







Pandas基础
首先感谢Datewhale组织的这次组队学习训练营,个人感觉Datewhale的助教非常给力,让本次学习之旅,多了不少乐趣,也开始了我的又一个学习笔记打卡之旅,请喜欢的朋友们关注,希望能给你们带来一些收获
所有资料可以参考:
https://github.com/datawhalechina/team-learning/tree/master/Pandas%E6%95%99%E7%A8%8B%EF%BC%88%E4%B8%8A%EF%BC%89
如有其它问题,可以给我留言。
笔记将从以下四个方面进行:

一、文件读取与写入

1. 读取
(a)csv格式
df = pd.read_csv('data/table.csv')
df.head()
#head( )函数的原型中,默认的参数size大小是 5,所以会返回 5 个数据。
(b)txt格式
df_txt = pd.read_table('data/table.txt') #可设置sep分隔符参数
df_txt
(c)xls或xlsx格式
#需要安装xlrd包
df_excel = pd.read_excel('data/table.xlsx')
df_excel.head()
2. 写入
(a)csv格式
#需要安装xlrd包
df_excel = pd.read_excel('data/table.xlsx')
df_excel.head()
(b)xls或xlsx格式
#需要安装openpyxl
df.to_excel('data/new_table2.xlsx', sheet_name='Sheet1')
(c)txt格式
df_txt.to_csv('data/new_table.txt')
二、基本数据结构
1. Series

是能够保存任何类型的数据(整数,字符串,浮点数,Python对象等)的一维标记数组。
(a)创建一个Series
对于一个Series,其中最常用的属性为值(values),索引(index),名字(name),类型(dtype)
–values: 参数
–index: 索引 索引值必须是唯一的和散列的,与数据的长度相同。 默认np.arange(n)如果没有索引被传递。
–dtype:输出的数据类型 如果没有,将推断数据类型
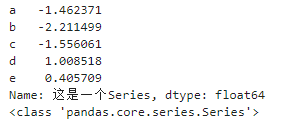
s = pd.Series(np.random.randn(5),index=['a','b','c','d','e'],
name='这是一个Series',dtype='float64')
print(s)
print(type(s))
(b)访问Series属性
s.values
s.values[4]
s.values[0:4]
s.name
s.index
s.dtype
(c)取出某一个元素
s['a']
(d)调用方法
s.mean()
更多Series有方法可以调用:
print([attr for attr in dir(s) if not attr.startswith('_')])
2. DataFrame

DataFrame()函数的参数index的值相当于行索引,若不手动赋值,将默认从0开始分配。columns的值相当于列索引,若不手动赋值,也将默认从0开始分配。

(a)创建一个DataFrame
df = pd.DataFrame({'col1':list('abcdefg'),'col2':range(5,12),
'col3':[1.3,2.5,3.6,4.6,5.8,6.3,7.2]},
index=list('一二三四五六七'))
df
(b)从DataFrame取出一列为Series
df['col1']
type(df)
type(df['col1'])
(c)修改行或列名
df_new = df.rename(index={'一':'one'},columns={'col1':'new_col1'})
df_new # 并不改变df本身的内容,而是生成了一个新的DataFrame
(d)调用属性和方法
df.index
df_new.index
df.columns
df.values
df.shape #不包含索引及名字所占的行列
df.mean()
(e)索引对齐特性
这是Pandas中非常强大的特性,不理解这一特性有时就会造成一些麻烦
df1 = pd.DataFrame({'A':[1,2,3]},index=[1,2,3])
df2 = pd.DataFrame({'A':[1,2,3]},index=[3,1,2])
# print (df1)
# print (df2)
df1-df2 #由于索引对齐,因此结果不是0
会自动按照索引值进行相减,得到如下结果:

