







Python 网络爬虫与数据采集
- 第1章 序章 网络爬虫基础
第1章 序章 网络爬虫基础
1 爬虫基本概述
1.1 爬虫是什么
网络爬虫(Crawler)又称网络蜘蛛,或者网络机器人(Robots). 它是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。换句话来说,它可以根据网页的链接地址自动获取网页内容。如果把互联网比做一个大蜘蛛网,它里面有许许多多的网页,网络蜘蛛可以获取所有网页的内容。
爬虫是一个模拟人类请求网站行为, 并批量下载网站资源的一种程序或自动化脚本。
1.2 爬虫可以做什么
- 搜索引擎
- 采集金融数据
- 采集商品数据
- 采集竞争对手的客户数据
- 采集行业相关数据,进行数据分析
- 刷流量
1.3 爬虫的分类
- 通用网络爬虫
又称为全网爬虫,其爬取对象由一批 URL 扩充至整个 Web,主要由搜索引擎或大型 Web 服务商使用。 - 聚焦网络爬虫
又称为主题网络爬虫,其特点是只选择性的地爬取与预设的主题相关的页面,相比通用网络爬虫,聚焦网络爬虫仅需要爬取与主题相关的页面,极大地节省硬件及网络资源,能更快的更新保存页面,更好的满足特定人群对特定领域的需求。 - 增量网络爬虫
只对已下载的网页采取增量式更新,或只爬取新产生的及已经发生变化的网页,这种机制能够在某种程度上保证所爬取的网页尽可能的新。 - 深度网络爬虫
Web 页面按照存在的方式可以分为表层页面和深层页面两类。表层页面是只传统搜索引擎可以索引到的页面,以超链接可以达到的静态页面为主。深层页面是指大部分内容无法通过静态链接获取,隐藏在搜索表单之后的,需要用户提交关键词后才能获得的 Web 页面,如一些登陆后可见的网页。
1.4 爬虫的基本流程
1.4.1 浏览网页的流程
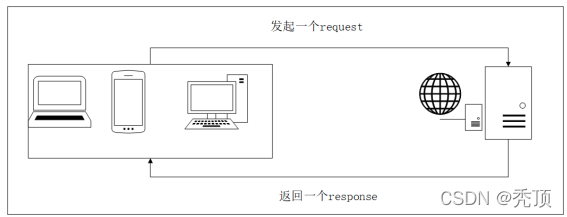
图 1.1: 浏览网页的流程
1.4.2 爬虫的基本流程
-
请求网页
通过 HTTP 库向目标站点发起请求,即发送一个 Request,请求可以包含额外的 headers 等
信息,等待服务器响应! -
获得相应内容
如果服务器能正常响应,会得到一个 Response,Response 的内容便是所要获取的页面内容,
类型可能有 HTML,Json 字符串,二进制数据(如图片视频)等类型。 -
解析内容
得到的内容可能是 HTML,可以用正则表达式、网页解析库进行解析。可能是 Json,可以
直接转为 Json 对象解析,可能是二进制数据,可以做保存或者进一步的处理。 -
存储解析的数据
保存形式多样,可以存为文本,也可以保存至数据库,或者保存特定格式的文件
测试案例
代码 0-0: 爬取搜狗首页的页面数据#导 包
import requests
#step_1 : 指 定 url
url = ’https 😕/ www . sogou . com /’
#step_2 : 发 起 请 求 :
#使 用 get 方 法 发 起 get 请 求 , 该 方 法 会 返 回 一 个 响 应 对 象 。 参 数 url 表 示 请 求 对 应 的 url
response = requests . get ( url = url )
#step_3 : 获 取 响 应 数 据 :
#通 过 调 用 响 应 对 象 的 text 属 性 , 返 回 响 应 对 象 中 存 储 的 字 符 串 形 式 的 响 应 数 据 ( 页 面 源 码
数 据 )
page_text = response . text
#step_4 : 持 久 化 存 储
with open (’sogou . html ’,’w’, encoding =’utf -8’) as fp:
fp . write ( page_text )
print (’ 爬 取 数 据 完 毕 ! ! ! ’)
1.5 爬虫与反爬虫
- 爬虫:使用任何技术手段,批量获取网站信息的一种方式。关键在于批量。
- 反爬虫:使用任何技术手段,阻止别人批量获取自己网站信息的一种方式。关键也在于批量。
- 误伤:在反爬虫的过程中,错误的将普通用户识别为爬虫。误伤率高的反爬虫策略,效果再好也不能用。
- 拦截:成功地阻止爬虫访问。这里会有拦截率的概念。通常来说,拦截率越高的反爬虫策略,误伤的可能性就越高。因此需要做个权衡。
- 资源:机器成本与人力成本的总和。
1.5.1 爬虫的攻与防
