







Interactive Object Segmentation With Inside-Outside Guidance翻译
Abstract
本文探讨了如何在最小化人类交互成本的同时获取精确的对象分割掩码。为实现这一目标,我们在这项工作中提出了一种内外指导 (IOG) 方法。具体来说,我们利用在对象中心附近单击的内部点和在包围目标对象的紧密边界框的对称角位置(左上角和右下角或右上角和左下角)的两个外部点。这导致总共有一次前景点击和四次背景点击用于分割。我们的 IOG 有四方面的优势:1)两个外部点可以帮助消除其他目标或背景的干扰; 2)内部点可以帮助消除边界框内无关区域的干扰; 3)内外点容易识别,减少最先进的DEXTR在标注一些极端样本时引起的混淆; 4)我们的方法自然支持更多的点击注释以进行进一步的修正。尽管它很简单,但我们的 IOG 不仅在几个流行的基准测试中实现了最先进的性能,而且还在街景、航拍图像和医学图像等不同领域展示了强大的泛化能力,无需微调。此外,我们还提出了一个简单的两阶段解决方案,使我们的IOG能够从现有数据集(如ImageNet和Open Image)的现成边界框中产生高质量的实例分段掩码,展示了我们的 IOG 作为注释工具的优越性。
1 Introduction
在过去的几年里,我们见证了语义[44,40,68,69,10,11,12,30,15,31]和实例分割[25,36,8,60,13,65,34,4,9,43,29]在不同领域的革命性进步,如一般场景[20,41,70],自动驾驶[17,48,21],航空图像[57,16],医疗诊断[22,56]等。成功的分割模型通常建立在大量高质量的训练数据之上。然而,创建构建这些模型所需的像素级别的训练数据的过程通常是昂贵、费力和耗时的。因此,交互式分割,它允许人类注释者通过提供一些用户输入,如边界框[66,52,64]或单击[67,38,45,37],来快速提取感兴趣的对象,似乎是减少注释工作量的一种有吸引力的和有效的方法。
最近,Maninis等[46]探索了使用对象的极值点(最左,最右,顶部,底部像素)进行交互式图像分割。尽管它很简单,但极值点在不同的应用领域展示了快速的交互式注释速度和高分割质量。然而,我们认为极端点的点击模式也带来了一些问题:1)注释极值点需要用户仔细地单击对象边界,这通常比普通的单击设置(用户可以单击对象区域的任何内部和外部)花费更多的时间;2)当多个极值点出现在相似的空间位置(图1(a)中的铅笔)或当目标对象内部有不相关的物体或背景(图1(a)中的狗)时,注释过程有时会令人困惑。

