







我们把智能体放到环境的任意状态;
从这个状态开始按照策略进行选择动作,并进入新的状态。
重复步骤2,直到最终状态;
我们从最终状态开始向前回溯:计算每个状态的G值。
重复1-4多次,然后平均每个状态的G值,这就是我们需要求的V值。

第一步,我们根据策略往前走,一直走到最后,期间我们什么都不用算,还需要记录每一个状态转移,我们获得多少奖励r即可。
第二步,我们从终点往前走,一遍走一遍计算G值。G值等于上一个状态的G值(记作G'),乘以一定的折扣(gamma),再加上r。
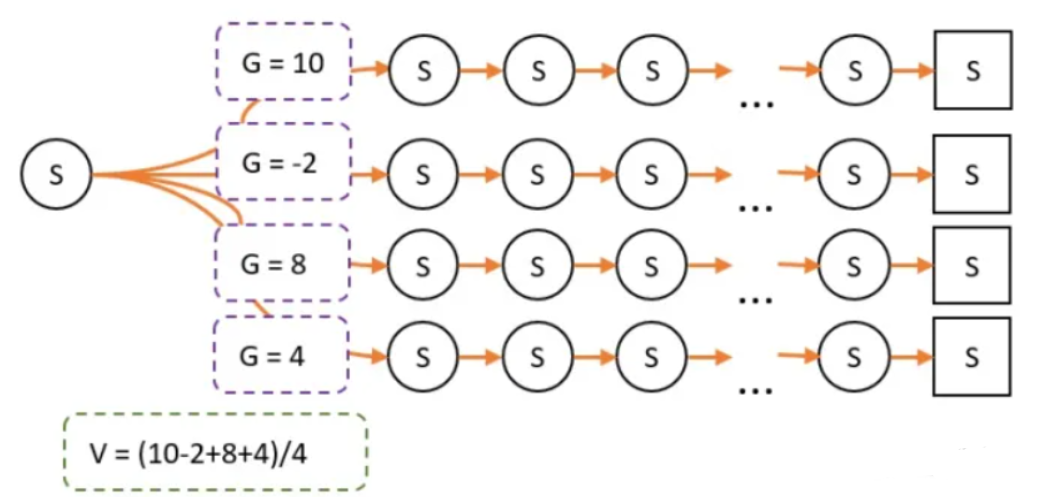
G的意义:在某个路径上,状态S到最终状态的总收获。
V和G的关系:V是G的平均数。
由于策略改变,经过某条路径的概率就会产生变化。因此最终试验经过的次数就不一样了。
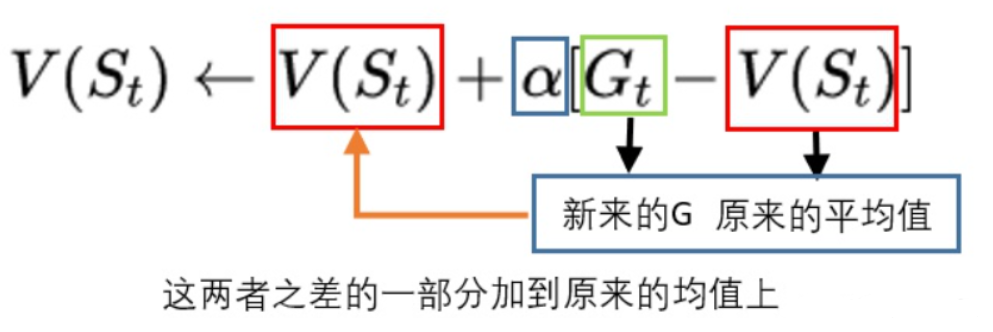
缺点:
每一次游戏,都需要先从头走到尾,再进行回溯更新。如果最终状态很难达到,那小猴子可能每一次都要转很久很久才能更新一次G值。
如何解决:
时序差分(TD)算法
















 5397
5397

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











