








目录
一、引言
有人说我们是上帝的作品,也有人说我们自己就是上帝,但我认为把人作为中心讨论却大可不必,因为地球上有那么多的生物智能,又何必是人?不如让我们看看那些更加原始和简单的生物遇到的问题和他们具有的智能。在很深很深很深的海底,住在一个简简单单的生物小蓝,它的世界很简单,去寻找周围能够吃到的一种叫做豆豆的食物,并靠此生存。

但是这些豆豆在漫长的演化历史中,通过和小蓝的反复博弈,为了保护自己,逐渐进化出了毒性,毒性的强弱和豆豆的大小有关系,而小蓝也进化出了一个能够检测豆豆大小的器官。那么问题来了,小蓝如何根据豆豆的大小判断它到底有多毒?
没错,它还缺一个思考的器官,也就是我们常说的脑子。但我们又如何去描述思考或者说认知?认知以前当然就是一无所知。这种情况下,认知事物唯一的方法就是依靠直觉。那我们又该如何去描述直觉?很明显是函数。为什么是函数?仔细想想,我们本来一直就在用函数认识这个世界。在物理中,一个质量为M的物体在不同的受力F下产生加速度a,这是一个以F为自变量,M为参数、a为因变量的函数F=ma。在经济学中,我们把消费、投资、政府购买和进出口作为自变量,也可以形成一个关于GDP的认知函数GDP=f(C,I,g,nx)。实际上,除了这些严格的领域,在很多不那么严格的事情上,如果你愿意,其实也可以用函数去描述认知。比如气温对人心情的影响可能是这样的一个函数
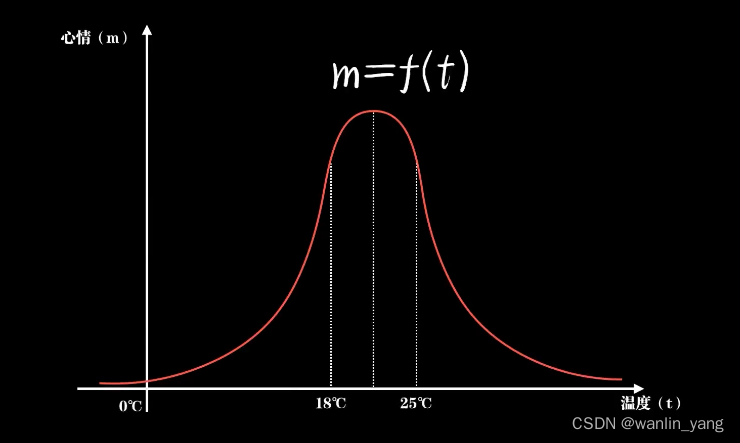
