







编码和解码的基本介绍
编写网络应用程序时,因为数据在网络中传输的都是二进制字节码数据,在发送数据时就需要编码,接收数据时就需要解码。

codec(编解码器) 的组成部分有两个:
- decoder(解码器)和 encoder(编码器)。
- encoder 负责把业务数据转换成字节码数据
- decoder 负责把字节码数据转换成业务数据
Netty 自身提供了一些 codec(编解码器)
Netty 提供的编码器
-
StringEncoder,对字符串数据进行编码
-
ObjectEncoder,对 Java 对象进行编码
......
Netty 提供的解码器
-
StringDecoder, 对字符串数据进行解码
-
ObjectDecoder,对 Java 对象进行解码
......
但是Netty 本身自带的 ObjectDecoder 和 ObjectEncoder 可以用来实现 POJO 对象或各种业务对象的编码和解码,底层使用的仍是 Java 序列化技术 , 而Java 序列化技术本身效率就不高,存在如下问题
- 无法跨语言
- 序列化后的体积太大,是二进制编码的 5 倍多。
- 序列化性能太低
引出 新的解决方案 [Google 的 Protobuf]
Protobuf
Protobuf 是 Google 发布的开源项目,全称 Google Protocol Buffers,是一种轻便高效的结构化数据存储格式,可以用于结构化数据串行化,或者说序列化。它很适合做数据存储或 RPC[远程过程调用remote procedure call ] 数据交换格式
目前很多公司http+json--->tcp+protobuf
语言指南developers.google.com/protocol-bu…


Protobuf 是以message的方式来管理数据的.
支持跨平台、跨语言,即[客户端和服务器端可以是不同的语言编写的] (支持目前绝大多数语言,例如 C++、C#、Java、python 等),高性能,高可靠性。
使用 protobuf 编译器能自动生成代码,Protobuf 是将类的定义使用.proto 文件进行描述。说明,在idea 中编写 .proto 文件时,会自动提示是否下载 .ptotot 编写插件. 可以让语法高亮。(考察)
然后通过protoc.exe编译器根据.proto 自动生成.java 文件

单对象案例
客户端可以发送一个Student PoJo 对象到服务器 (通过 Protobuf 编码)
服务端能接收Student PoJo 对象,并显示信息(通过 Protobuf 解码
环境搭建
首先Idea下载插件Protocol Buffer Editor

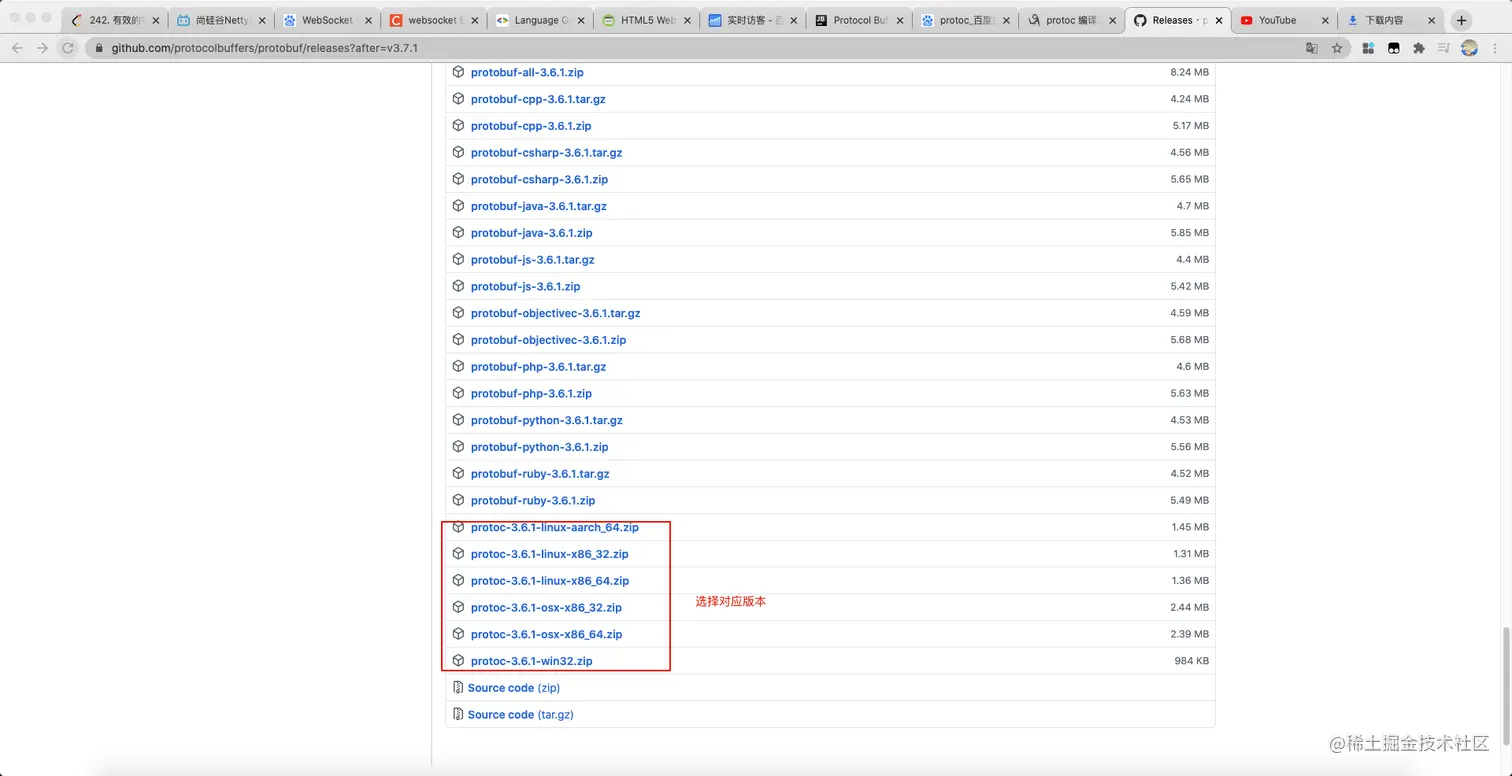
下载protochttps://github.com/protocolbuffers/protobuf/releases?after=v3.7.1解压

导入依赖
xml
复制代码
<dependency> <groupId>com.google.protobuf</groupId> <artifactId>protobuf-java</artifactId> <version>3.6.1</version> </dependency>
代码编写
发送对象
Student.proto

protobuf
复制代码
syntax = &#
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3422
3422











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









