








目录
一、时间序列
前面两节课我们已经学习了卷积神经网络的基本原理和应用。仔细想想,之所以使用卷积运算,那是因为我们观察到一个图像数据在空间上有着不可分割的关联性。那再想一下,数据除了在空间上可能出现关联性以外,也可能在时间上如此,比如气温数据、股票数据等等。
 当然最典型的就是我们人类的语言(语音和文字),声波随着时间依次传入我们的耳朵进入大脑,文字随着时间逐个通过眼睛进入大脑。所以,面对这样在时间上有关联性的数据,神经网络该如何去识别和处理?
当然最典型的就是我们人类的语言(语音和文字),声波随着时间依次传入我们的耳朵进入大脑,文字随着时间逐个通过眼睛进入大脑。所以,面对这样在时间上有关联性的数据,神经网络该如何去识别和处理?


我们以文字举例,假如这些是某个视频评论区中的评论,现在想让神经网络识别出这些评论中哪些是正面的,哪些是负面的?
 自然就像我们第一次面对图片数据那样,首先我们要想个办法把评论文字转成计算机能够识别的数字。我们的第一反应可能是字符的编码值,比如英文,我们可以使用英文字符的ASCII值把这句话转化为数字。
自然就像我们第一次面对图片数据那样,首先我们要想个办法把评论文字转成计算机能够识别的数字。我们的第一反应可能是字符的编码值,比如英文,我们可以使用英文字符的ASCII值把这句话转化为数字。
 但在自然语言处理中,最小的单位往往是词,而不是单个的字母。比如单词adopt和adapt在字母层面上很像,但却是两个意思完全不同的词,中文可能好一点,但单个汉字的价值也远远不如词。所以我们一般把词作为自然语言处理中最基本的单位。
但在自然语言处理中,最小的单位往往是词,而不是单个的字母。比如单词adopt和adapt在字母层面上很像,但却是两个意思完全不同的词,中文可能好一点,但单个汉字的价值也远远不如词。所以我们一般把词作为自然语言处理中最基本的单位。
那么如何把一个词转化成一个数字?查词典。
我们以英文Nice to meet you为例,我们先从字典表中找到Nice、to、meet、you这四个单词的索引值,然后把索引值转化为词向量送入到神经网络中。

