







 Q值代表智能体选择特定动作后预期的奖励总和,而V值表示处于某一状态时预期的奖励总和。V值可通过所有动作的Q值在策略下的期望来计算,反之,Q值是基于V值和状态转移概率的期望奖励。
Q值代表智能体选择特定动作后预期的奖励总和,而V值表示处于某一状态时预期的奖励总和。V值可通过所有动作的Q值在策略下的期望来计算,反之,Q值是基于V值和状态转移概率的期望奖励。
定义 - 评估动作的价值,我们称为Q值:它代表了智能体选择这个动作后,一直到最终状态奖励总和的期望
评估状态的价值,我们称为V值:它代表了智能体在这个状态下,一直到最终状态的奖励总和的期望
价值越高,表示我从当前状态到最终状态能获得的平均奖励将会越高
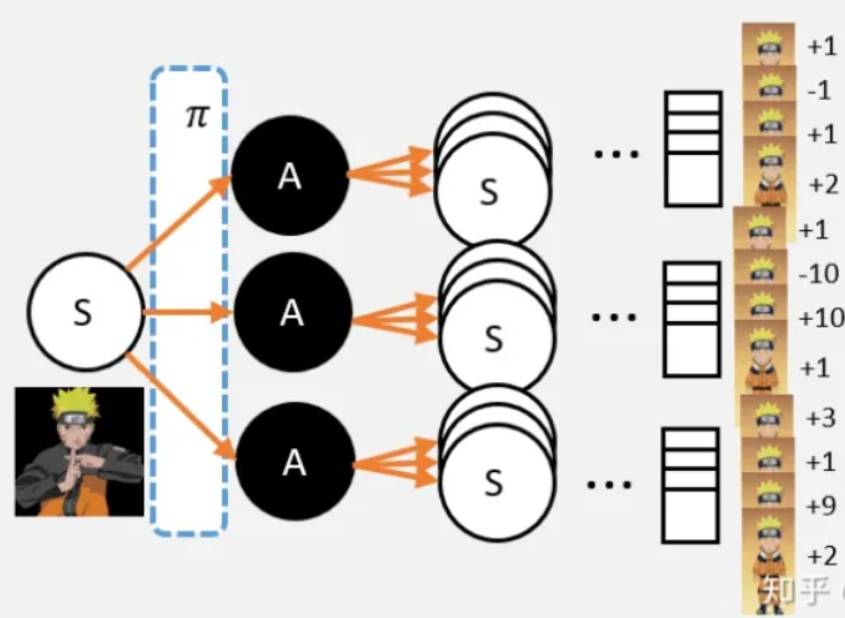
V值的定义
假设现在需要求某状态S的V值,那么我们可以这样:
我们从S点出发,并影分身出若干个自己;
每个分身按照当前的策略选择行为;
每个分身一直走到最终状态,并计算一路上获得的所有奖励总和;
我们计算每个影分身获得的平均值,这个平均值就是我们要求的V值。
Q值的定义
只不过V值衡量的是状态节点的价值,而Q值衡量的是动作节点的价值。
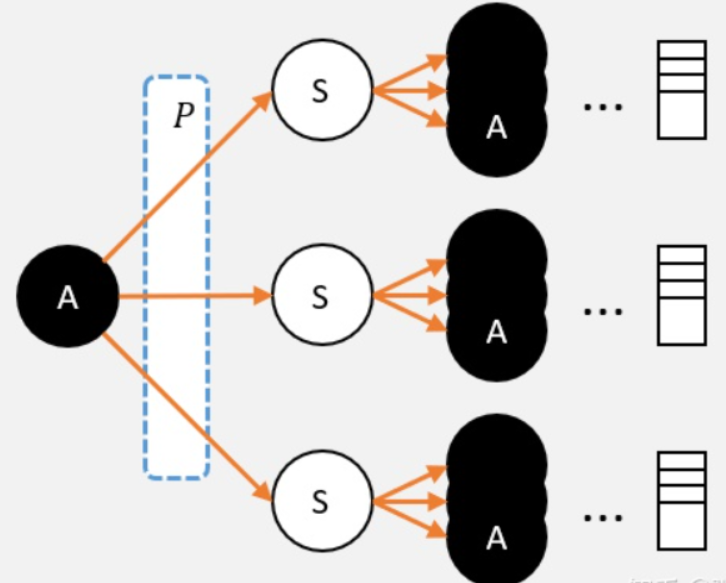
现在我们需要计算,某个状态S0下的一个动作A的Q值:
我们就可以从A这个节点出发,使用影分身之术;
每个影分身走到最终状态,并记录所获得的奖励;
求取所有影分身获得奖励的平均值,这个平均值就是我们需要求的Q值。
V值和Q值关系计算
1、从Q到V
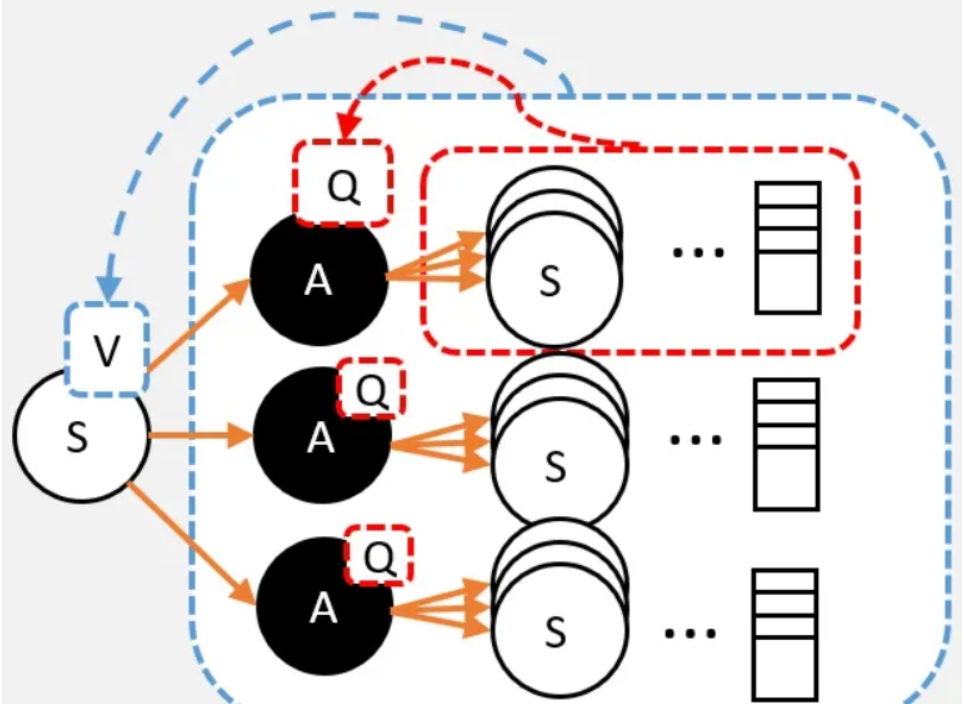
假设我们已经计算出每个动作的Q值,那么在计算V值的时候就不需要一直走到最终状态了,只需要走到动作节点,看一下每个动作节点的Q值,根据策略 ,计算Q的期望就是V值了。