图 1. (a) DEXTR [46] 的用户输入。 (b) 拟议的 IOG 方法的用户输入。 © 我们的 IOG 框架概览。
为了解决上述问题以及提高交互过程的有效性和效率,我们提出了一种名为 Inside-Outside Guidance (IOG) 的方法,它只需要三个点(一个内点和两个外点)来指示目标对象。具体来说,内部点通常位于对象实例的中心周围,而两个外部点可以在包围目标实例的紧密边界框的任何对称角位置(左上角和右下角或右上角和左下角的像素)。图 1(b) 显示了我们提出的标记方案的两个示例。与 [46] 类似,我们的 IOG 在从输入图像裁剪,以包含上下文之前将生成的边界框扩展了几个像素。这导致总共有一个前景和四个背景点击(两个点击外部点和两个基于边界框的额外推断点),然后将其编码为前景/背景定位热图并与裁剪图像连接以训练分割网络。我们的 IOG 概览如图 1© 所示。
文章的方法是通过2个outside和1个inside点组合而成,其中2个outside点会通过推理得到另外的两个点,从而组成了包含目标的5个点,可以排除上述目标描述方式的缺陷,见上图(b)所示。
我们的 IOG 策略不仅通过减少 [46] 引起的混淆来提高注释速度,而且自然地支持在错误区域注释额外的点,以便进一步细化。我们在 PASCAL [20]、GrabCut [52] 和 COCO [41] 上进行了大量实验,以证明我们的 IOG 作为注释工具的有效性。特别是,仅给出三分,我们的 IOG 在 PASCAL 上获得了 93.2% 的 mIoU 分数,这是新的最先进的。当添加第 4 次点击进行交互式校正时,我们的 IOG 进一步提高到 94.4%。
此外,我们还表明我们的模型在跨域注释中具有很好的泛化能力,其中我们的 PASCAL 或 COCO 训练模型在注释街景 [17]、航拍图像 [57、16] 和医学图像 [22] 时生成高质量的分割掩码无需微调。除此之外,我们还提出了一个简单的两阶段解决方案,使我们的 IOG 能够从现成的数据集中收集精确的实例分割掩码,这些数据集带有边界框注释,例如 ImageNet [53] 和 Open Images [35],无需任何人工交互。最后,我们发布了 Pixel-ImageNet1,这是一个使用我们的 IOG 收集的具有 0.615M ImageNet [53] 实例掩码的数据集。我们希望这项工作可以大大有利于未来的研究人员收集大规模像素级注释。
2 Related Work
交互式分割:大多数交互式分割方法的目标是通过边界框[66,64,52]、点击[67,38,37,45]或轮廓[7,1,42]作为指导,在标记像素级注释时减轻人类的工作量。GrabCut[52]采用边界框来指导分割过程,是交互式分割任务的先驱作品之一。同样,Xu等人[66]也将边界框作为输入,训练深度卷积神经网络(CNN)进行交互式分割。另一方面,iFCN[67]通过引导用户点击的正点(前景)和负点(背景)的CNN进行交互式分割。RIS-Net[38]通过增加本地上下文分支来改进iFCN。最近,Maninis等[46]提出了仅利用4个极端点进行分割的DEXTR,实现了最新的技术水平。**与DEXTR相比,我们进一步推进了交互式注释过程,将所需的单击次数从4次减少到3次。**我们的IOG不仅解决了DEXTR提出的问题,而且还实现了更好的分割性能。除了上述方法外,还有一些文献[7,1,42]提出直接预测目标对象周围的多边形或样条进行交互式分割。
弱监督分割:在解决昂贵的像素级注释的许多替代方案中,弱监督学习在文献中得到了广泛的研究。其中,图像级标签[50,61,63,62,27,32]、点[3,51]、包围框[18,33]和涂鸦[39,58,59]被用作指导来监督语义分割网络的训练。与这些方法不同的是,我们提出的IOG仍然依赖于完全注释的掩码作为监督,并利用额外的三个点作为指导来生成目标对象的分割掩码。
语义分割:全卷积网络(FCN)[44, 40, 68, 69, 10, 11, 12, 30, 15]极大地推进了语义图像分割。基于cnn的交互式分割的成功很大程度上得益于FCNs的发展。其中直接应用FCN[44]、DeepLab系列[10,11,12]和PSP[68]来解决交互式分割[67,38,45,46]。在这项工作中,我们研究了哪种类型的网络更适合进行交互式分割任务,并选择采用粗到细的网络结构[14]作为我们IOG方法的骨干。我们通过实验验证了我们的选择可以进一步提高交互式分割的准确性。