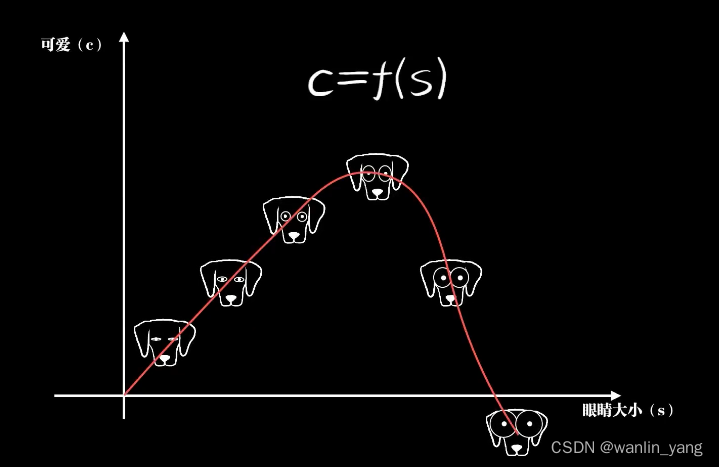
一只小狗的眼睛大小和它可爱程度的关系可能是这样的一个函数,而后者这种不严格、人类更加擅长的问题,也就是我们人工智能要解决的问题,找到一个恰当的函数去描述它。如此这般,把智能体对世界认知的过程看作是在脑中不断形成各种函数。
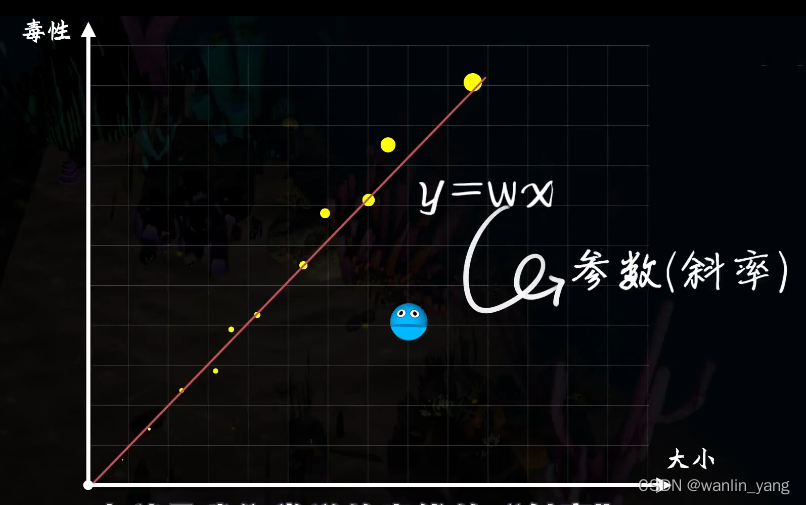
既然是直觉,那么就不需要太多的理由,豆豆的毒性和它的大小有关系,所以这里的直觉自然是一个一元一次函数,豆豆的大小X是自变量,毒性Y是因变量,而W是一个确定的参数,也就是我 们常说的直线的斜率。
二、McCulloch-Pitts模型
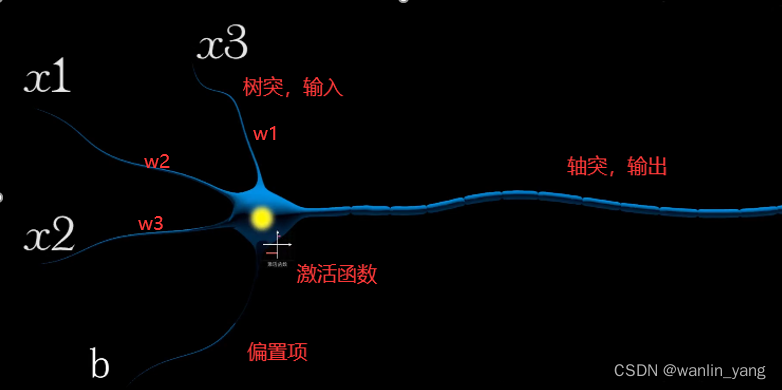
一个简单的一元一次函数就可以描述一个直觉,建立一种思考的模型。当我们去类比生物神经元的时候,你就会发现,用一个一元一次函数去描述认知可不是乱用的,完全是有备而来。这实际上就是早在1943年,由神经学家麦卡罗赫和数学家皮次在他们合作的论文中提出的一种神经元模型McCulloch-Pitts模型。这个模型是对生物神经元一种相当简化的模仿,有树突和轴突,输入信号通过树突进入神经元,再通过轴突输出结果,它们分别对应着函数中的自变量和因变量。树突一般来说有很多个输入端。如果只有一个输入端,也就是一元函数;如果是两个,那就是二元函数,比如豆痘的毒性不仅和它的大小有关,也和颜色有关。三个数就是三元函数等等。而至于参数W(权重),它实际上起着控制输出上输入信号的作用。