一个状态的V值,就是这个状态下的所有动作的Q值,在策略下的期望
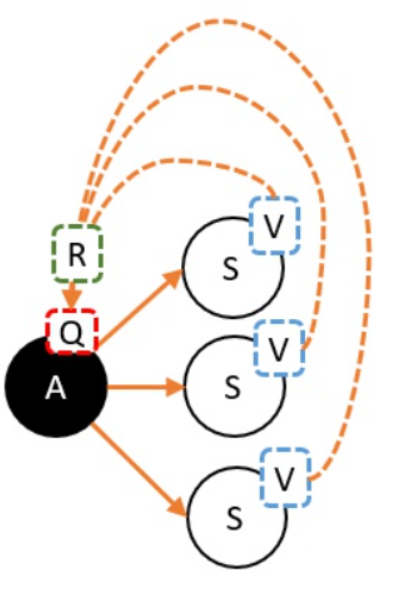
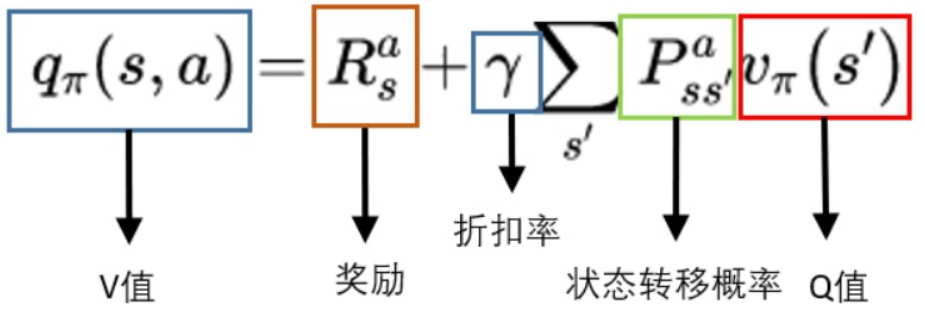
2、从V到Q
用Q就是V的期望,而且这里不需要关注策略,这里是环境的状态转移概率决定的。
当我们选择A,并转移到新的状态时,就能获得奖励,我们必须把这个奖励也算上!
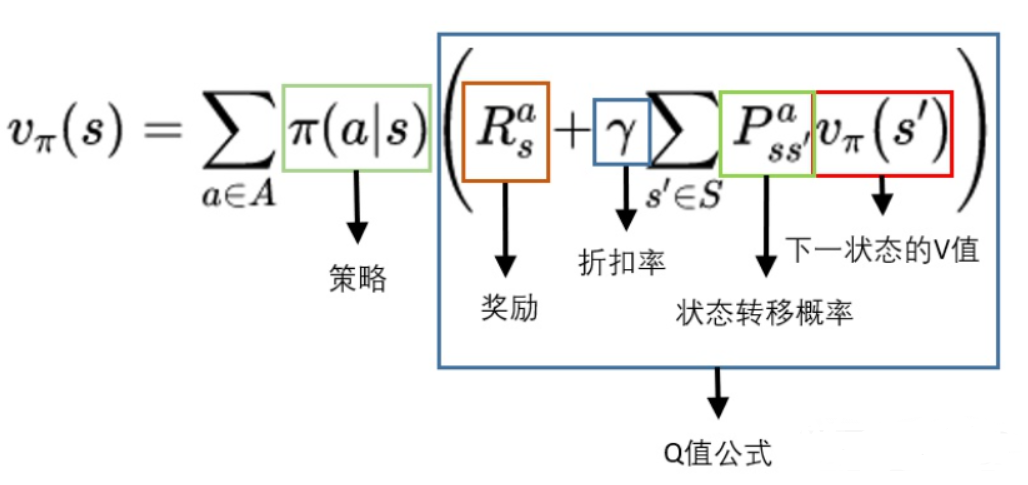
3、从V到V


















 2829
2829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