3 Method
3.1. Inside-Outside Guidance
我们的内外导向点击范式由三个点组成:大致位于对象中心的内部点击(内部点)和位于任何对称角落位置(左上和右下或右上和左下)的两次外部点击(外部点),它们形成了一个几乎紧密的包围感兴趣目标的边界框(图2)。通过这种方式,两个外部点击以及两个基于生成的边界框的额外推断点击提供了“外部”指导(指示背景区域),而内部点击提供了“内部”指导(指示前景区域) ,因此得名内外指导 (IOG)。
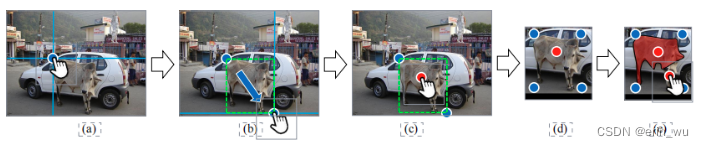
图 2。内部-外部指导。 (a) 垂直和水平引导线用于帮助用户单击包含对象的假想框的角。 (b) 当用户移动光标时,会即时生成一个框。 © 在对象中心周围放置一个内部点击。 (d) 在裁剪以包括上下文之前,框被扩展了几个像素。内部点击(红色)和四个外部点击(两个点击的角和两个自动推断的角)(蓝色)构成了我们的 Inside-Outside 指导,分别对前景和背景区域进行编码。 (e) 我们的方法自然支持额外的点击注释以进一步完善。
外部指导:外部指导由包围对象的边界框的角制定。然而,之前有报道称绘制一个紧凑的框可能很耗时([55] 报告在 ImageNet [53]2 上绘制一个框需要 25.5 秒)。这是由于难以单击假想框的角,这些角通常不在对象上 [49]。因此,通常需要进行多次调整以确保最终的边框是紧密的。然而,通过对注释界面进行一些简单的修改,例如使用水平和垂直引导线使框在单击角时可见,绘制边界框的负担可以大大减轻,如图 2(a)-(b)所示。此外,在我们的例子中,我们不一定需要一个完全紧密的边界框,一个几乎紧密的框通常就足够了。在我们的用户研究中,我们观察到在辅助线的帮助下绘制边界框通常需要大约 6.7 秒。
内部指导:内部指导被表述为位于对象中心周围的内部点击,用于消除分割目标的歧义,因为同一个框内可能有多个对象。为了模拟人工注释者注释的点击,我们建议在距离对象边界最远的位置对内部点进行采样。特别地,让 O 表示属于对象的像素,我们首先计算基于欧几里德距离变换的距离图 D,如下所示:
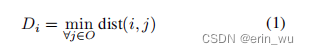
其中 Di 是指像素位置 i 处的 D 值,而dist(i, j) 表示像素位置 i 和 j 之间的欧氏距离。然后,在 k = arg max∀i∈O Di 位置对内部点击进行采样。通过与从真实用户收集的实际内部点击进行比较,这种采样方案的有效性在 4.5 节中得到验证。请注意,注释内部点非常快,在我们的用户研究中大约需要 1.5 秒。
点击表示:我们使用与 DEXTR [46] 相同的点击表示,通过以2D高斯圆周点击为中心,为前景和背景点击创建两个单独的热图。将生成的热图与 RGB 输入图像连接起来,形成网络的 5 通道输入。与 [46] 类似,边界框首先扩展几个像素以包含上下文,然后裁剪以聚焦感兴趣的对象(图 2(d))。
与现有的基于点击的 [67、46] 和基于框的 [66] 交互式分割方法相比,我们提出的 IOG 具有两全其美的优点:(i) 灵活性:由于注释的三个点被编码为前景和背景点击,我们的 IOG自然支持额外的点击注释以进行进一步修正(图 2(e)); (ii) 包含更多信息:我们的方法对有关对象的更多先验信息进行编码,包括背景的硬性位置和目标的粗略大小。
3.2. Segmentation Network
在这里,我们讨论了我们的分割网络的架构设计。我们使用基于ResNet-50[26]的DeepLabv3+[12]作为起点,我们已经观察到良好的分割性能(PASCAL上的IoU为90.0%),证明了我们提出的IOG的有效性。然而,仔细观察分割质量可以发现,如图3所示,分割错误主要发生在物体边界上。简单地用更深层次的网络(如ResNet-101)替换基准网络只能造成边界的改进(图6右侧的Vanilla IOG),这表明必须进行一些网络体系结构修改,以确保网络专注于沿着对象边界细化不准确的分割。

