,有些太小的豆豆是不存在的。我们发现不论怎样去调整W,都无法得到理想的预测函数。当然,更加糟糕的情况是,豆豆越大,毒性越低。

原因很简单,我们的预测函数y=wx,很明显是一个必须经过原点的直线。换句话说,这个预测函数直线的自由度被限制住了,只能旋转而不能移动。因为大家很清楚,一个直线完整的函数应该是y=wx+b。之前我们为了遵循如无必要物增新知的理念,一直在刻意的避免这个截距参数b,直到现在我们终于避无可避,是时候增加新的知识了。截距b的作用大家很清楚,可以让直线在平面内自由的平移,而斜率w可以让直线自由的旋转,当我们把直线的平移的自由度还给他之后,这两者的结合才能让直线在整个平面内真正的自由起来。

二、曲面梯度下降
我们来看一下加入截距b后发生的改变,首先我们带入b,重新推演一次预测和梯度下降的过程。当然为了简单起见,我们还是先看单个豆豆样本的情况,这是预测函数,豆豆的大小是x0,毒性是y0,那么预测就是wx+b,那么根据方差代价函数得到方差代价是这样的,你会发现没有b的时候,或者说b=0的时候,代价函数就是我们前几节课中的样子,这其实是b=0的一种特殊情况。

那现在既然有了b,接下来我们就要看这个b取不同值的时候,会对代价函数造成什么样子的影响,这里我们需要把代价函数的图像从二维变成三维,给b留出一个维度。b=0,就是我们之前讨论的抛物线,b=0.1和w关系还是一个标准的开口向上的抛物线,因为b的改变只影响这个抛物线的系数,换句话说,改变的只是抛物线的具体样子,而不会让它变成其他形状。同样的道理,b=0.2也是,b=0.3也是,等等等等。

我们好像已经看出一些眉目了,这好像是一个曲面。没错,这里我们的B取值间隔是0.1,描绘出来的效果似乎还是不太明显。当我们把b的取值间隔弄小一点,再小一点,直到无限的小下去,这时候你就会发现果真是一个三维空间中的曲面。那我们该如何去看待这个曲面?

在有些教程和书籍中,很多时候为了让它看着明显,把它画成了一个鼓鼓的碗状。其实对于线性回归问题中,这种豆豆数据形成的代价函数,实际上并没有那么的鼓,而是一个扁扁的碗,扁得几乎看不出来是个碗。但是当我们把这个曲面的等高线画出来,就可以看出来这确实也是一个碗。很明显,这个碗状曲面的最低点肯定是问题的关键所在。

我们回忆一下,在没有b 出现的时候,曲线的最低点代表着w取值造成的预测误差最小。

那么这个曲面最低点意味着什么?首先我们想一想,这个最低点是怎么形成的?没错,我们每次取不同的w和b都会导致误差e不相同,这个曲面也就是我们带入b后得到的代价函数的图像,而它的最低点也就意味着这里的w和b的取值会让预测误差最小。而如果我们能得到这个最低点的w和b的值放回到预测函数中,那么此时此刻恰如彼时彼刻,预测也就是最好的。现在我们的目标就很明确了,如何在这个曲面上取得最低点出的w和b的值?

在没有b出现的美好时刻,也就是说在b的等匀柱,我们沿着w的方向切上一刀,我们知道这将形成一个关于e和w的开口向上的抛物线,然后不断的通过梯度下降算法去调整w,最后到达最低点。

但是你会发现此刻曲线的最低点却并不是这个曲面的最低点,换句话说,b=0的取值并不是最好的。
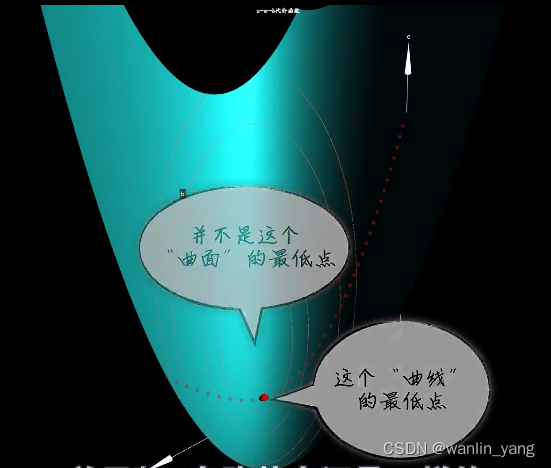
那么关于b套路其实还是一样的,我们在这一点上如果沿着b的方向给曲线来上一道会怎样?你会发现切口形成的曲线似乎也是一个开口向上的抛物线。

