







系列文章目录
学习型索引结构---开山之作学习 The Case for Learned Index Structures
学习索引--A Critical Analysis of Recursive Model Indexes(2021) (上)
学习型索引结构--ALEX: An Updatable Adaptive Learned Index
前言
因为实验室的方向,暑假准备开始学习学习型索引结构。前段时间刚刚学习了学习型索引的开山之作,今天学习它之后同一个团队出的改进学习型索引的一篇论文ALEX: An Updatable Adaptive Learned Index。我们要清楚的认识到。学习型索引结构的关键思想是,索引可以被认为是预测数据集中键的位置的“模型”。因此,索引是可以学习的。
一、ALEX是什么?
定义:一个可更新的自适应学习索引。
ALEX有效地将学习索引的核心见解与经过验证的存储和索引技术相结合,以实现高性能和低内存占用。在只读工作负载上,ALEX在性能上比Kraska等人的学习索引高出2.2倍,索引大小减少了15倍。在读写工作负载的范围内,ALEX比B+Trees高出4.1倍,而性能从未更差,索引大小减少了2000倍。
二、创新点
The Case for Learned Index Structures,提出了一个模型,我们将其称为“学习索引”。提出用机器学习(ML)模型的层次结构取代标准数据库索引。给定一个键,层次结构中的中间节点是用于预测要使用的子模型的模型,而该层次结构中的叶节点是用于预测键在密集排列数组中的位置的模型(图1)。该学习索引的模型是从数据中训练的。他们的关键见解是,使用(即使是简单的)适应数据分布的模型来对键的实际位置做出“足够好”的猜测,从而显著提高性能。但是,他们的解决方案只能处理对只读数据的查找,不支持更新操作。
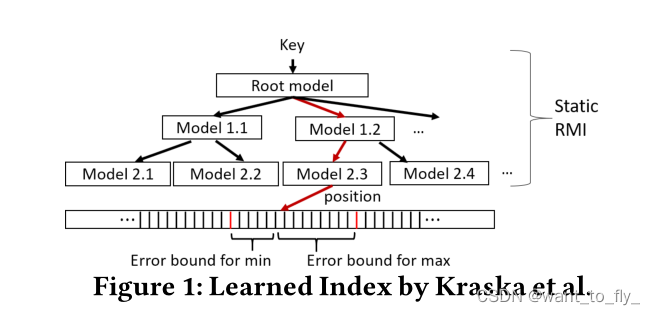
这个严重的缺点使得习得索引无法用于实践中常见的动态读写工作负载。
为了解决上述问题,提出了ALEX它解决了在为包含点查找、短范围查询、插入、更新和删除的工作负载实现学习索引时出现的实际问题。
- 针对模型优化的存储布局:类似于B+树,ALEX构建了一个树,但允许不同节点以不同的速率增长和收缩。为了在数据节点中存储记录,ALEX使用了一个带间隙的数组,一个间隙数组,它(1)平摊每次插入移动键的成本,因为间隙可以吸收插入,(2)使用基于模型的插入允许更准确地放置数据,以确保记录尽可能靠近预测位置。为了高效搜索,空白实际上是由相邻的键填充的。
- 针对模型优化的搜索策略:ALEX利用基于模型的插入与从预测位置开始的指数搜索相结合。当模型准确时,这总是胜过二分搜索。
- 通过动态数据分布和工作负载保持模型的准确性:即使在数据分布倾斜或索引初始化后发生动态变化时,ALEX也提供了健壮的性能。ALEX通过利用自适应扩展和节点分裂机制,以及基于简单成本模型的智能策略触发的选择性模型再训练来实现这一目标。我们的成本模型考虑了实际的工作量,因此可以有效地响应工作量的动态变化。ALEX实现了上述所有优点,而无需为每个数据集或工作负载手动调整参数。
- 详细评估:我们展示了对真实数据集和不同读写工作负载的广泛实验分析的结果,并与支持范围查询的最新索引进行了比较。
ALEX旨在实现以下目标,除了B+树和学习索引。(1)插入时间应与B+Tree竞争;(2)查找时间应比B+Tree和Learned Index快;(3)索引存储空间应小于B+Tree和Learned Index;(4)数据存储空间(叶级)应与动态B+Tree相当。
三、ALEX 概述