图3。在分割误差方面的定性比较。请注意,当使用DeepLabv3+[12]作为主干时,分割错误主要发生在对象边界上,而我们的粗到细结构产生精确的边界。
这里的图片是自己生成的图像减去原本的ground truth,得到的图生成的误差,所以白边比较小,说明的是效果比较好。
在这项工作中,我们建议采用一种coarse-fine的设计来解决上述问题(图4)。特别是,我们采用了一种类似于[14]的级联结构,这是最初为人类姿态估计任务提出的。具体来说,分割网络由两个子网络组成。第一个子网络CoarseNet应用了类似FPN的设计[40],通过横向连接逐步融合来自较深层的语义信息和来自较早期层的低级细节。与[14]不同的是,我们还在最深层附加了一个金字塔场景解析(PSP)模块[68],用于丰富全局上下文信息表示。给定来自第二个子网络CoarseNet的粗略预测,FineNet的目标是恢复缺失的边界细节。这是通过一个多尺度融合结构来实现的,该结构通过上采样和连接操作来融合CoarseNet中不同级别的信息。与[14]相似,我们也对更深层次的特征应用了更多的卷积块,以便更好地在精度和效率之间进行权衡。详情请读者参阅补充资料。请注意,我们并没有声称网络设计有任何新奇之处。相反,我们的贡献在于发现粗到细的结构对于获得更精确的分割掩码是必要的,而堆叠更多的层并不能满足我们对精度的需求。我们相信其他的从粗到细的结构也可以见效,我们把它作为未来的工作留下。
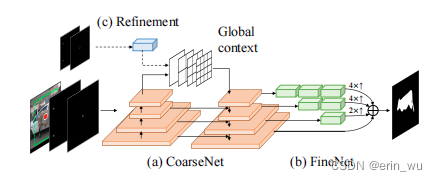
图4。网络体系结构。(a)-(b)我们的分割网络采用了类似于[14]的由粗到细的结构,增加了金字塔场景解析(PSP)模块[68],用于聚合全局上下文信息。©我们还在PSP模块之前添加了一个轻量级分支,以接受额外的点击输入,进行交互优化。
训练和测试:我们的分割网络使用二进制交叉熵损失进行端到端训练。此外,我们还在CoarseNet的每个级别应用side损失作为深度监督[14]的一种形式。在推理过程中,对最终的网络预测值进行简单的阈值分割得到分割掩码。由于我们的方法不涉及任何后处理,因此速度非常快,在Nvidia GeForce GTX 1080 GPU上,ResNet-101主干上的单个前向传递通常只需要20毫秒。因此,它非常适合实际的交互式图像分割应用。
3.3. Beyond Three Clicks…
虽然我们的IOG方法只需要三次点击来执行分割,但如果用户对当前的分割输出不满意,我们的框架自然支持交互式添加新的前景和背景点击来进一步细化。为了实现这一点,我们在PSP模块之前添加了一个轻量级分支,以接受编码所有前景和背景点击的双通道高斯热图(图4©)。我们从经验上发现,这种设置不仅比在分割网络的开始修改输入更好,而且运行得更快,因为编码器特征只需要计算一次。
在训练过程中,我们采用迭代训练策略来模拟交互过程,用户在错误区域引入额外的点击以进行纠正。更具体地说,初始分割掩码首先获得仅给予三次点击。然后在最大错误区域的中心添加一个新的click,并进行第二次向前传递。4.3节的结果表明,这种迭代训练策略是必要的。
4. Experiments
我们在11个公开可用的基准数据集上进行了广泛的实验,包括PASCAL [20], GrabCut [52], COCO [41], ImageNet [53], Open Images [53], cityscape [17], Rooftop [57], Agriculture-Vision [16], system[22], PASCAL-context[47]和COCO- stuff[6],以展示我们IOG的有效性和泛化能力。我们选择ResNet-50和ResNet-101作为IOG的两个主干,以便与以前的方法进行公平的比较。遵循常用的实践[46],我们使用PASCAL作为主要基准来验证IOG中提出的每个组件的重要性。
4.1. Implementation Details
模拟的内外点:我们使用ground truth masks来生成用于训练的内外点。对于外部的点,我们取从ground truth masks中提取的边界框的角,并扩展10个像素点来模拟真实用户提供的loosen box。对于内部点,我们采样距离对象边界最远的点击,并应用随机扰动。扰动的影响将在第4.5节中研究。
ground truth:在有监督学习中,ground truth 通常指代样本集中的标签。
ground truth(gt)指的是真实情况或真实值。模型评估或训练阶段(计算损失函数)时,模型输出得到的预测结果要与真实值也就是gt作比较。才能知道模型的好坏,性能高低。
训练和测试细节:IOG在PASCAL 2012 Segmentation 3上训练最多100个epoch或在MS COCO 2014上训练最多10个epoch。我们从表现最好的时期获得结果。对于PASCAL,batch size设置为5,而对于COCO,我们在2个GPU上训练,有效batch size为10。对于COCO,我们还在ground truth mask的边界周围构造了一组“void”像素,并在训练过程中忽略它们。学习率、动量和权重衰减分别设置为10−8、0.9和5 × 10−4。
4.2. Comparison with the State-of-the-Arts
首先,我们将IOG与两个流行基准上的最先进方法进行比较,即PASCAL VOC val set和GrabCut。表1总结了每种方法达到一定性能所需的点击次数,以及仅提供4次点击时对应的IoU分数。可以观察到,我们的IOG在PASCAL和GrabCut上的表现分别超过了其他所有IOG的1.7%和1.9%。当允许迭代细化时(即从3次点击到4次点击),性能可以进一步提高到94.4%和96.9%,这很好地证明了我们的IOG在处理额外的用户输入以进一步更正方面的有效性。

