






基于课上的yolov4代码,使用自己标注的数据集进行训练,得到训练好的模型,使用测试图片对结果进行检测展示。
1.收集数据,并标注
网上查找行人的图片,然后利用labelimg对收集的图片进行标注
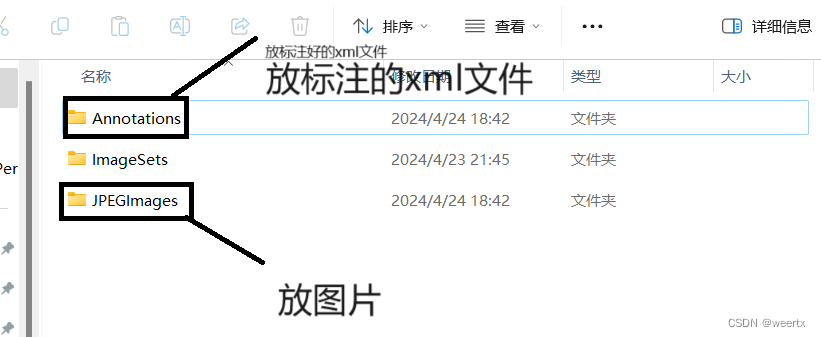
 2.将图片和标注后产生的xml文件放进文件夹中。
2.将图片和标注后产生的xml文件放进文件夹中。
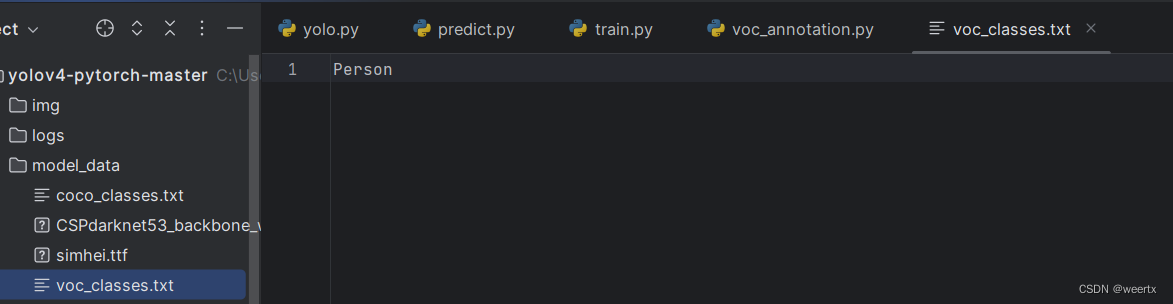
3.新建一个名为voc_classes的文本文档,将标签放进去,我们这里标注的只有人,所以只有Person这一个标签 。
4.运行voc_annotation.py文件
这里需要注意的是classes_path的路径,这里要放上上面我们创建的voc_classes.txt文件的路径。