3.1数据节点

3.2 内部节点
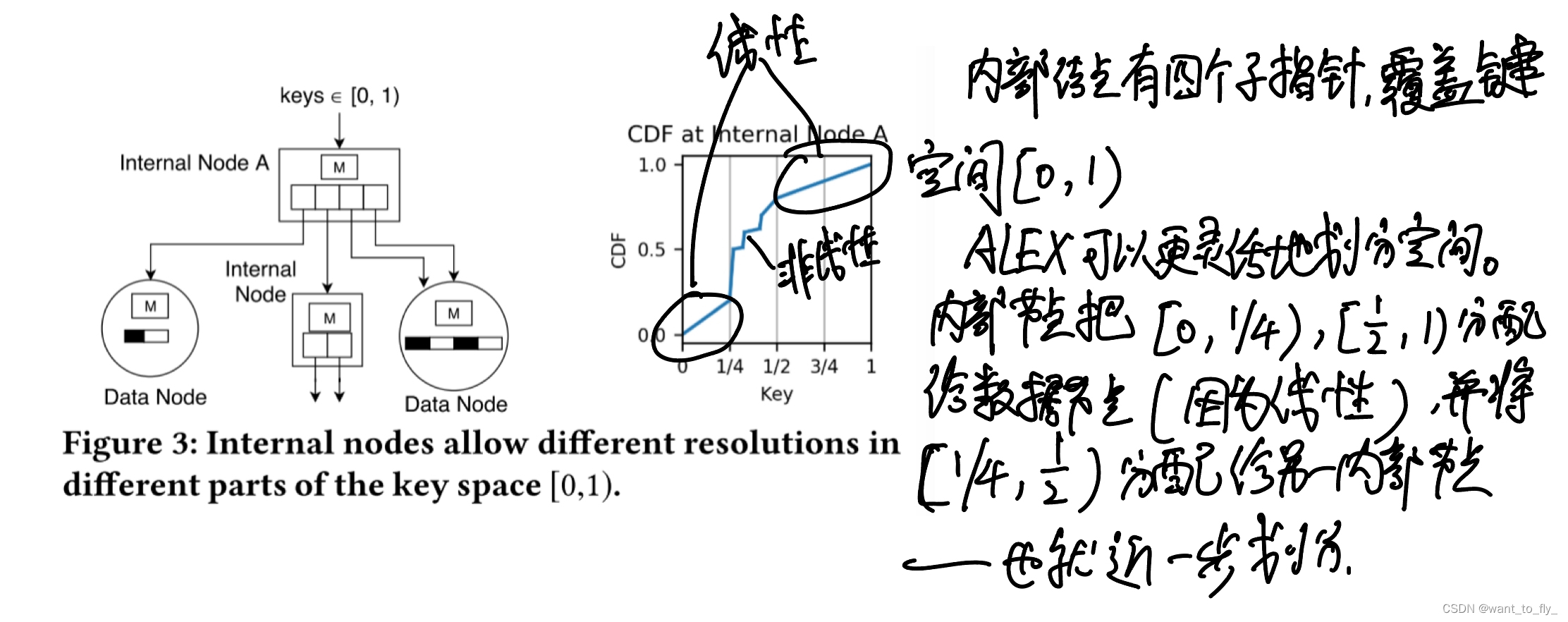
四 ALEX算法
4.1 Lookups and Range Queries(查找和范围查询)
以上面的Figure 2为例(红色箭头)。为了查找一个键,从RMI的根节点开始,我们迭代地使用模型来“计算”指针数组中的一个位置,然后我们跟随指针到下一级的子节点,直到我们到达一个数据节点。我们利用模型在数据节点中预测搜索键在键数组中的位置,如果需要的话进行指数搜索,找到键的实际位置.如果找到key,我们从payloads数组中读取相同位置的相应值并返回记录。否则,我们返回一个空记录。
范围查询首先执行查找以找到其值不小于范围的开始值的第一个键的位置和数据节点,然后向前扫描直到到达范围的结束值,使用节点的位图跳过间隙,并且如果必要的话使用存储在节点中的指针跳转到下一个数据节点。
4.2 Insert in non-full Data Node(插入非完整数据节点)
在非完整数据节点中,为了找到新元素的插入位置,我们使用数据节点中的模型来预测插入位置。如果预测的位置不正确(如果在那里插入不会保持排序顺序),我们进行指数搜索以找到正确的插入位置。如果插入位置是一个间隙,那么我们将元素插入间隙中并完成。否则,我们通过在最近间隙的方向上将元素移动一个位置来在插入位置处形成间隙。然后我们将元素插入到新创建的间隙中。Gapped Array以高概率实现O(log n)插入时间。
4.3 Insert in full Data Node(插入完整数据节点)
4.3.1节点满度的标准
间隙阵列上的插入性能会随着间隙数量的减少而下降,所以ALEX不会等待数据节点100%满。在间隙阵列上引入了密度下限和上限:dl,du ∈(0,1],约束dl <du。密度被定义为被元素填充的位置的分数。如果下一次插入导致超过du,则节点已满。我们设置dl =0.6和du =0.8,以实现平均数据存储利用率为0.7,类似于B+Tree [14],根据我们的经验,B + Tree总是产生良好的结果,并且不需要调整。相比之下,B+树节点通常具有dl =0.5和du =1。
4.3.2节点扩展机制
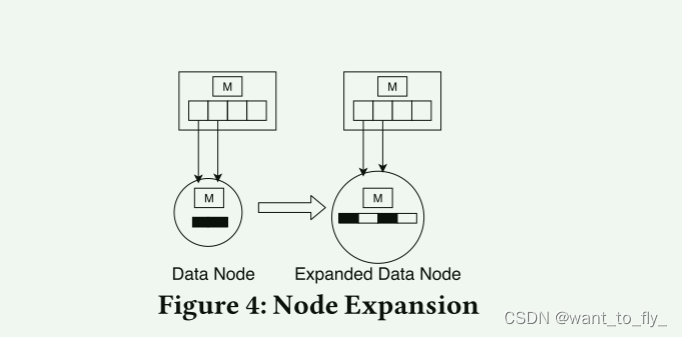
为了扩展包含n个键的数据节点,我们分配了一个新的更大的Gapped Array,其中有n/dl个插槽。然后,我们缩放或重新训练线性回归模型,然后使用缩放或重新训练的模型在这个新的更大的节点中进行基于模型的所有元素的插入。在创建之后,新数据节点处于密度下限dl。图4示例数据节点扩展,其中数据节点内的间隙阵列从左侧的两个槽扩展到右侧的四个槽。
