







solr的同步发行包smartcn可进行中文切词,smartcn的分词准确率不错,但就是不能自己定义新的词库,不过smartcn是跟solr同步的,所以不需要额外的下载,只需在solr的例子中拷贝进去即可。
第一步:
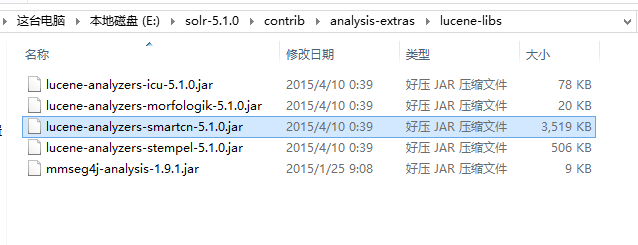
找到如上目录下面的smartcn包,复制。
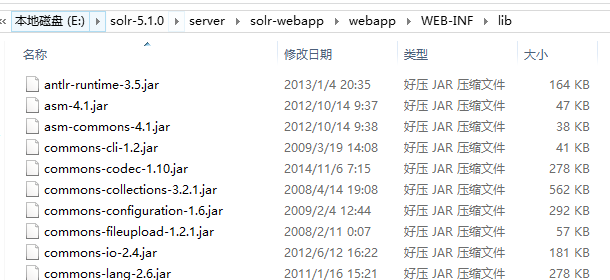
粘贴到上图目录下即可。
第二步:
在schema.xml中注册分词器:
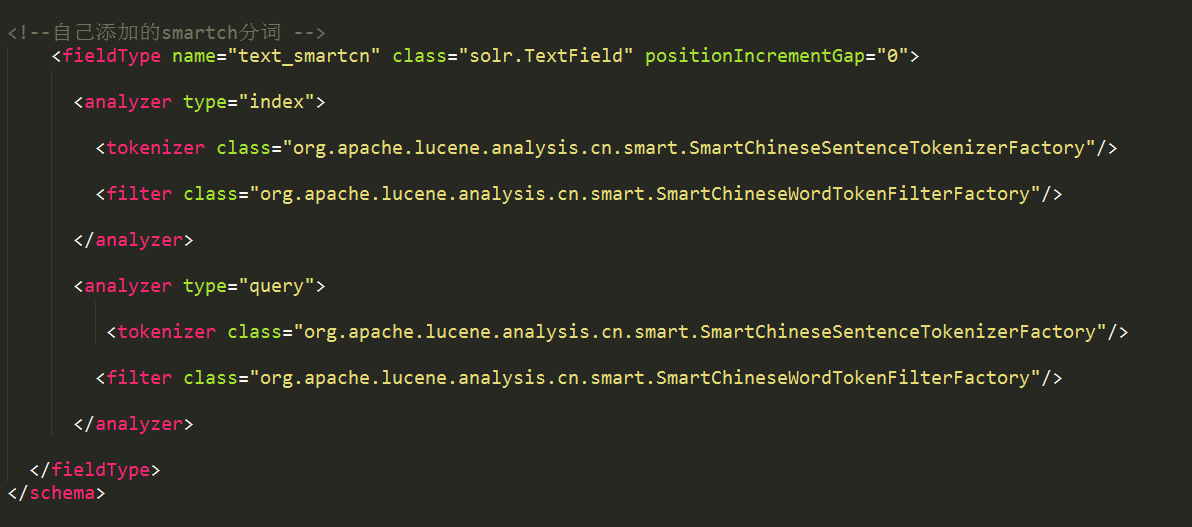
上图所示即为注册。

上图所示使用分词器即可大功告成。
solr的同步发行包smartcn可进行中文切词,smartcn的分词准确率不错,但就是不能自己定义新的词库,不过smartcn是跟solr同步的,所以不需要额外的下载,只需在solr的例子中拷贝进去即可。
找到如上目录下面的smartcn包,复制。
粘贴到上图目录下即可。
在schema.xml中注册分词器:
上图所示即为注册。
上图所示使用分词器即可大功告成。
 5634
5634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言



