中文也是这个思路,只不过不像是英文可以自然地通过空格来切割一个句子的单词。中文要麻烦一点,需要先分词,然后转化为向量。
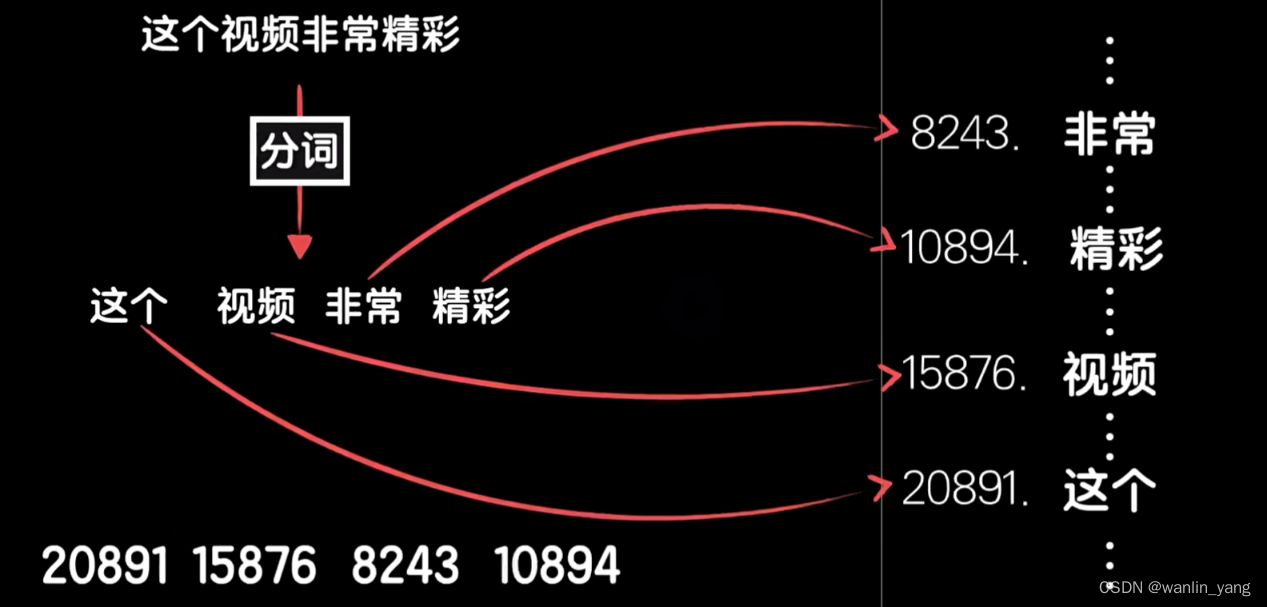 当然这样处理会有一个问题,比如如果是一个有1万个词汇的词典,假如开除和开心两个词因为第一个字读音的关系在词典中出现了位置很接近,比如分别在第4098和第4099,那么这两个词在数据上看来就很相似。如果我们再把它们进行归一化操作,那么就是0.4098和0.4099这两个数值差异极小,但遗憾的是,开心和开除两个词指代的概念完全不同,这样的数据就会给我们的预测模型带来不必要的麻烦。
当然这样处理会有一个问题,比如如果是一个有1万个词汇的词典,假如开除和开心两个词因为第一个字读音的关系在词典中出现了位置很接近,比如分别在第4098和第4099,那么这两个词在数据上看来就很相似。如果我们再把它们进行归一化操作,那么就是0.4098和0.4099这两个数值差异极小,但遗憾的是,开心和开除两个词指代的概念完全不同,这样的数据就会给我们的预测模型带来不必要的麻烦。

one hot编码
所以在自然语言处理领域,我们需要对词汇的表示方法做进一步的处理。使用one hot编码方式对词汇进行编码似乎是个好主意,但是呆板的One-Hot编码却无法体现猫和狗的相关性、苹果和猫的无关性等。


