







往期回顾:
08——卷积网络
09——循环神经网络
10——GAN的基本概念
上一节我们学习了 GAN 的基本概念,这一节我们将过去几年的 GAN 经典算法思想都介绍一下。
一、GAN的数学解释
上一节我们学习了 GAN 的基本算法,现在让我们看看 GAN 背后的数学思想。
- 生成器
生成器实际上产生了一个生成数据分布 P G ( x ) P_G(x) PG(x)。它的目标就是使得 P G ( x ) P_G(x) PG(x)与 P d a t a ( x ) P_{data}(x) Pdata(x)之间的差距尽可能小。

- 判别器
判别器可以产生一个分值,用来描述生成分布与真实分布之间的差异,此时这个分值由目标函数定义,例如最原始的 GAN 使用二类交叉熵损失来描述。我们的目标就是最大化这一差异。
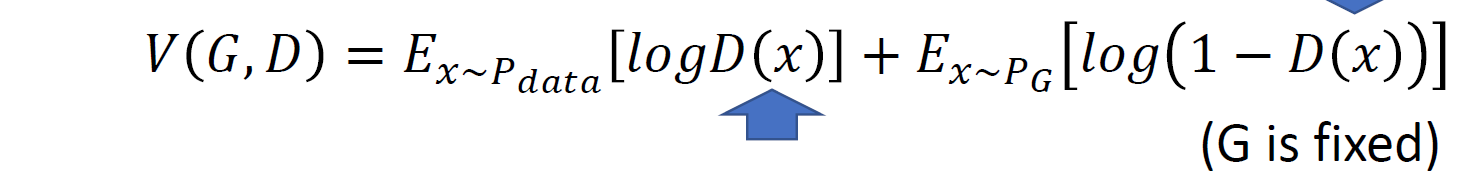
事实上,这里的目标函数相当于衡量两个分布之间的JS散度。我们之前提到过有KL散度,也说了KL散度的不对称性,而JS散度就是两个相对的KL散度的平均。
数学证明如下:
首先我们解出判别器在生成器固定时的最大值。


之后代入 max D V ( G , D ) \max_DV(G,D) maxDV(G,D),可以看到:

得证。
由于我们最终目的是要使得生成分布与真实分布尽可能小,因此我们最终的优化问题为 G ∗ = arg min G max D V ( G , D ) G^*=\argmin_G\max_DV(G,D) G∗=GargminDmaxV(G,D)
这里判别器与目标函数充当了描述差异的函数,因此我们不能在每次循环时过多的更新生成器,而可以多更新几次判别器。 这是因为如果更新生成器过多,它的生成分布就与更新前的生成分布差异很大,这使得判别器产生的数值并不能很好描述差异性。对于 GAN 的一个重要假设就是生成器的每次小更新产生的新分布与之前的分布差异不太多,从而使得描述的差异仍有效。
二、 fGAN
上节阐述了原始的 GAN 衡量的是 JS 散度,那么有没有其他的衡量差异的选择呢?另外为什么判别器可以表示某一散度的度量呢?本节将回答这一问题。
在概率统计中,f散度是一个函数,这个函数用来衡量两个概率密度p和q的区别。
p和q是同一个空间中的两个概率密度函数,它们之间的f散度可以用如下方程表示:

其中 f f f为凸函数且 f ( 1 ) = 0 f(1) = 0 f(1)=0 因此当两个分布相同时,它们的 f 散度就是 0 。并且由于凸函数的性质,f 散度保证它的最小值就是0。
我们不难发现一些常见的散度都可以被表示:
这里给出了一些常见的散度与其相应的 f 函数:

那么生成器与损失函数为什么能够表示某一散度呢?
这里我们引入共轭的概念,每个凸函数 f f f都有一个共轭函数 f ∗ f^* f∗。定义为:

同样,共轭函数的共轭就是原函数,即
f ( x ) = max t ∈ d o m ( f ∗ ) { x t − f ∗ ( t ) } f(x)=\max_{t\in dom(f^*)}\{xt-f^*(t)\} f(x)=maxt∈dom(f
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