换句话说,控制的不同输入对输出的影响,我们也称之为权值w。因为我们在判断一个东西的时候,不同因素对结果的重要性都不太一样。也正因为如此,我们会发现McCulloch-Pitts模型选择用一次函数而不是其他函数来模仿神经元是一件很自然的事情。输入X被全值参数W扩大或缩小,然后输出简单且有效。当然,完整的McCulloch-Pitts模型中还有一个偏置项B,而在一次函数后还会加上一个激活函数。用来激活信息元的输出,我们会在后面讨论这些东西。简单起见,暂且不表。
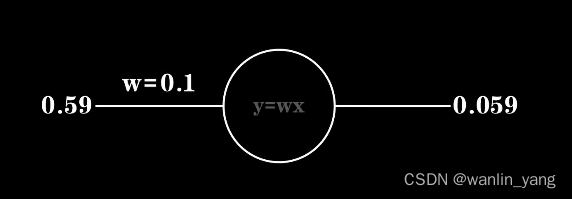
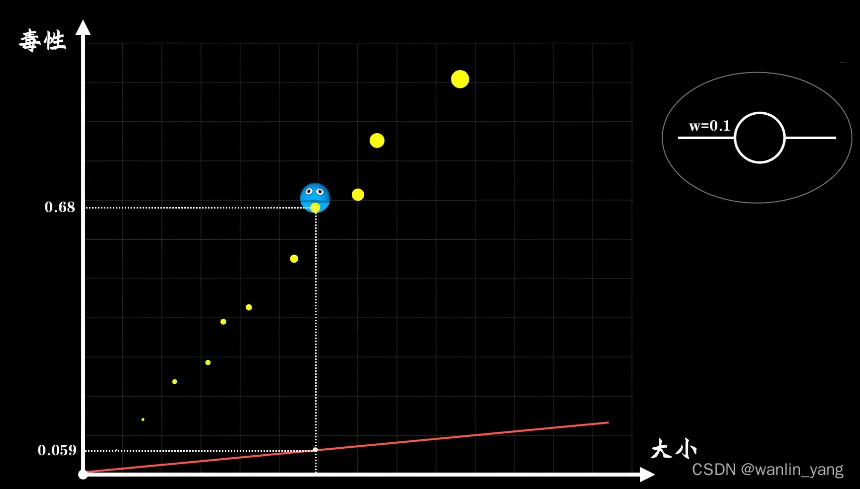
回到这个树突只有一个输入端的神经元上面来。为了理解方便,我们用简化的图形来表示。那么小蓝靠这个神经元可以存活下去吗?看得出来,随着W取不同的值,这个直觉函数往往会产生很多的错误。当然,也不排除小蓝的直觉很准,就像这样。那么我们现在面临的问题就是,这个一元一次直觉函数中的参数W设置为多少,小蓝才能很好的进行预测?也就是说,如何从偏离现实的直觉过渡到符合现实的认知?比如小蓝大脑中神经元的权重值W一开始是0.1,看见一个大小为0.59的豆豆,经过神经元的计算,认为毒性是0.059 , 于是一口吃进去,糟糕,其实它的毒性是0.68,具有极高的毒性。很明显,小蓝现在的神经元很草率,作为早已具有思维的人类,我们知道把W调大一点,再大一点,这样就好了,但是机器又怎么知道?