再者One-Hot编码会让输入的数据变大,假如词典有一万个单词,每个单词都是一个一万维的向量,四个词则输入数据就有4W个元素。

词向量
所以NLP中提出了“词向量”的概念,不过这与神经网络没多大关系

在介绍多维数数据的时候,我们说过,每个维度实际上是一个事物多个角度的特征,比如豆豆数据中我们可以收集大小、颜色、深浅、硬度等等豆豆的特征,构成一个输入的向量数据。
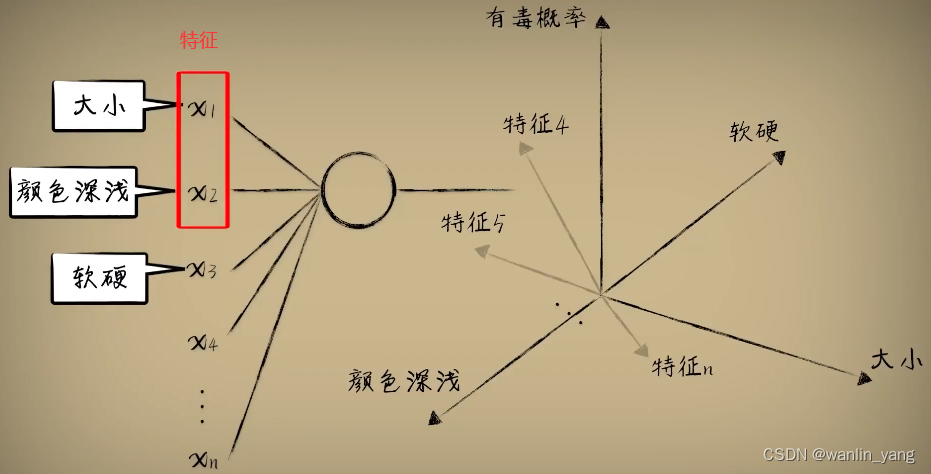
语言本身就是对现实世界的描述,词汇本就是用来指代一个事物的,比如狗这个词,我们从多个角度来描述这个词,提取多个特征值,形成一个词向量:
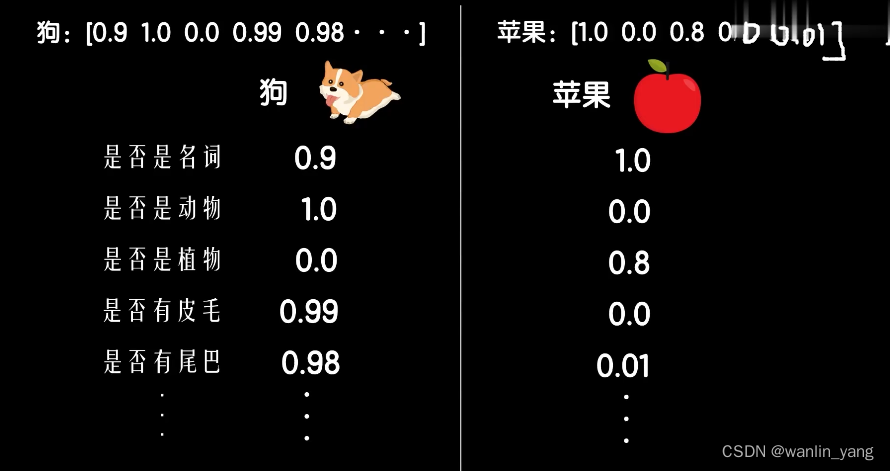
为方便讲解,我们以两个特征维度为例,在二维空间画出来,最后会是这样:

