







 本文详细介绍了GMM-HMM在语音识别中的训练过程,包括数据预处理、模型初始化、单音素模型训练、上下文相关三音素模型的构建,并探讨了嵌入式训练中的Viterbi对齐和最大似然比更新。通过聚类算法优化状态绑定,最终得到三音素模型。
本文详细介绍了GMM-HMM在语音识别中的训练过程,包括数据预处理、模型初始化、单音素模型训练、上下文相关三音素模型的构建,并探讨了嵌入式训练中的Viterbi对齐和最大似然比更新。通过聚类算法优化状态绑定,最终得到三音素模型。
看了几天了,结合之前看kaldi里的训练,现在我觉得可以稍微清楚的解释这个训练过程,后面的时间赶紧看解码部分。希望你可以有所收获。
这次我们从头开始,虽然mfcc特征大家都知道,但是为了完整性还是说下吧。希望这是最后一次写训练的过程。
1.数据准备我就不说了,直接说提特征,一般来说提mfcc特征。当然在gmm-hmm中一般都是mfcc特征。mfcc特征的具体流程,这里贴一张图,大家可以参考。htk或者kaldi里都有提特征的脚本,也有源码,相信这个应该都不算难事了。
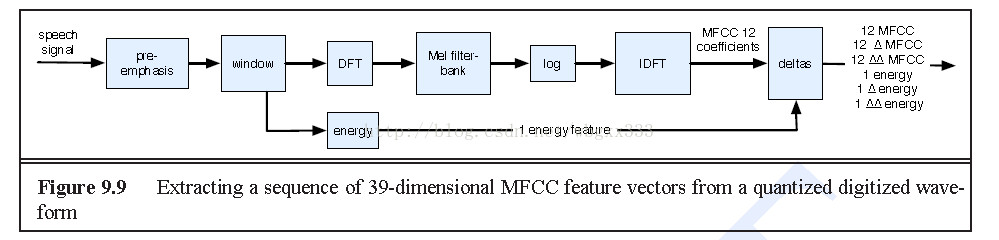
这个过程也比较清楚,这里就不多说了。
2.这里的特征提完了,接下里就是训练的事情。这里先做初始化的步骤,第一个初始化就是高斯模型的均值和方差,这里我们就用整个训练数据集的均值和方差来代替。注意这里应该是单高斯模型,用单高斯模型对每一帧数据进行建模,记住是每一帧(这里可能有错,也许是利用某个状态的观察变量来建立一个高斯)。还有一个初始化就是隐马尔科夫的参数,一般对音素用三个状态,这里除了开始和结束的三个。静音用5个状态。下图是一个音素的例子:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 354
354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