三、Rosenblatt感知器
最开始McCulloch-Pitts神经元模型中的权重值确实需要手工调整,并没有自动的学习方法,这未免有点不智能。于是在1958年一名叫做罗森布拉特的心理学家在McCulloch-Pitts模型上提出了罗森布拉特(Rosenblatt)感知器模型,它让神经元有了自己调整参数的能力。Rosenblatt感知器是第一个从算法上完整描述的神经元,在此之后,受到它的启发,工程界、物理学界、数学界就开始纷纷投入神经网络的研究,人工智能也开始了蓬勃的发展。我们来看一下Rosenblatt感知器是怎么做到让神经元能够改的。

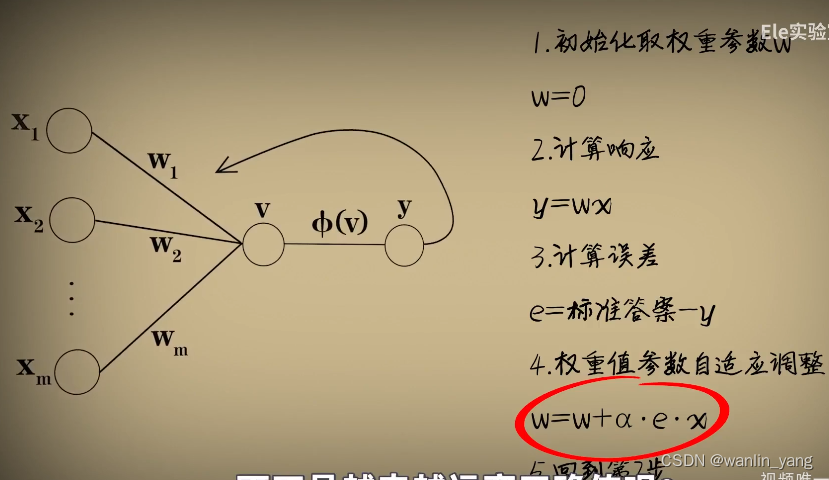
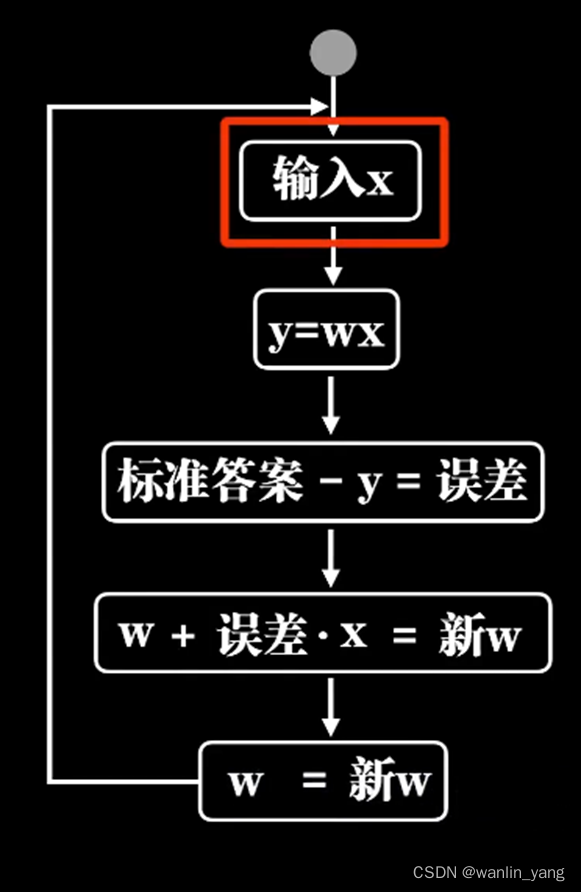
当然,本着如无必要误增新知的理念,我们还是考虑只有一个输入的情况,其实很简单也很直观,输入通过McCulloch-Pitts神经元模型之后,输出一个结果,用标准答案减去这个结果,这意味着预测和标准之间的误差,然后根据这个误差去调整参数。比如我们让W直接加上这个误差,再让结果作为新的W,你看这样就做到了,预测过小的时候误差为正数,W加上误差之后向大调整,下次预测的时候结果就提升了。反过来,当预测过大误差是负数的时候,W向小调整。这就是Rosenblatt感知器的学习过程,通过误差修正参数。
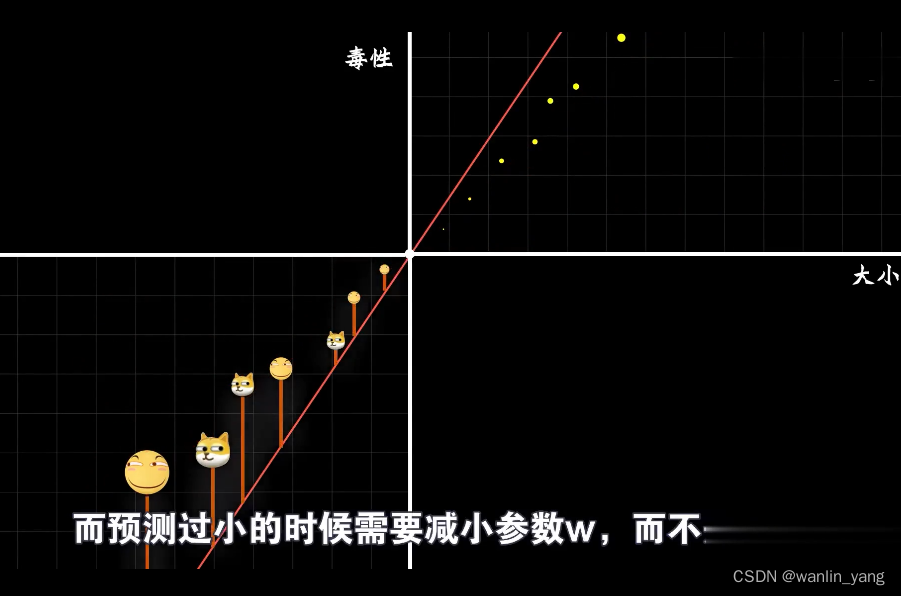
当然在Rosenblatt感知器模型中,误差还有乘以输入X,这是为何?我们知道豆豆的大小只能是一个正数,小于零的豆豆可谓让人匪夷所思。但是以后我们一定会遇到输入值是负数的情况,当输入数据是负数的时候,你会发现事情正好相反,预测过大的时候需要增加W而不是减少,而预测过小的时候需要减小W,而不是增加。

当然误差除了乘以输入X之外,Rosenblatt感知器模型还让误差乘了一个系数阿尔法,比如0.05,这意味着我们每次修正的时候幅度都降低了20倍,这个阿尔法也就是所谓的学习率。这又是为何?我们不妨先拿掉这个学习率参数看看会怎么样。
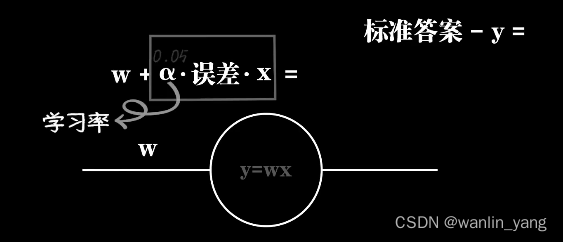
