






语音识别的概念:
语音识别是将语音自动转换为文字的过程。语音识别可以作为一种广义的自然语言处理技术, 是人与人、人与机器进行交互的技术。语音识别涉及的领域包括数字信号处理、声学、语言学、 计算机科学、数学、心理学、人工智能等,是涉及多个学科领域的科学技术。
工作原理:
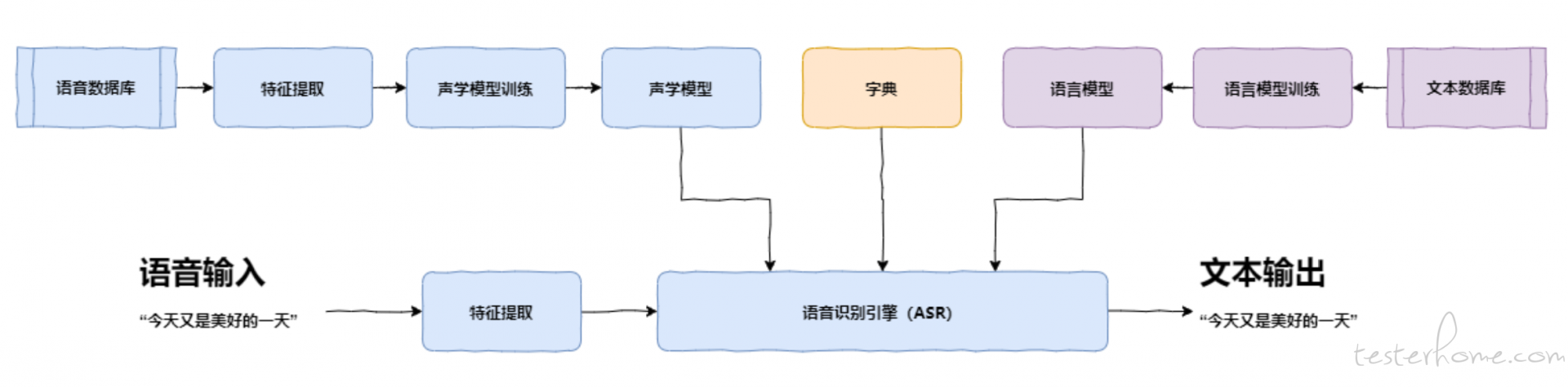
语音识别过程一般包含特征提取、声学模型、语言模型、语音解码和搜索算法四大部分
-
其中特征提取是把要分析的信号从原始信号中提取出来,为声学模型提供合适的特征向量。 为了更有效地提取特征,还需要对语音进行预处理,包括对语音的幅度进行标准化、频响校正、 分帧、加窗和始末端点检测等内容。
-
声学模型是可以识别单个音素的模型,是对声学、语音学、环境的变量、说话人性别、口音等要素的差异的知识表示。利用声学模型进行语音声学参数分析,包括对语音共振峰频率、幅度等参数,以及对语音的线性预测参数等的分析。
-
语言模型则根据语言学的相关理论,结合发音词典,计算该声音信号对应可能词组序列的概率。
-
语音解码和搜索算法的主要任务是在由声学模型、发音词典和语言模型构成的搜索空间中寻找最佳路径。解码时需要用到声学得分及语言得分,其中声学得分由声学模型计算得到,语言得分由语言模型计算得到。 声学模型和语言模型主要利用大量语料进行统计分析,进而建模得到。发音字典包含系统所能处理的单词的集合,并标明了其发音。通过发音字典得到声学模型的建模单元和语言模型建模单元间的映射关系,从而把声学模型和语言模型连接起来,组成一个搜索的状态空间,使解码器能够进行解码工作。
-
与语音识别相近的概念是声纹识别。声纹识别是生物识别技术的一种,也称为说话人识别, 包括说话人辨认和说话人确认。声纹识别就是把声信号转换成电信号,再用计算机进行识别。不同的任务和应用会使用不同的声纹识别技术,如缩小刑侦范围时可能需要说话人辨认技术,银行交易时则需要说话人确认技术。辨认技术用以判断某段语音是若干人中的哪一个所说的,是“多选一”问题;而确认技术用以确认某段语音是否是指定的某个人所说的,是“一对一判别”问题