我们发现词义更加接近的词在向量空间中更加接近,反之词义无关的词距离很远,比如动物词汇聚集在了一起,植物词汇聚集在了一起,而动物中猫狗这种家养宠物和野生的豺狼虎豹相比距离又更近一些,植物里水果和蔬菜又各自聚集,而动植物之间的距离和像手机、电脑这样的非生物相比又要近一些。而有趣的是,在一个特征提取适当的词向量集合中,如果我们用警察这个词的词向量去减去小偷这个词的词向量,得到的结果向量和猫这个词的词向量减去老鼠这个词的词向量的结构向量非常的接近,这意味着警察和小偷的关系和猫和老鼠的关系十分相似。所以使用这样的数据会让我们的模型更容易训练,也更容易泛化。这个技术在NLP中称之为词嵌入,把词嵌入到一个特征向量空间。
那么问题来了,我们该如何提取一个词的特征从而得到合适的词向量?
以猫、狗、苹果、西瓜这四个词为例,我们需要得到这四个词的词向量,而且我们希望词向量有十个特征,那么我们就构造一个10*4的词嵌入矩阵,并随机初始化这个矩阵的初始值,这样这个矩阵的每一列就分别表示这四个词的十维词向量。接下来,我们需要想个办法在这个嵌入矩阵上把某个词的词向量给提取出来。非常简单,我们还是依靠one-hot的编码来做这件事情。
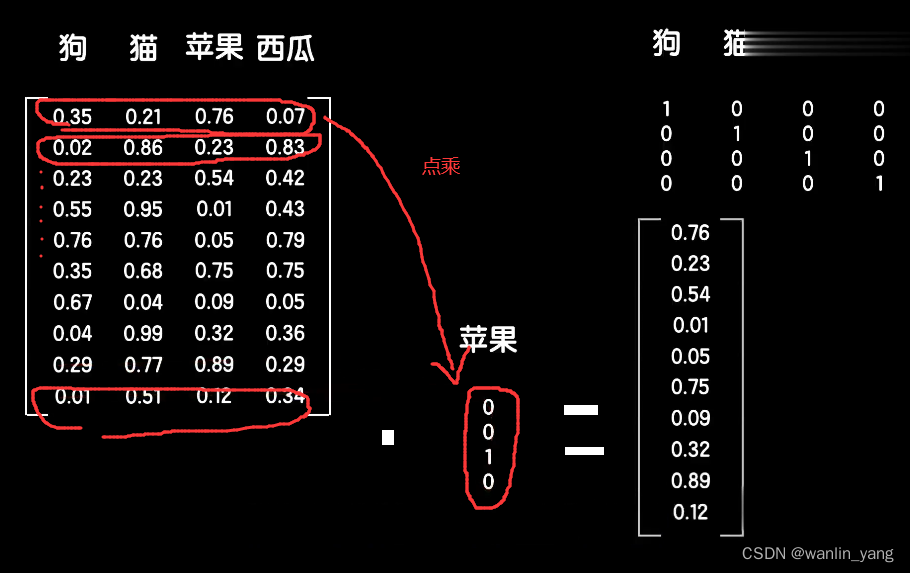 我们先给四个词做one-hot的编码,这样我们用这个嵌入矩阵点乘一个词的one-hot的编码时,比如苹果这个词,那么根据矩阵的点乘性质,由于苹果的one-hot的编码只有第三个元素是一,其他是零,所以把嵌入矩阵的第三列给提取了出来。同样,用这个嵌入矩阵点成其他词的完好的编码,就可以提取出各自的词向量。有了这个嵌入矩阵,我们就可以把一句话中所有的词转化为词向量。
我们先给四个词做one-hot的编码,这样我们用这个嵌入矩阵点乘一个词的one-hot的编码时,比如苹果这个词,那么根据矩阵的点乘性质,由于苹果的one-hot的编码只有第三个元素是一,其他是零,所以把嵌入矩阵的第三列给提取了出来。同样,用这个嵌入矩阵点成其他词的完好的编码,就可以提取出各自的词向量。有了这个嵌入矩阵,我们就可以把一句话中所有的词转化为词向量。
如此我们重新理一遍整个过程。以“这个视频非常精彩”、“这个视频非常好看”两句为例,首先对这两句分词统计组成词向量嵌入矩阵(词汇表的词向量集合),然后点乘“这个、视频、非常、精彩”的One-Hot矩阵,提取出它们各自的词向量,最后矩阵平铺送入全连接神经网络模型训练。

值得一提的是,我们把矩阵点乘这一层称为嵌入层:

对于这个嵌入层,误差通过反向传播可以继续传递到这个词嵌入矩阵并更新它。所以我们的词向量就可以像卷积神经网络中的卷积核那样,在训练的时候不断学习,最后自己学习到合适的词向量表示。
如果这个视频非常好看这句话和这个视频非常精彩这句话属于同一类,那么在训练的激励下,好看和精彩这两个词的词向量数据最后必然会很接近。

每个维度的特征含义通过后续的训练已经很抽象了,我们可能无法明确每个特征到底是什么含义,就像卷积神经网络中最后训练出的卷积核在提取什么已经很抽象了,可能是边缘,可能是轮廓,也可能不是,但我们知道它肯定捕捕捉到的一些特征。