4.3.3节点拆分机制。
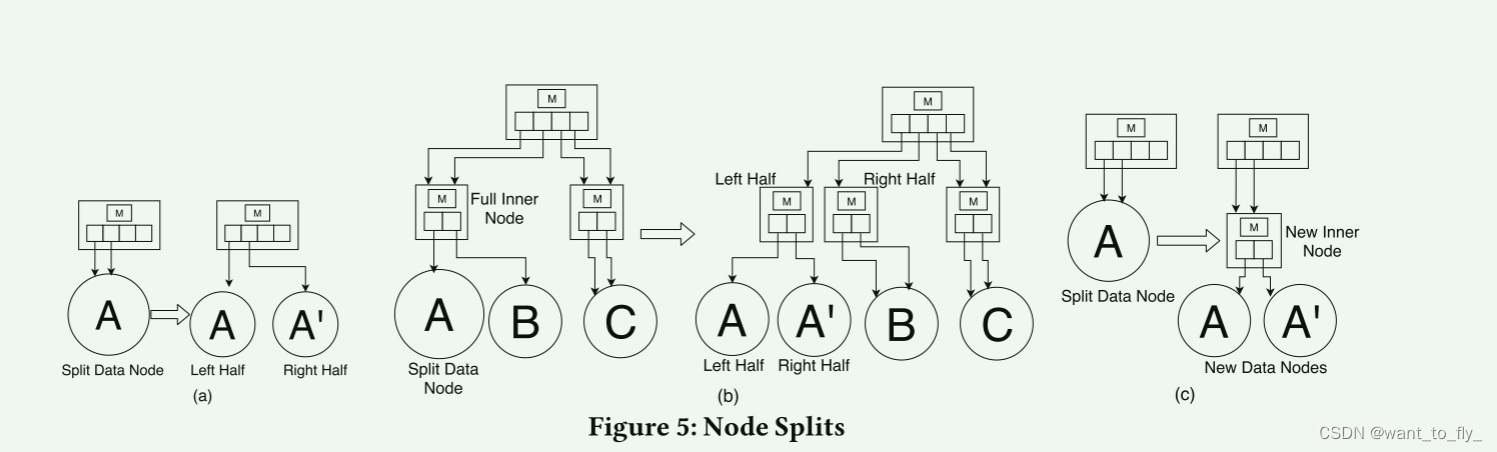
为了将一个数据节点一分为二,我们将keys分配给两个新的数据节点,使得每个新节点负责原始节点的key空间的一半。ALEX支持两种拆分节点的方法:
(1)横向拆分:
(a)如果分裂数据节点的父内部节点尚未处于最大节点大小,则我们用指向两个新数据节点的指针替换父节点指向分裂数据节点的指针。父内部节点的指针数组可能具有指向拆分数据节点的冗余指针。见图Figure 3.如果是这样,我们给两个新节点中的每个节点给予一半的冗余指针。否则,我们通过将父节点的指针数组的大小加倍并为每个指针制作冗余副本来创建指向拆分数据节点的第二个指针,然后将冗余指针中的一个指向两个新节点中的每一个。图5a示出了不需要父内部节点的扩展的侧向拆分的示例。
(b)如果父内部节点已经达到最大节点大小,那么我们可以选择拆分父内部节点,如图5b所示。请注意,通过将所有内部节点大小限制为2的幂,我们总是可以以“边界保持”的方式分割节点,因此不需要对任何模型进行再训练,以降低分割的内部节点。
(2)向下拆分
拆分将数据节点转换为具有两个子数据节点的内部节点,如图5C所示。两个子数据节点中的模型在它们各自的键上进行训练。B+ Tree没有类似的拆分机制。
4.3.4插入算法
根据我们的经验,50%的成本偏差阈值总是产生良好的结果,不需要调整。否则,如果经验成本偏离预期成本,我们必须(i)扩展数据节点并重新训练模型,(ii)横向拆分数据节点,或(iii)向下拆分数据节点。我们根据我们的节点内成本模型,选择导致期望成本最低的操作。为简单起见,ALEX总是将数据节点一分为二。数据节点可以在概念上分裂成2的任何幂,但决定最佳扇出可能是耗时的,我们通过实验验证了2的扇出是最好的根据成本模型在大多数情况下。
4.4 Delete, update, and other operations(删除、更新和其他操作)
要删除一个键,我们需要查找该键的位置,然后删除它及其有效负载。删除不会移动任何现有关键帧,因此删除操作比插入操作简单得多,不会导致模型精度降低。如果数据节点由于删除而达到密度下限dl,则我们收缩数据节点(即,与扩展数据节点相反)以避免低空间利用率。此外,我们可以使用节点内成本模型来确定两个数据节点应该合并在一起并可能向上增长,从而将RMI深度局部减少1。然而,为了简单起见,我们不实现这些合并操作。
修改键的更新是通过组合插入和删除来实现的。仅修改有效负载的更新将查找键并将新值写入有效负载。
代码介绍