语音识别系统的实现:
1. 预处理:对输入的原始语音信号进行处理,滤除其中不重要的信息及背景噪声,并进行语音信号的端点检测(找出语音信号的始末)、语音分帧(近似认为在10~30毫秒内的语音信亏是短时平稳的, 将语音信号分割为一段一段的进行分析)及预加重(提升高频部分)等处理。
2. 特征提取:提取特征的方法很多,大多是由频谱衍生出来的。梅尔频率倒谱系数(MFCC)参数因其良好的抗噪性和健壮性而被广泛应用。MFCC 的计算首先用FFT将时域信号转化为频域,之后对其对数能量谱用依照梅尔刻度分布的三角滤波器组进行卷积,最后对各个滤波器的输出构成的向量进行离散余弦变换DCT,取前N个系数。在检索引擎Sphinx中,用帧去分割语音波形, 每帧大概10毫秒,然后每帧提取可以代表该帧语音的39个数字,这39个数字也是该帧语音的MFCC特征,用特征向量来表示。
3. 声学模型训练:根据训练语音库的特征参数训练出声学模型参数。在识别时可以将待识别的语音的特征参数与声学模型进行匹配,得到结果。 目前的主流语音识别系统多采用HMM进行声学模型的建模,声学模型的建模单元可以是音素、音节、词等各个层次。对于小词汇量的语音识别系统,可以直接采用音节进行建模;而对于词汇量偏大的识别系统,-般选取音素,即声母、韵母进行建模。识别规模越大,识别单元选取得越小。
4.语言模型训练:语言模型主要用于预测哪个词序列的可能性更大,或者在已经出现几个词的情况下预测下-个即将出现的词。换一个说法,语言模型是用来约束单词搜索的,它定义了哪些词能跟在上-个已经被识别的词的后面,这样在进行识别时就可以排除一些不可能的单词。
5.语音解码器:解码器即语音识别技术中的识别过程。针对输入的语音信号,根据已经训练好的HMM声学模型、语言模型及字典建立-个识别网络,根据搜索算法在该网络中寻找最佳路径,这个路径就是能够以最大概率输出该语音信号的词串,所以解码操作即搜索算法,是指在解码段通过搜索技术寻找最优词串的方法
语音识别的应用:
语音合成:
语音合成,又称文语转换,能将任意文字信息实时转化为标准流畅的语音并朗读出来,相当于给机器装上了嘴巴。语音合成涉及声学、语言学、数字信号处理、计算机科学等多个学科,是中文信息处理领域的一项前沿技术,解决的主要问题就是如何将文字信息转化为可听的声音信息, 即让机器像人一样开口说话。这里所说的“让机器像人一样开口说话”与传统的声音回放设备或系统有着本质的区别。传统的声音回放设备或系统,如磁带录音机,是通过预先录制声音然后回放来实现“让机器说话”的。这种方式在内容录制、存储、传输的方便性和及时性等方面存在很大的限制,而通过计算机语音合成,可以在任何时候将任意文本转换成具有高自然度的语音,从而真正实现“让机器像人一样开口说话”。
语音合成的应用:
案例实训:
(1)环境准备:安装Spyder等Python编程环境。
(2) SDK准备:安装百度AI开放平台的SDK。
(3)账号准备:注册百度AI开放平台的账号。
(4)保证网络通信正常。
步骤:
一、 登录百度AI开放平台-全球领先的人工智能服务平台 (baidu.com) https://ai.baidu.com/

在这里插入图片描述
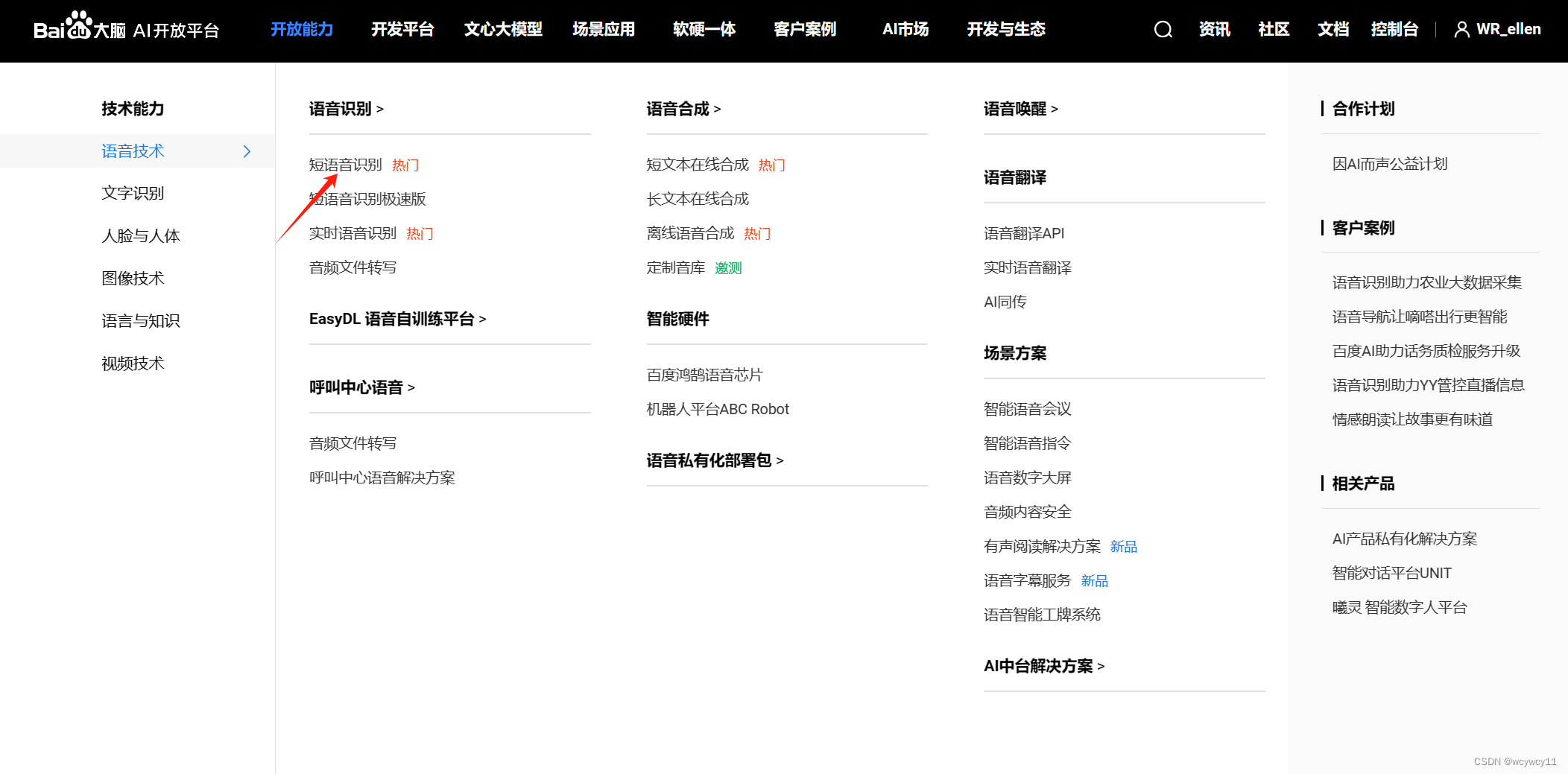


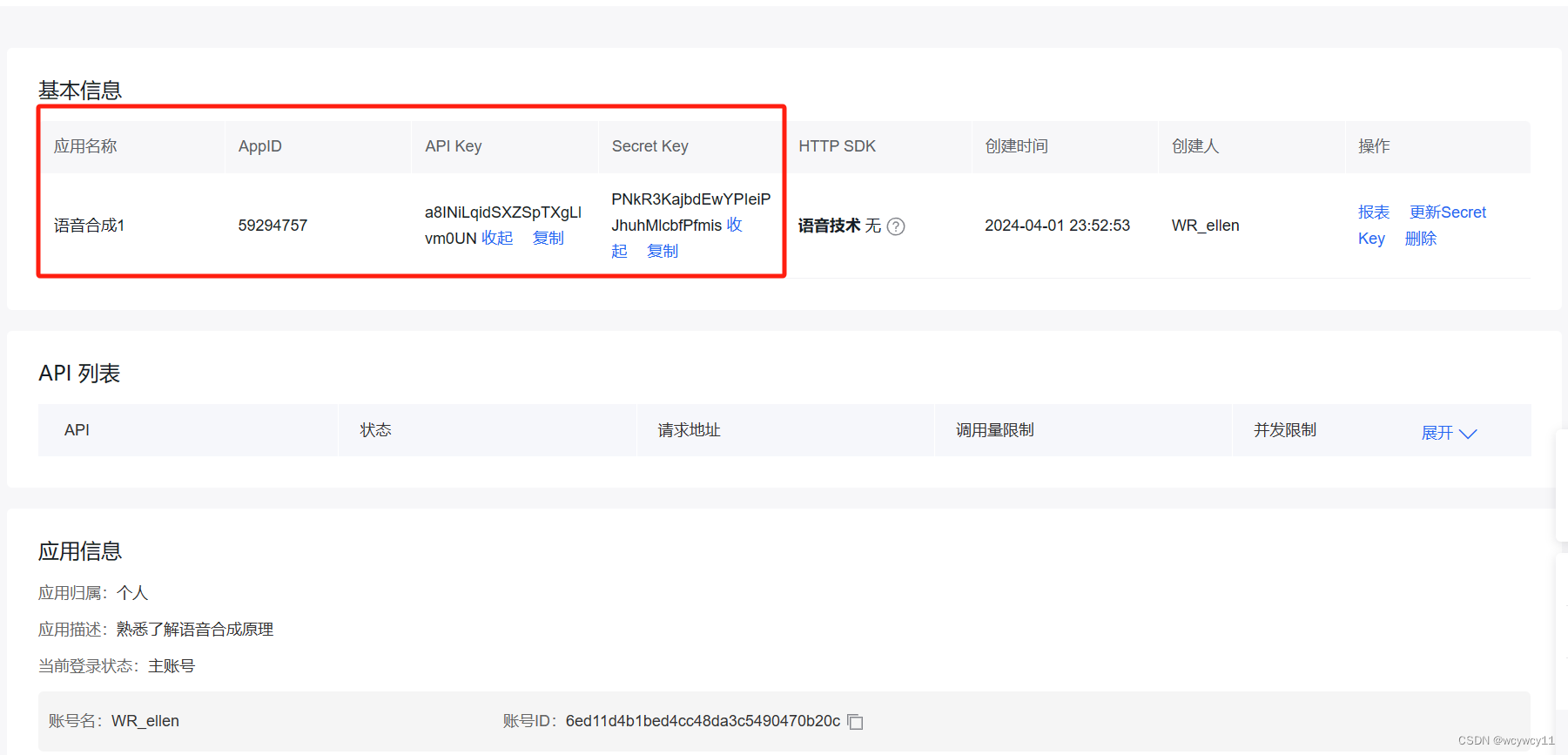
记录以上信息,APPID,APIKEY,SECRET KEY在代码中修改为自己的KEY
代码:
从AIP中导入相应的语音模块AipSpeech
from aip import AipSpeech
如果没有导入aip,导包你可以命令提示符中
`pip install baidu_aip`
下载即可
复制粘贴APPID、AK、SK这3个值并以此初始化对象
#你的APPID AK SK
APP_ID='59362217'
API_KEY='xeUuWoq3oYvJ4o4Wo8tyAtiw'
SECRET_KEY='FrxRUcd2i43vnc5Jq9kQhdkATgk4RdfE'
client=AipSpeech (APP_ID, API_KEY, SECRET_KEY)
准备文本及存放路径