在训练的时候,顺便训练词嵌入矩阵是一种方法,但词向量矩阵要训练的恰当合理,显而易见的是需要海量的文本和词汇。但如果我们去构建一个具体应用时,比如我们开头说判断一个评论区评论的感情,我们可能只能得到并不多的文本,几百条或者几千条的样子,但转念一想,语言这东西是有共性的,比如狗这个词是名词,是动物,有尾巴,有皮毛,这件事情正常来说在哪里都是这样。所以更加常见的做法是去使用别人在海量数据上训练好的磁向量数据应用到我们自己的过程中,而不是自己在这些少量的数据集上训练词向量。
词向量算法
常见的词向量训练算法有worf2vec和Glove,这两个算法细节上比较琐碎,我们的课程就不展开讲解了,你只需要知道他们都是在自然语言处理领域流行的词向量训练算法就好。所以我们可以去网上下载他人利用这些算法训练好的数据,然后把我们自己的词嵌入矩阵给替换掉,同时在训练的时候冻结这个嵌入层,让它在我们的训练中不再更新。
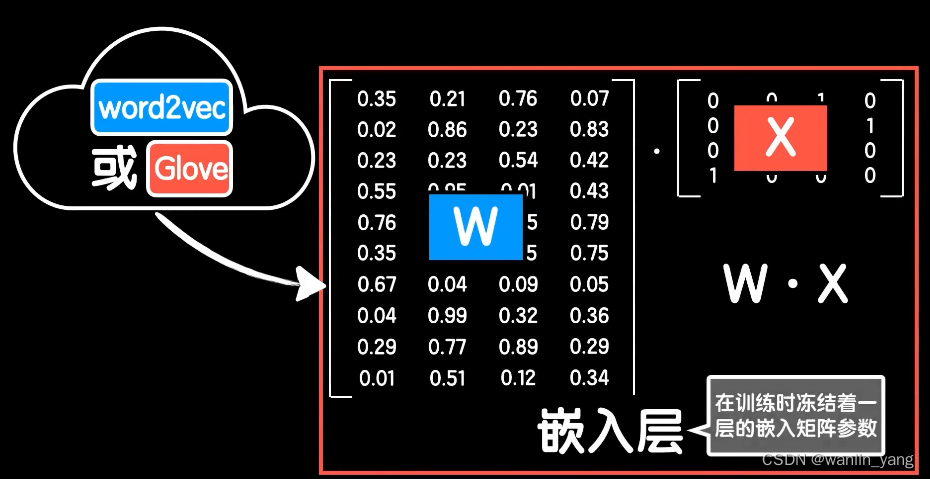 这是一种迁移学习的手段,这种站在巨人肩膀上的想法在软件过程中十分常用。回过头来想想,我们在做图像识别的时候,因为对图像特征提取的方式也具备可迁移性,所以我们可以把别人训练好的参数直接迁移到自己的工程上,然后简单的处理一些细节问题,这要比我们在只有少量数据集的情况下从零开始训练要高效许多。
这是一种迁移学习的手段,这种站在巨人肩膀上的想法在软件过程中十分常用。回过头来想想,我们在做图像识别的时候,因为对图像特征提取的方式也具备可迁移性,所以我们可以把别人训练好的参数直接迁移到自己的工程上,然后简单的处理一些细节问题,这要比我们在只有少量数据集的情况下从零开始训练要高效许多。

这种语言序列类型的数据在时间上有关联性。比如通过训练,我们知道“这个视频非常好看”,是一个正向的评论,但如果在测试机上遇到这样的一个评论,“这个视频非常不好看”。“因为有非常好看”这样正面的词汇,所以神经网络很容易就把它判定为一个正面的评论,但因为有“不” 这个词的修饰,所以意思就发生了完全的反转。我们不能忽视语言数据在时间上的关联性,所以我们的神经网络必须要有处理这种关联性的能力。
二、编程实验
1.下载一份网购评论数据集:online_shopping_10_cats.csv
文中数字是情感标签数据,1是正面评价,0是负面评价。