定义结构体 Node:
Node是 GappedArray 的节点结构,包含以下成员:keys[]:数组,存储实际的元素值。num_keys:整数,表示当前节点中的元素数量。du和dl:参数,用于决定何时扩展数组。

插入操作 Insert(key):
- 当前节点元素数量超过阈值
du时,需要进行扩展。根据预测开销和实际开销的对比,决定是否进行扩展或其他操作。 - 根据模型预测
model.predict(key),找到正确的插入位置insert_pos。 - 如果该位置已经被占用,则进行移动操作,以腾出空间,并将元素插入到正确的位置。

扩展操作 Expand(retrain):
- 根据当前节点的元素数量和参数
dl,计算扩展后的数组大小expanded_size。 - 如果需要重新训练模型,执行
retrain == True分支,在新的扩展数组上重新训练模型。 - 否则,根据
expanded_size / keys.size缩放现有模型,将模型应用到新的扩展数组中。 - 按照模型预测的顺序,将现有数组中的元素依次插入到新的扩展数组中。

模型预测和排序:
- 在插入操作和扩展操作中,使用
model.predict(key)函数对元素进行模型预测,预测插入的位置。
4.5处理越界插入
低于或高于现有键空间的键将分别插入到最左边或最右边的数据节点中。一系列越界插入(例如仅追加插入工作负载)将导致性能低下,因为该数据节点没有拆分越界键空间的机制。
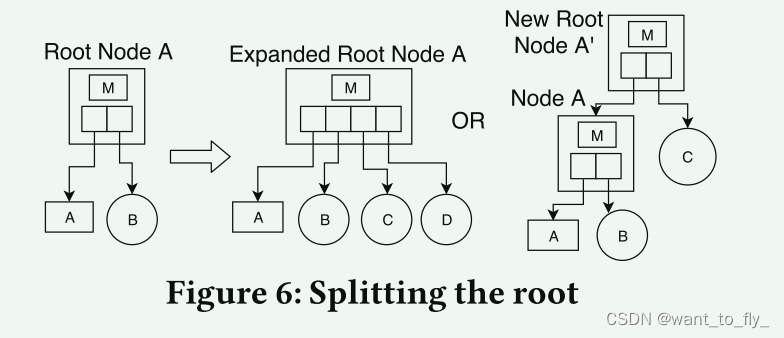
首先,当检测到现有密钥空间之外的插入时,ALEX将扩展根节点,从而扩展密钥空间,如图6所示。我们向右扩展子指针数组的大小。指向现有子级的现有指针不会被修改。为扩展指针数组中的每个新槽创建新数据节点。如果此扩展将导致根节点超过最大节点大小,ALEX将创建新的根节点。新根节点的第一子指针将指向旧根节点,并且为新根节点的每隔一个指针槽创建新数据节点。在此过程结束时,越界键将落入新创建的数据节点之一。
其次,ALEX的最右边的数据节点通过维护节点中的最大键的值并保持插入超过该最大值的次数的计数器来检测仅追加插入行为。如果大多数插入超过了最大值,这意味着只添加行为,所以数据节点向右扩展而不进行基于模型的重新插入;扩展的空间最初保持为空,以预期更多的附件状插入物。
总结
ALEX的论文随笔就到着结束了,ALEX的代码我也运行成功了,接下来粗略看看,到时候写点关于博客的随笔。

















 1398
1398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