- 攻:
Day 1 小莫想要某站上所有的电影,写了标准的爬虫 (基于 HttpClient 库),不断地遍历某站的电影列表页面,根据 Html 分析电影名字存进自己的数据库。 - 守:
Day 1 这个站点的运维小黎发现某个时间段请求量陡增,分析日志发现都是IP(xxx.xxx.xxx.xxx) 这个用户,并且 user-agent 还是 Python-urllib/3.6 ,基于这两点判断非人类后直接在服务器上封杀。 - 攻:
Day 2 小莫电影只爬了一半,于是也针对性的变换了下策略:1. user-agent 模仿百度(“Baiduspider…”),2IP 每爬半个小时就换一个 IP 代理。 - 守:
Day 2 小黎也发现了对应的变化,于是在服务器上设置了一个频率限制,每分钟超过 120次请求的再屏蔽 IP。同时考虑到百度家的爬虫有可能会被误伤,想想市场部门每月几十万的投放,于是写了个脚本,通过 hostname 检查下这个 ip 是不是真的百度家的,对这些 ip 设置一个白名单。 - 攻:
Day 3 小莫发现了新的限制后,想着我也不急着要这些数据,留给服务器慢慢爬吧,于是修改了代码,随机 1-3 秒爬一次,爬 10 次休息 10 秒,每天只在 8-12,18-20 点爬,隔几天还休息一下。 - 守:
Day 3 小黎看着新的日志头都大了,再设定规则不小心会误伤真实用户,于是准备换了一个思路,当 3 个小时的总请求超过 50 次的时候弹出一个验证码弹框,没有准确正确输入的话就把 IP 记录进黑名单。 - 攻:
Day 4 小莫看到验证码有些傻脸了,不过也不是没有办法,先去学习了图像识别(关键词PIL,tesseract),再对验证码进行了二值化,分词,模式训练之后,总之最后识别了小黎的验证码(关于验证码,验证码的识别,验证码的反识别也是一个恢弘壮丽的斗争史…),之后爬虫又跑了起来。 - 守:
Day 4 小黎是个不折不挠的好同学,看到验证码被攻破后,和开发同学商量了变化下开发模式,数据并不再直接渲染,而是由前端同学异步获取,并且通过 JavaScript 的加密库生成动态的 token,同时加密库再进行混淆(比较重要的步骤的确有网站这样做,参见淘宝和微博的登陆流程)。 - 攻:
Day 5 混淆过的加密库就没有办法了么?当然不是,可以慢慢调试,找到加密原理,不过小莫不准备用这么耗时耗力的方法,他放弃了基于 HttpClient 的爬虫,选择了内置浏览器引擎的爬虫 (关键词:PhantomJS,Selenium),在浏览器引擎运行页面,直接获取了正确的结果,又一次拿到了对方的数据。 - 守:
Day 5 小黎:…
1.5.2 常见的反爬与反反爬
守: 通过 User-Agent 来控制访问:
从用户请求的 Headers 反爬虫是最常见的反爬虫策略。由于正常用户访问网站时是通过浏览器访问的,所以目标网站通常会在收到请求时校验 Headers 中的 User-Agent 字段,如果不是携带正常的 User-Agent 信息的请求便无法通过请求。
笔记 User Agent 中文名为用户代理,简称 UA,它是一个特殊字符串头,使得服务器能够识 别客户使用的操作系统及版本、CPU
类型、浏览器及版本、浏览器渲染引擎、浏览器语言、 浏览器插件等。
破:应对措施:如果遇到了这类反爬虫机制,可以直接在自己写的爬虫中添加 Headers,将浏览器的 User-Agent 复制到爬虫的 Headers 中
守: 基于行为检测 (限制 IP)
还有一些网站会通过用户的行为来检测网站的访问者是否是爬虫,例如同一 IP 短时间内多次访问同一页面,或者同一账户短时间内多次进行相同操作。大多数网站都是前一种情况,对于这种情况有两种策略:
破:应对措施:
- 可以专门写一个在网上抓取可用代理 ip 的脚本,然后将抓取到的代理 ip 维护到代理池中供爬虫使用,当然,实际上抓取的 ip 不论是免费的还是付费的,通常的使用效果都极为一般,如果需要抓取高价值数据的话也可以考虑购买宽带 adsl 拨号的 VPS,如果 ip 被目标网站被封掉,重新拨号即可。
- 降低请求频率。例如每个一个时间段请
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3047
3047











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