表1。与PASCAL和GrabCut上最先进的方法进行比较,就达到某个IoU的点击次数和4次点击的质量而言。*表示我们的IOG的IoU仅为3次点击。
接下来,我们比较了最先进的DEXTR和我们的IOG在未见类和不同数据集上的泛化能力。根据[46]中的设置,我们比较了两个基准的性能,即PASCAL和COCO mini-val (MV al)。对于看不见的类设置,我们利用在PASCAL上训练的模型,并在COCO MV所见(即与PASCAL具有相同类别的图像)和COCO MV所见(即与PASCAL具有不同类别的图像)上评估其IoU。对于泛化设置,我们在PASCAL(或COCO)上训练模型,并评估COCO MV al(或PASCAL)上的性能,而不考虑测试类别。如表2所示,我们的IOG在各种设置上都比DEXTR有所改进,尽管只使用了3次单击。一些定性结果如图5所示。
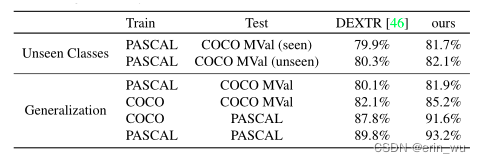
表2。最先进的DEXTR和我们的IOG在泛化能力方面的比较。

图5。定性结果PASCAL [20], PASCAL- context [47], COCO[41]和COCO- stuff[6]。每个实例与模拟的内外点和相应的分割掩码叠加在输入图像上。
4.3. Ablation Study
IOG每个组件的论证:我们在PASCAL VOC val集上进行消融实验,以验证我们的分割网络中每个组件的有效性。特别是,我们定量地证明了各种设计选择,包括不同的主干(ResNet50 vs. ResNet-101),不同数量的训练图像(PASCAL-1K vs. PASCAL-10K),包括用于全局上下文信息(Context)的PSP模块,FineNet和用于训练的侧损失。如表3所示,在ResNet-50和PASCAL-1K设置下,“Context”、“FineNet”和“Side losses”的性能提升分别为0.4%、0.8%和1.0%。当增加SBD (PASCAL-10k)的附加标签时,性能可以从91.6%进一步提高到92.8%。最终,我们用ResNet-101替换主干网时获得了最先进的性能(93.2%)。

表3。消融实验在PASCAL VOC 2012 val集上对分割网络中的每个组件进行论证。
交互细化的迭代训练:在前一节中,我们已经演示了在默认设置下,当只提供3次单击时,我们的IOG的有效性。接下来,我们检查用户对结果不满意并希望注释额外的单击以进一步更正的情况。具体来说,我们逐步在最大错误区域的中心添加一个新的点击,类似于[67,45]。图6(左)总结了结果。**我们可以观察到:1)如果没有迭代训练,额外的点击不会带来显著的性能提升,说明了迭代训练对于交互细化的重要性;2)将点击添加到分割网络的中间层(章节3.3)比在网络的开始修改输入更有效。一个有趣的观察是,在没有迭代训练的情况下,在模型的开始添加点击将导致性能下降。一个可能的原因是,内部点总是位于对象中心周围,而新添加的校正点击通常分布在对象边界附近,这使训练的模型感到困惑,并损害了性能。**交互式细化的一些定性示例可以在图7中找到。
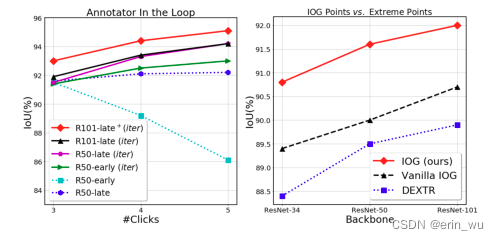
图6。(左)迭代训练对交互细化的效果。“early”和“late”分别表示将点击输入添加到网络的开始层或中间层。“iter”表示迭代训练(章节3.3),而“+”表示在更大的数据集(PASCAL-10k)上训练。(右)IOG点与极值点的比较。