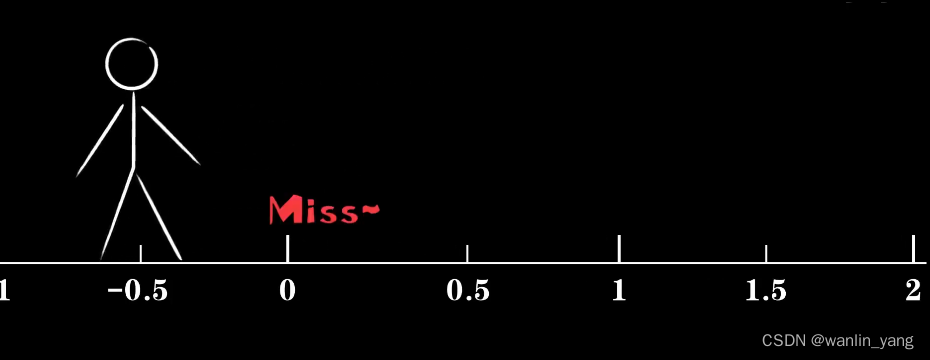
阿尔法过大,震荡过大。当我们继续把阿尔法向小调整,我们终于发现参数调整的过程震荡越来越小。没错,让误差成语学习率是为了防止调整幅度过大,错过最佳点。就好像一个人,如果他每走一步走出固定的一米,而他一开始在距离原点0.5米的位置,那么不论他怎样都到达不了原点。当然,学习率也不是越小越好,太小的学习率会让这个调整的过程磨磨唧唧。
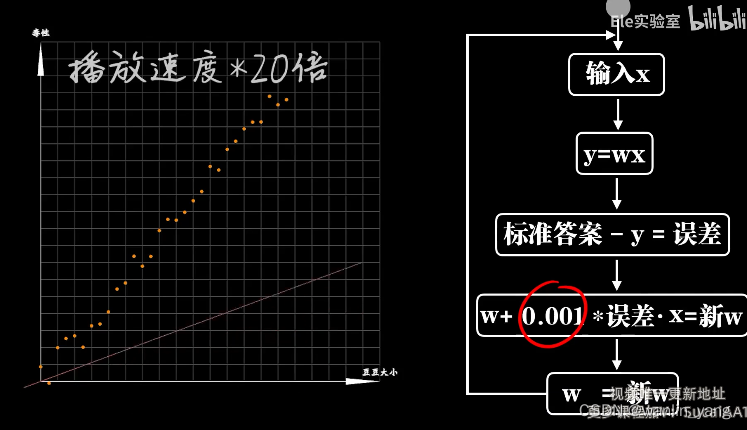
机器学习通过误差修正参数,误差还乘上了学习率。Rosenblatt感知器模型在数学上被证明,W一定会收敛于某个值。在现代机器学习神经网络应用中,古老的罗森布拉特感知器的学习方法已经很少采用。接下来我们将看到一种目前比较常用的学习方式,梯度下降和反向传播。
四、编程实验
本次编程主要内容为小蓝感知豆豆毒性的普通预测函数加上Rosenblatt感知器,推荐使用sublime编辑器,用电脑命令打开并运行所保存的python。

numpy库特点:数组内相对应的元素可以相乘或相加。

1.生成并保存dataset.py文件,里面为随机生成豆豆数据及模块get_beans的函数。
import numpy as np
def get_beans(counts): #构造吃豆豆的函数
xs = np.random.rand(counts) #
xs = np.sort(xs) #进行行排序
ys = [1.2*x+np.random.rand()/10 for x in xs]
return xs,ys
2.自定义权值的beans_predict.py代码(权值w自己设置)
import dataset #调用dataset库
from matplotlib import pyplot as plt #调用绘图matplotlib库的pyplot
xs,ys=dataset.get_beans(100)
print(xs)
print(ys)
#配置图像,坐标信息
plt.title("Size-Toxicity Function",fontsize=12)#设置图像名称