Text='欢迎来到CSDN' # 文字部分也可以从磁盘读取,或者是从图片中识别
filePath= "MyVoice.mp3 " #音频文件存放路径
语音合成
result=client.synthesis (Text,'zh',1, {'vol': 5})
print(result)
#可以做一些个性化设置,如选择音量、发音人、语速等
识别并正确返回语音二进制代码,错误则返回dict(相应的错误码)
if not isinstance (result, dict):
with open (filePath,'wb')as f: # 以写的方式打开MyVoice.mp3文件
f.write(result) # 将result内容写入MyVoice.mp3文件
else:
print("错误")
整体代码:
from aip import AipSpeech
#你的APPID AK SK
APP_ID='59362217'
API_KEY='xeUuWoq3oYvJ4o4Wo8tyAtiw'
SECRET_KEY='FrxRUcd2i43vnc5Jq9kQhdkATgk4RdfE'
client=AipSpeech (APP_ID, API_KEY, SECRET_KEY)
Text='欢迎来到CSDN' # 文字部分也可以从磁盘读取,或者是从图片中识别
filePath= "MyVoice.mp3 " #音频文件存放路径
result=client.synthesis (Text,'zh',1, {'vol': 5})
print(result)
if not isinstance (result, dict):
with open (filePath,'wb')as f: # 以写的方式打开MyVoice.mp3文件
f.write(result) # 将result内容写入MyVoice.mp3文件
else:
print("错误")

















 994
994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