2.数据操作封装工具:shopping_data.py
代码中encoding='gb18030',因为对中文编码,不能是UTF-8,gbk也不行
import os #os模块提供的就是各种 Python 程序与操作系统进行交互的接口。
import keras
import numpy as np
import keras.preprocessing.text as text
import re #re模块,正则表达式
import jieba
import random
def load_data():
xs = []
ys = []
with open(os.path.dirname(os.path.abspath(__file__))+'/online_shopping_10_cats.csv','r',encoding='gb18030') as f:
line=f.readline()#escape first line"label review"
while line:
line=f.readline()
if not line:
break
contents = line.split(',')
if contents[0]==" 书籍":
continue
label = int(contents[1])
review = contents[2]
if len(review)>1000:
continue
xs.append(review)
ys.append(label)
xs = np.array(xs)
ys = np.array(ys)
#打乱数据集
indies = [i for i in range(len(xs))]
random.seed(666)
random.shuffle(indies)
xs = xs[indies]
ys = ys[indies]
m = len(xs)
cutpoint = int(m*4/5)
x_train = xs[:cutpoint]
y_train = ys[:cutpoint]
x_test = xs[cutpoint:]
y_test = ys[cutpoint:]
print('总样本数量:%d' % (len(xs)))
print('训练集数量:%d' % (len(x_train)))
print('测试集数量:%d' % (len(x_test)))
return x_train,y_train,x_test,y_test
def createWordIndex(x_train,x_test):
x_all = np.concatenate((x_train,x_test),axis=0)
#建立词索引
tokenizer = text.Tokenizer()
#create word index
word_dic = {}
voca = []
for sentence in x_all:
# 去掉标点
sentence = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+", "", sentence)
# 结巴分词
cut = jieba.cut(sentence)
#cut_list = [ i for i in cut ]
for word in cut:
if not (word in word_dic):
word_dic[word]=0
else:
word_dic[word] +=1
voca.append(word)
word_dic = sorted(word_dic.items(), key = lambda kv:kv[1],reverse=True)
voca = [v[0] for v in word_dic]
tokenizer.fit_on_texts(voca)
print("voca:"+str(len(voca)))
return len(voca),tokenizer.word_index
def word2Index(words,word_index):
vecs = []
for sentence in words:
# 去掉标点
sentence = re.sub("[\s+\.\!\/_,$%^*(+\"\']+|[+——!,。?、~@#¥%……&*()]+", "", sentence)
# 结巴分词
cut = jieba.cut(sentence)
#cut_list = [ i for i in cut ]
index=[]
for word in cut:
if word in word_index:
index.append(float(word_index[word]))
# if len(index)>25:
# index = index[0:25]
vecs.append(np.array(index))
return np.array(vecs)
3.jieba库安装
jieba库是一款优秀的 Python 第三方中文分词库,具体安装方法和应用,请读者挪步:
import shopping_data
x_train, y_train, x_test, y_test = shopping_data.load_data()
# 打印数据集
print('x_train.shape:', x_train.shape)
print('y_train.shape:', y_train.shape)
print('x_test.shape:', x_test.shape)
print('y_test.shape:', y_test.shape)
print(x_train[0])
print(y_train[0])
E:\python\人工智能\lesson12>python comments_recognizer0.py
总样本数量:3658
训练集数量:2926
测试集数量:732
x_train.shape: (2926,)
y_train.shape: (2926,)
x_test.shape: (732,)
y_test.shape: (732,)
""在等待书的几天里,我一直戴着一个液压油封,换过来换过去,身边的人都不知道我戴的是什么,我告诉他们是提高运动灵感对抗疲劳的。昨天快递公司来电话预约今天上午送货,但上午在家没等到快递员,下午要开会,于是出了门,走在路上,给快递员打电话,不料快递员当时和我距离不到100米,于是很顺利拿到书。似乎是“吸引定律”发挥了作用,“寻找你就能找到。”拿到书和紫手环了