与之前只有e关于w的代价函数不同的是,此时e是关于w与b相结合的代价函数,代价函数的梯度就是分别对w、b求偏导。如果我们把对w和对b的偏导数看作向量,把这两个向量合在一起形成一个新的合向量,沿着这个合向量进行的下降,是这个曲面在该点下降最快的方式,这个合向量在数学里称之为梯度。

到此为止,你也就理解了为什么我们说梯度是比斜率更加广泛的一个概念,它是把各个方向上的偏导数当做向量合起来形成一个总向量,代表了这个点下降最快的方向。当然在二维曲线中,因为没有其他方向,梯度和斜率也可以认为是一回事。而为了让这个下降算法的名字更具有广泛性,所以我们一般称之为梯度下降,而不是斜率下降。

我们已经完整的讲述了梯度下降的过程,那么现在就来回顾总结一下目前为止我们所学到的东西。我们从环境中观察到的一个问题豆豆的毒性和它的大小有关系,那现在想要准确的去预测这个关系到底是什么?按照McCulloch-Pitts神经元模型,我们使用一个一元一次线性函数去模拟神经元的树突和轴突的行为,这就是预测函数模型。

三、反向传播
而把我们统计观测而来的数据输入预测函数进行预测的过程就称之为前向传播。因为计算从前往后,数据通过预测函数完成一次前向传播,就会得到一个预测值。预测值和统计观测而来的真实值之间存在着误差,我们需选择平方误差作为评估的手段,你会发现这个误差和预测函数中的参数又会形成一种函数关系,我们把这个函数称之为代价函数,因为采用方差去评估预测误差,所以也称之为方差代价函数。描述的预测函数的参数去不同值的时候预测的不同的误差代价,而用这个代价函数去修正预测函数参数的过程也称之为反向传播,因为计算从后往前,而这个反向传播参数修正的方法我们使用梯度下降算法。
 而在调整的过程中,用来调和下降幅度的阿尔法称之为学习率,它的选择影响了调整的速度,太大了容易反复横跳,过大的时候甚至不会收敛而是发散,太小了又容易磨磨唧唧,它是设计者根据经验选择出来的。而不断的经历前向传播和反向传播,最后到达代价函数最低点的过程我们称之为训练或者学习,这就是所谓的机器学习中的神经网络。但把一个神经元称之为网络似乎不太恰当,因为没有哪一个网络只有一个节点。但以后我们不断的添加神经元并把它们连接起来共同工作的时候,也就能称之为神经网络。
而在调整的过程中,用来调和下降幅度的阿尔法称之为学习率,它的选择影响了调整的速度,太大了容易反复横跳,过大的时候甚至不会收敛而是发散,太小了又容易磨磨唧唧,它是设计者根据经验选择出来的。而不断的经历前向传播和反向传播,最后到达代价函数最低点的过程我们称之为训练或者学习,这就是所谓的机器学习中的神经网络。但把一个神经元称之为网络似乎不太恰当,因为没有哪一个网络只有一个节点。但以后我们不断的添加神经元并把它们连接起来共同工作的时候,也就能称之为神经网络。

四、编程实验
以小蓝吃豆豆为引子,求豆豆大小与毒性关系,介绍代价函数e关于w和b的编程。
1.豆豆的毒性数据生成代码dataset.py
import numpy as np
def get_beans(counts): #构造吃豆豆的函数
xs = np.random.rand(counts) #
xs = np.sort(xs) #进行行排序
ys = np.array([(0.7*x+(0.5-np.random.rand())/5+0.5) for x in xs])
return xs,ys
2. 在b不同情况下,代价函数e关于w的函数代码cost_function_w.py
mpl_toolkits.mplot3d库,画三维图像的库
ax.plot(ws, es, b, zdir='y')#生成不同b下e关于w的函数图像,其中zdir='y',将y轴朝向向上