plt.xlabel("Bean Size")#设置横坐标的名字
plt.xlabel("Toxicity")#设置纵坐标的名字
plt.scatter(xs,ys) #画散点图
#预测函数,一次预测,这里预测是自己设置的权值
#y=0.5*x
w=0.5
y_pre=w * xs
print(y_pre)
plt.plot(xs,y_pre) #画线
plt.show() #显示图像 show函数可以看做一次图像刷新
原理图
生成图片结果
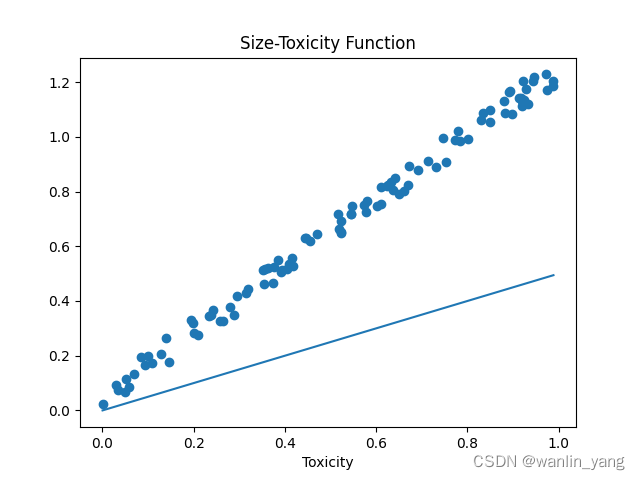
可以看出自定义权值预测的函数不好
3. 更新权值的Rosenblatt感知器代码
import dataset #调用dataset库
from matplotlib import pyplot as plt #调用matplotlib库的pyplot
xs,ys=dataset.get_beans(100)
print(xs)
print(ys)
#配置图像,坐标信息
plt.title("Size-Toxicity Function",fontsize=12)#设置图像名称
plt.xlabel("Bean Size")#设置横坐标的名字
plt.xlabel("Toxicity")#设置纵坐标的名字
plt.scatter(xs,ys) #画散点图
#预测函数
#y=0.5*x
w=0.5 #初始权值
for m in range(50):#调整50次全部,0-99的整数,用range 函数进行for循环
for i in range(100):#调整1次全部,可能会导致线不拟合
x=xs[i];
y=ys[i];
y_pre=w * x
e=y-y_pre #误差
alpha=0.05 #学习率,学习率不可过大也不可过小
w=w+alpha*e*x
y_pre=w * xs
print(y_pre)
plt.plot(xs,y_pre)生成图片结果
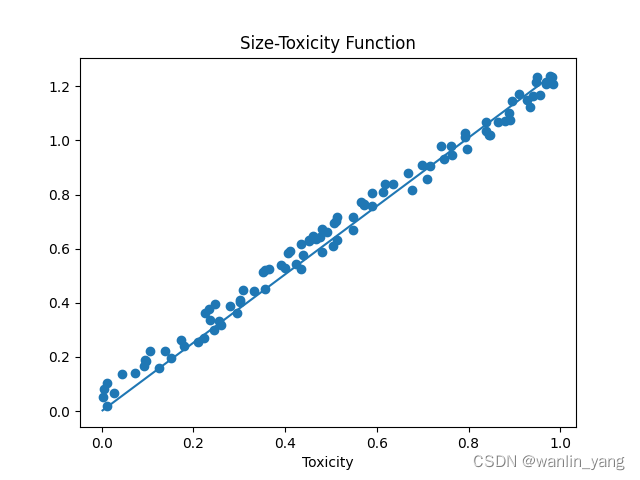
可以看出经过多次权值调整,预测函数比较完美。