图7。互动的细化。我们提出的IOG支持交互式添加新的点击以进一步优化。
IOG点与极端点:我们研究了我们提出的IOG点与DEXTR中使用的极值点的性能。为了公平的比较,我们使用发布的代码4,并使用DeepLabv3+[12]作为PASCAL-1K上的全卷积架构重新训练DEXTR。所有模型仅在ImageNet[53]上进行预训练。我们使用ResNet-34、ResNet-50和ResNet-101三种不同的主干进行实验,为了验证所提方法的鲁棒性。如图6(右)所示,在相同的网络架构下(Vanilla IOG vs. DEXTR),我们提出的IOG点始终优于极值点。当使用由粗到细的网络结构(章节3.2)时,我们可以看到我们的IOG显著优于基线。有趣的是,我们使用ResNet-34作为骨干的IOG已经超过了使用ResNet101的最先进的DEXTR,证明了所提出的IOG在极值 点上的有效性。
4.4. Cross-Domain Evaluation
在第4.2节中,我们已经演示了IOG在不可见类别和不同数据集上的泛化能力(在PASCAL上训练,在COCO上测试,反之亦然)。然而,PASCAL和COCO数据集中的图像都是一般场景,而强大的注释工具应该可以很好地泛化不同的图像类型。在下一节中,我们将检查模型在不同领域的泛化能力,包括非PASCAL样式的对象类别和材料类别。
对象类别:按照[42,1],我们评估了IOG在3种图像类型上的表现,包括街景(Cityscapes[17])、空中图像(Rooftop[57])和医学图像(ssTEM[22])。结果汇总于表4、表5、表6。我们可以看到,即使没有微调,我们的模型在Rooftop和ssTEM数据集上的性能也远远优于基线。更有趣的是,如表4所示,在对Cityscapes数据集进行评估时,我们经过pascal训练的模型已经与经过Cityscapes训练的方法表现相当。这表明我们的IOG即使在不同的领域也能很好地泛化。此外,通过只使用10%的新数据集进行微调,模型性能可以进一步提高,其中我们的模型显著优于所有其他基线。此外,我们还将IOG应用于更具挑战性的Agriculture-Vision数据集[16],并且在使用少量数据进行微调时仍然取得了令人满意的性能。图8提供了一些定性的例子。
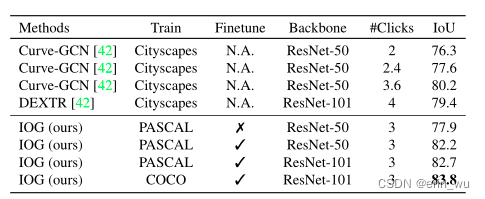
表4。城市景观的跨域分析。“Finetune”表示该方法在城市景观数据集的一小部分(10%)上进行了微调。

表5所示。屋顶[57]的跨域分析。即使没有微调,我们的方法也已经优于经过微调的Curve-GCN,这表明我们的方法具有很强的泛化性。

表6所示。系统[22]的跨域分析。请注意,system没有训练分割,因此我们不会对这个数据集进行微调。

图8。跨域的性能。我们的IOG在城市景观、农业视觉、屋顶和系统上的定性结果。
物品类别:在图5中,我们展示了在PASCAL-Context[47]和COCO-Stuff[6]上微调的IOG的一些定性结果,以验证我们的IOG在分割“物品”类别时的性能。结果表明,我们的IOG也能很好地推广到背景类。
4.5. More Discussions
在选择内部点时对用户差异的鲁棒性:在前面的实验中,我们检查了我们的IOG使用模拟的内外点作为输入的有效性。然而,在实际操作中,虽然用户通常在注释外部点时做出一致的选择,但是用户在选择内部点时时往往难以达成共识。训练和测试之间不一致的输入通常会对分割性能产生负面影响,特别是在应用于真实的注释场景时。
为了缓解用户差异对内部点选择的负面影响,我们在训练过程中随机扰动内点的位置。特别地,我们首先以ground truth masks提取的内点为中心,以预先定义的半径®确定一个圆形区域。然后,我们从该区域随机采样一次点击,作为训练的内点。为了验证所提议的修改的有效性,我们从5个不同的用户收集了PASCAL val集中所有实例的内点注释。如表7所示,我们首先注意到,在使用人类提供的输入测试无扰动模型时(从93.2到90.8),性能有了很大的下降。然而,当训练过程中施加更大的扰动时,性能差距逐渐缩小。该模型在r = 30时达到最佳权衡。
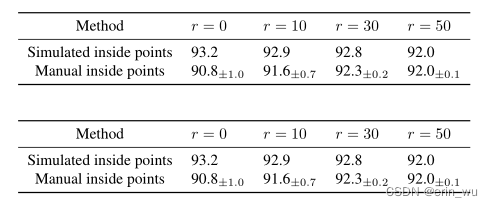
表7所示。手动和模拟的内部点。R为训练时施加扰动的半径。所有模型均以ResNet-101为骨干,在PASCAL-10k上进行训练。
仅扩展带有框注释的数据集:许多现有的现成数据集,如ImageNet和Open Images,都提供了边界框注释。在这里,我们将探索如何在只有边界框注释可用的情况下,使用我们的IOG快速获取高质量的实例分割掩码。具体来说,我们将带注释的边界框视为IOG的不完整注释,其中没有内部点。为此,我们提出了一个简单的两阶段解决方案,使用一个小网络来预测一个基于边界框的粗掩码,其中掩码用于推断IOG的内部候选点。我们将其与以下基线进行比较,结果汇总在表8中。