import dataset #调用dataset库
from matplotlib import pyplot as plt #调用matplotlib库的pyplot
#import matplotlib.pyplot as plt
import numpy as np #调用numopy库
from mpl_toolkits.mplot3d import Axes3D#导入mpl_toolkits.mplot3d中的3D坐标
#从数据中获取随机豆豆
m=100
xs,ys = dataset.get_beans(m)
#配置图像,坐标信息
plt.title("Size-Toxicity Function",fontsize=12)#设置图像名称
plt.xlabel("Bean Size")#设置横坐标的名字
plt.ylabel("Toxicity")#设置纵坐标的名字
plt.xlim(0,1)#plt.xlim()函数限制x轴范围
plt.ylim(0,1.5) #plt.ylim()函数限制y轴范围
# 豆豆毒性散点图
plt.scatter(xs, ys)
#预测函数
w=0.1
b=0.1
y_pre = w*xs+b
#预测函数图像
plt.plot(xs,y_pre)
#显示图像
plt.show()
#Axes3d和plt建立关联,将2D对象变为3D对象
fig = plt.figure()#得到plt的图形对象
ax = Axes3D(fig)#通过Axes3D创建3D对象
ax.set_zlim(0,2)#限制垂直方向的范围
#代价函数
ws = np.arange(-1,2,0.01)#(起始值,结束值,步长)
bs = np.arange(-2,2,0.01)#(起始值,结束值,步长)
for b in bs:#在不同b下e关于w的取值
es = []
for w in ws:#每次取不同的w
y_pre = w*xs+b
e = (1/m)*np.sum((ys-y_pre)**2)#和第二节课一样,代价函数
es.append(e)
#plt.plot(ws,es)
ax.plot(ws, es, b, zdir='y')#生成不同b下e关于w的函数图像
#显示图像
plt.show() 得出图像

3. 在w不同情况下,代价函数e关于b的函数代码cost_function_b.py
import dataset #调用dataset库
from matplotlib import pyplot as plt #调用matplotlib库的pyplot
#import matplotlib.pyplot as plt
import numpy as np #调用numopy库
from mpl_toolkits.mplot3d import Axes3D
#从数据中获取随机豆豆
m=100
xs,ys = dataset.get_beans(m)
#配置图像,坐标信息
plt.title("Size-Toxicity Function",fontsize=12)#设置图像名称
plt.xlabel("Bean Size")#设置横坐标的名字
plt.ylabel("Toxicity")#设置纵坐标的名字
plt.xlim(0,1)#plt.xlim()函数限制x轴范围
plt.ylim(0,1.5) #plt.ylim()函数限制y轴范围
# 豆豆毒性散点图
plt.scatter(xs, ys)
#预测函数
w=0.1
b=0.1
y_pre = w*xs+b
#预测函数图像
plt.plot(xs,y_pre)
#显示图像
plt.show()
#代价函数
ws = np.arange(-1,2,0.1)#(起始值,结束值,步长)
bs = np.arange(-2,2,0.1)#(起始值,结束值,步长)
#Axes3d和plt建立关联,将2D对象变为3D对象
fig = plt.figure()#得到plt的图形对象
ax = Axes3D(fig)#通过Axes3D创建3D对象
ax.set_zlim(0,2)#限制垂直方向的范围
for w in ws:#每次取不同的w
es = []
for b in bs:
y_pre = w*xs+b
#得到w和b的关系
e = (1/m)*np.sum((ys-y_pre)**2)#和第二节课一样,代价函数
es.append(e)
#plt.plot(ws,es)
figure = ax.plot(bs, es, w, zdir='y')#生成不同b下e关于w的函数图像
#显示图像
plt.show() 4、直接生成曲面代码cost_function_surface.py
import matplotlib.pyplot as plt
import dataset
import numpy as np
from mpl_toolkits.mplot3d import Axes3D
#从数据中获取随机豆豆
m=100
xs,ys = dataset.get_beans(m)
#配置图像,坐标信息
plt.title("Size-Toxicity Function",fontsize=12)#设置图像名称
plt.xlabel("Bean Size")#设置横坐标的名字
plt.ylabel("Toxicity")#设置纵坐标的名字
plt.scatter(xs,ys) #画散点图
# 豆豆毒性散点图
plt.scatter(xs, ys)
#预测函数
w=0.1
b=0.1
y_pre = w*xs+b
#预测函数图像
plt.plot(xs,y_pre)
#显示图像
plt.show()
#代价函数
ws = np.arange(-1,2,0.1)
bs = np.arange(-2,2,0.1)
#把ws和bs变成一个网格矩阵
#这个网格矩阵的含义可以参考这篇文章:
#https://blog.csdn.net/lllxxq141592654/article/details/81532855
ws,bs = np.meshgrid(ws,bs)
print(ws)#打印出来瞅瞅
print(bs)
es = 0
#因为ws和bs已经变成了网格矩阵了
#一次性带入全部计算,我们需要一个一个的算
for i in range(m):
y_pre = ws*xs[i]+bs#取出一个样本在网格矩阵上计算,得到一个预测矩阵
e = (ys[i]-y_pre)**2#标准值减去预测(矩阵)得到方差矩阵
es += e#把单样本上的方差矩阵不断累加到es上
es = es/m#求平均值,这样es方差矩阵每个点的位置就是对应的ws和bs矩阵每个点位置预测得到的方差
fig = plt.figure()
ax = Axes3D(fig)
ax.set_zlim(0,2)
#plot_surface函数绘制曲面
#cmap='rainbow表示彩虹图(用不同的颜色表示不同值)
ax.plot_surface(ws, bs, es, cmap='rainbow')
#显示图像
plt.show() 得出图像