df1 = pd.DataFrame({'A':[1,2,3]},index=[1,2,3])
df2 = pd.DataFrame({'A':[1,2,3]})
# print (df1)
# print (df2)
df1-df2 #由于索引对齐但df2的索引从0开始到2对应只有索引1和2可以相减,其余位置无索引,故值为NaN
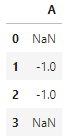
由于索引对齐,但df2的索引从0开始到2对应只有索引1和2可以相减,其余位置无索引,故值为NaN,所以在使用时,务必确保有相同的索引值
(f)列的删除与添加
对于删除而言,可以使用drop函数或del或pop
df.drop(index='五',columns='col1')
#设置inplace=True后会直接在原DataFrame中改动,否则df本身的值不变
df
#del
del df['col1'] #del操作会直接从df中删除,但不会返回被删除的列
df
pop方法直接在原来的DataFrame上操作,且返回被删除的列,与python中的pop函数类似
df['col1']=[1,2,3,4,5,6,7]
df.pop('col1') #pop方法直接在原来的DataFrame上操作,且返回被删除的列
df
可以直接增加新的列,也可以使用assign方法
df1['B']=list('abc') #会直接与之前索引对应,且改变df1
df1
df1.assign(C=pd.Series(list('def'),))
#C中Series会默认按索引range(3) 且assign不会改变df1
df1.assign(C=pd.Series(list('def'),index = [1,2,3])) #对齐后不会出现NaN值的情形
(g)根据类型选择列

df.select_dtypes(include=['float']).head()
df.select_dtypes(include=['number'])
(h)将Series转换为DataFrame
s = df.mean()
s.name='to_DataFrame'
s
s.to_frame()
使用T符号可以转置
s.to_frame().T
三、常用基本函数

从下面开始,包括后面所有章节,我们都会用到这份虚拟的数据集
df = pd.read_csv('data/table.csv')
#读入后,行索引按默认range(n),列索引为表格中第0行元素
1. head和tail
df.head() #读取前5行数据
df.tail() #读取后5行数据
df.head(3) #可指定范围n内的任意数
2. unique和nunique
df['Physics'].nunique() #nunique显示有多少个唯一值
df['Physics'].unique() #unique显示所有的唯一值
3. count和value_counts
count返回非缺失值元素个数
df['Physics'].count() #如果某行中数字缺失,则不会计数。
value_counts返回每个元素有多少个
df['Physics'].value_counts()
4. describe和info
info函数返回有哪些列、有多少非缺失值、每列的类型
df.info()
describe默认统计数值型数据的各个统计量
df.describe()
可以自行选择分位数
df.describe(percentiles=[.05, .25, .75, .95])
对于非数值型也可以用describe函数
df['Physics'].describe()
5. idxmax和nlargest
idxmax函数返回最大值所在的索引值,在某些情况下特别适用,idxmin功能类似
df['Math'].idxmax()
df['Math'].idxmin()
df['Math'].values[df['Math'].idxmin()]
nlargest函数返回前几个大的元素值,nsmallest功能类似
df['Math'].nlargest(3)
df['Math'].nsmallest(3)
6. clip和replace
clip和replace是两类替换函数
clip是对超过或者低于某些值的数进行截断
df['Math'].head()
df['Math'].clip(33,80).head() #低于33的数变为33,高于80的数为80
#不会改变原df的值
replace是对某些值进行替换,不改变原对象中的值
df['Address'].head()
df['Address'].replace(['street_1','street_2'],['one','two']).head()
通过字典,可以直接在表中修改
df.replace({'Address':{'street_1':'one','street_2':'two'}}).head()
7. apply函数
对于Series,它可以迭代每一行的值操作:
df['Math'].apply(lambda x:str(x)+'!').head()
#可以使用lambda表达式,也可以使用函数
df.apply(lambda x: print(x)) #遍历打印所有元素
对于DataFrame,它可以迭代每一个列操作:
df.replace({'Address':df.apply(lambda x:x.apply(lambda x:str(x)+'!')).head()
#对于第一个lambda函数中的x是不是可以看做是School,Class等列索引,后面一个lambda函数中的x看做是其对应所有的元素,用apply方法分别进行了遍历
更多关于apply函数的解释,可以参考:
#https://blog.csdn.net/stone0823/article/details/100008619
小提示: 不清楚函数传入了什么,就可以用lambda x:print(x)看一下
四、排序

1. 索引排序
df.set_index('Math').head()
#set_index函数可以设置索引,将在下一章详细介绍
df.set_index('Physics').sort_index()
#可以设置ascending参数,默认为升序,True
2. 值排序
df.sort_values(by='Class').head()
**注意:**如果Class相同,默认为快排,也可以选择归并排序和堆排序。
多个值排序,即先对第一层排,在第一层相同的情况下对第二层排序
df.sort_values(by=['Address','Height']).head()
五、问题与练习

练习题答案,文章开始github链接有的,相关数据也都在其中,可以下载,进行练习。
六、一些思考
初步学习下来,感觉可以通过以上操作,熟悉基本属性,但是要真正熟练掌握,还是需要多做练习题,多开脑洞。最后,欢迎留言一起讨论。















 6638
6638











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