1
5.文本分类神经网络代码comments_recognizer.py
import shopping_data
from keras.utils import pad_sequences# 数据对齐
from keras.models import Sequential#堆叠神经网络序列的载体
from keras.layers import Dense, Embedding #引入全连接层,一层神经网络;引入嵌入层
from keras.layers import Flatten# 数组平铺
x_train, y_train, x_test, y_test = shopping_data.load_data()
# 打印数据集
# print('x_train.shape:', x_train.shape)
# print('y_train.shape:', y_train.shape)
# print('x_test.shape:', x_test.shape)
# print('y_test.shape:', y_test.shape)
# print(x_train[0])
# print(y_train[0])
#第一步,把数据集中所有的文本转化为词典的索引值,程序去遍历语料中的句子,那如果是中文,就进行分词
vocalen, word_index = shopping_data.createWordIndex(x_train, x_test)
#vocalen为这个词典的词汇数量, word_index为训练集和测试集全部预料的词典
print(word_index)
print('词典总词数:', vocalen)
# 第二步,将每句话转化为索引向量
x_train_index = shopping_data.word2Index(x_train, word_index)
x_test_index = shopping_data.word2Index(x_test, word_index)
#第三步 ,每一句话的索引向量个数不一样,我们需要把序列按照maxlen对齐
maxlen = 25
x_train_index = pad_sequences(x_train_index, maxlen=maxlen)
x_test_index = pad_sequences(x_test_index, maxlen=maxlen)
# 神经网络模型
model = Sequential()
model.add(
Embedding(
trainable=False, # 是否可训练:是否让这一层在训练的时候更新参数
input_dim=vocalen, # 输入维度,所有词汇的数量
output_dim=300, # 输出维度,每个词向量的特征维度
input_length=maxlen # 序列长度,每句话长度为25的对齐
)
)
# 数据平铺
model.add(Flatten())
# 创建全连接层,三个隐藏层
model.add(Dense(256, activation='relu'))
model.add(Dense(256, activation='relu'))
model.add(Dense(256, activation='relu'))
# 二分类问题,使用sigmoid激活函数
model.add(Dense(1, activation='sigmoid'))
# 配置模型
model.compile(
loss='binary_crossentropy', # 适用于二分类问题的交叉熵代价函数
optimizer='adam', # adam是一种使用动量的自适应优化器,比普通的sgd优化器更快
metrics=['accuracy']
)
#loss(损失函数、代价函数):binary_crossentropy适用于二分类问题的交叉熵代价函数
# optimizer(优化器):adam是一种使用动量的自适应优化器,比普通的sgd优化器更快
# metrics(评估标准):accuracy(准确度);
#训练数据fit, batch_size送入批次的数据,显卡越好,可以送的数据越多,只能用CPU训练,batch_size就设置小一点
model.fit(x_train_index, y_train, batch_size=512, epochs=200)
# 用来测试集上的评估
score, acc = model.evaluate(x_test_index, y_test)
print('Test score:', score)
print('Test accuracy:', acc)送入神经网络前的文本数据的预处理:
第一步把数据集中所有的文本转化为词典的索引值,用程序去遍历语料中的句子,那如果是中文,就进行分词,在这个过程中,统计全体语料上所有的词语,比如是5000个,那么就可以把这5000个词,放在Python的一个数组或者字典的结构中,你可以通过读音,对它们进行排序;当然你可以不排序,就使用随机的顺序,反正不论怎样,每个词就会在数组或者字典里有一个位置的索引。
第二步,将每句话转化为索引向量。

第三步,每一句话的索引向量个数不一样,我们需要把序列按照maxlen对齐,形成一个整齐的张量。pad_sequences()函数。

嵌入层的trainable:

得出结果:
trainable=False,不训练词嵌入矩阵,测试集准确率为73.08%
trainable=True,训练词嵌入矩阵,测试集准确率为81.69%
可以看出,训练词嵌入矩阵的准确率明显提高。


三、总结
本节课介绍了神经网络该如何去识别和处理有关文字的时间依赖问题,编程实验为用神经网络对文本分进行类。下节课会用卷积操作把一个神经网络改造成为适合图像数据的卷积神经网络一样,我们把神经网络改造成为适合序列数据的结构。
四、往期内容

12.循环:序列依赖问题
13.LSTM网络:自然语言处理实践
14.机器学习:最后一节课也是第一节课
视频链接:
https://pan.baidu.com/s/1CY8j9XcYONS7Fs0Yl2Kj0A?pwd=h0x7
















 1855
1855











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