5、代价函数e对w、b均求偏导,然后梯度下降代码 sgd_w_b.py


import dataset #调用dataset库
from matplotlib import pyplot as plt #调用matplotlib库的pyplot
#import matplotlib.pyplot as plt
import numpy as np
m=100
xs,ys=dataset.get_beans(m) #获取100个豆子数据
#配置图像,坐标信息
plt.title("Size-Toxicity Function",fontsize=12)#设置图像名称
plt.xlabel("Bean Size")#设置横坐标的名字
plt.ylabel("Toxicity")#设置纵坐标的名字
plt.scatter(xs,ys) #画散点图
#预测函数
#y=0.1*x
w=0.1 #初始权值
b=0.1
y_pre=w * xs+b
plt.plot(xs,y_pre)
plt.show() #显示图像
for m in range(500):#调整500次全部,0-99的整数,用range 函数进行for循环
for i in range(100):#调整1次全部,可能会导致线不拟合
x=xs[i];
y=ys[i];
#a=x^2
#b=-2*x*y
#c=y^2
#斜率k=2aw+b
alpha=0.01 #学习率,学习率不可过大也不可过小
dw=2*x**2*w+2*x*(b-y)#对w求偏导
db=2*b+2*x*w-2*y#对b求偏导
w=w-alpha*dw#梯度下降
b=b-alpha*db#梯度下降
plt.clf( )#清理窗口
plt.scatter(xs,ys)
y_pre = w*xs+b
plt.xlim(0,1) #plt.xlim()函数限制x轴范围
plt.ylim(0,1.5) #plt.ylim()函数限制y轴范围
plt.plot(xs,y_pre)
plt.pause(0.01) #暂停0.01s 得出图像

五、总结
本文介绍完整的函数y=wx+b下的梯度下降原理和反向传播概念。我们所说的前向传播和反向传播其实也是在多层神经网络出现后才引入了概念。对于单个神经元如此称呼似乎有点别扭,但这些概念在单个神经元上已经初具雏形,面对网络那只是不断的重复而已。我们会在后面学习多层神经网络时候详细说明反向传播更一般的行为,这就是目前人工智能机器学习领域独领风骚的联结主义在干的事情。至于为什么这样多个神经元组合成神经网络后就能达到智能的效果,别着急,我们会在接下来的课程中慢慢到来。
六、往期内容

4.反向传播:能改
5.激活函数:给机器注入灵魂
6.隐藏层:神经网络为什么working
7.高维空间:机器如何面对越来越复杂的问题
8.初识Keras:轻松完成神经网络模型搭建
9.深度学习:神奇的DeepLearning
10.卷积神经网络:打破图像识别的瓶颈
11. 卷积神经网络:图像识别实战
12.循环:序列依赖问题
13.LSTM网络:自然语言处理实践
14.机器学习:最后一节课也是第一节课
视频链接:![]() https://pan.baidu.com/s/17en9_JrDiVU-jl3LUfyDIw?pwd=6666可视化工具链接:
https://pan.baidu.com/s/17en9_JrDiVU-jl3LUfyDIw?pwd=6666可视化工具链接:![]() https://pan.baidu.com/s/1aowGt_YlH9XVVuKv4wS5Xg?pwd=6666
https://pan.baidu.com/s/1aowGt_YlH9XVVuKv4wS5Xg?pwd=6666
可视化工具包含:
1.e-b代价函数曲线形成曲面
2.e-w代价函数曲线形成曲面
3.e-w_b梯度下降
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