五、总结
在本节课中,我们从深海生物小蓝遇到的问题开始琢磨一个人工智能的构建方式。我们发现一个简单的一次函数就可以建立一种认知的模型。随后我们说,早在1943年,麦卡罗赫和皮次就在尝试这么干,并且建立了第一个神经元模型,McCulloch-Pitts模型。而为了让神经元能够自我调节,我们介绍了Rosenblatt感知器的工作原理。最后在编程实验中,我们详细的讲述了如何用python语言去实现一个感知器。这些最初阶段的构想和尝试直到今天仍然影响着机器学习神经网络的研究和发展。他们像数学里的1+1=2一样朴素,但意义非凡。在下一节课中,我们就开始学习现代机器学习神经网络的内容。我们会说到一个非常简单但是非常重要的概念,代价函数。
六、往期内容

1.一元一次函数感知器:如何描述直觉
2.方差代价函数:知错
3.梯度下降:能改
4.反向传播:能改
5.激活函数:给机器注入灵魂
6.隐藏层:神经网络为什么working
7.高维空间:机器如何面对越来越复杂的问题
8.初识Keras:轻松完成神经网络模型搭建
9.深度学习:神奇的DeepLearning
10.卷积神经网络:打破图像识别的瓶颈
11. 卷积神经网络:图像识别实战
12.循环:序列依赖问题
13.LSTM网络:自然语言处理实践
14.机器学习:最后一节课也是第一节课
视频链接:![]() https://pan.baidu.com/s/1jCKPuGV3IqICz7Vq6iGxxQ?pwd=hb2f 可视化工具链接:
https://pan.baidu.com/s/1jCKPuGV3IqICz7Vq6iGxxQ?pwd=hb2f 可视化工具链接:![]() https://pan.baidu.com/s/10FPCKX-yyPlQ9LARnBDgDA?pwd=fubf
https://pan.baidu.com/s/10FPCKX-yyPlQ9LARnBDgDA?pwd=fubf
















 427
427











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