表8所示。扩展到只有框注释的数据集。所有的结果都是在PASCAL val上使用方框注释报告的。
(A)裁剪:我们训练一个网络,将裁剪后的RGB图像作为输入并预测分割。
(B) Geo:我们训练一个网络,以边框的几何中心为内点进行分割。
© Sim:我们用模拟点击(章节3.1)来训练我们的IOG,但在测试期间使用给定边框的几何中心作为内点。
(D)仅限外部:我们训练一个单一的网络,只使用外部点进行分割。
(E) 2阶段:我们从(D)生成的分割掩码中提取内点,并传递给我们的IOG进行最终预测。
我们首先观察到,由于训练测试不一致,设置©表现不佳。另一方面,方法(B)和(D)具有相似的性能。这是因为边框的几何中心在裁剪后总是位于相同的位置,因此网络学会忽略这个输入。通过采用更强的主干网络和更多的训练图像,可以进一步提高(D)的性能。最后,将(D)预测的分割掩码中的内点作为我们的IOG的输入,得到了最好的结果。在ImageNet和Open Images上的一些定性结果如图9所示。使用ILSVRCLOC的带注释的边界框(~ 0.615M),我们应用IOG来收集它们的像素级注释,命名为Pixel-ImageNet,这些注释可在https://github.com/shiyinzhang/ Pixel-ImageNet上公开获得。
![]](https://img-blog.csdnimg.cn/3bc158f3a6254620aa50f1cb3d70ce82.png)
图9。使用我们提出的2阶段方法对ImageNet(上)和Open Image(下)的定性结果。注意,这里只提供了边界框注释。
5. Conclusion
我们提出了一个简单而有效的内外指导(IOG)方法,以最大限度地降低标签成本。提议的IOG只需要用户提供三个点,即:靠近对象中心的一个内点和两个外点,它们构成一个包围目标对象的框。此外,我们的方法自然支持额外点的交互式注释,以便进一步更正。尽管它很简单,但大量的实验表明,我们的模型可以很好地泛化不同的数据集和领域,证明了它作为注释工具的优越性。
Reference
[12] Liang-ChiehChen,YukunZhu,GeorgePapandreou,Florian Schroff, and Hartwig Adam. Encoder-decoder with atrous separable convolution for semantic image segmentation. In ECCV, 2018.
[14] Yilun Chen, Zhicheng Wang, Yuxiang Peng, Zhiqiang Zhang, Gang Yu, and Jian Sun. Cascaded pyramid network for multi-person pose estimation. In CVPR, 2018.
[16] Mang Tik Chiu, Xingqian Xu, Yunchao Wei, Zilong Huang, Alexander Schwing, Robert Brunner, Hrant Khachatrian, Hovnatan Karapetyan, Ivan Dozier, Greg Rose, et al. Agriculture-vision: A large aerial image database for agri- cultural pattern analysis. In CVPR, 2020.
[26] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016.
[40] Tsung-Yi Lin, Piotr Doll ́ar, Ross Girshick, Kaiming He, Bharath Hariharan, and Serge Belongie. Feature pyramid networks for object detection. In CVPR, 2017.
[46] Kevis-Kokitsi Maninis, Sergi Caelles, Jordi Pont-Tuset, and Luc Van Gool. Deep extreme cut: From extreme points to object segmentation. In CVPR, 2018.
[68] Hengshuang Zhao, Jianping Shi, Xiaojuan Qi, Xiaogang Wang, and Jiaya Jia. Pyramid scene parsing network. InCVPR, 2017.















 861
861











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