并且数据集存放的文件夹与图片名称中不可以存在空格,否则会影响正常的模型训练
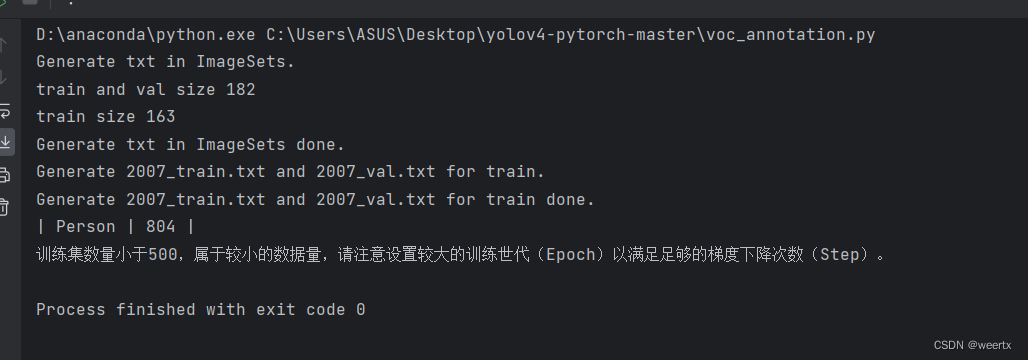
运出来后的结果
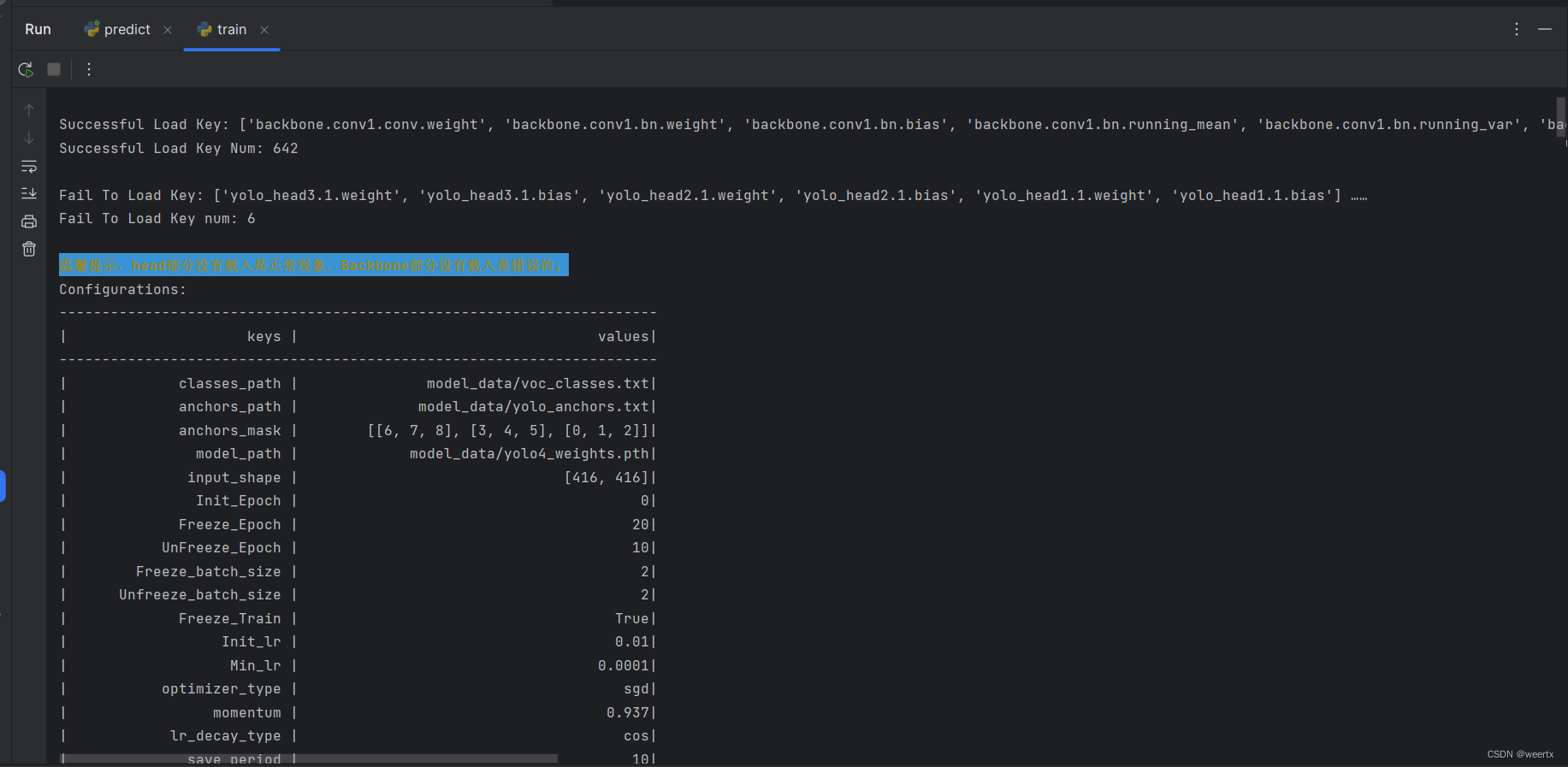
 5.然后就运行train.py文件
5.然后就运行train.py文件

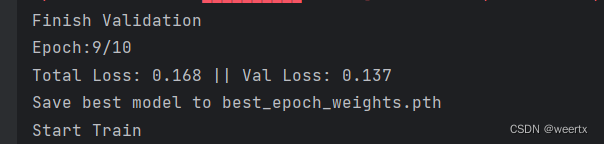
训练完之后会保存训练最好的模型
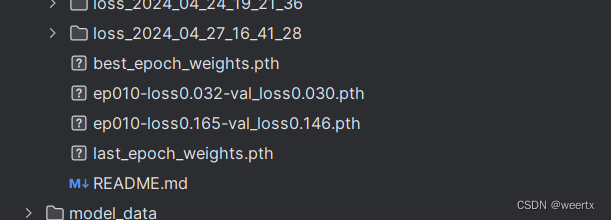
6.训练完完成后可以开始检测。因为我们的数据集只有两百张图片,所以检测精度很低,可以在yolo.py文件中改变模型地址,精度会高一点
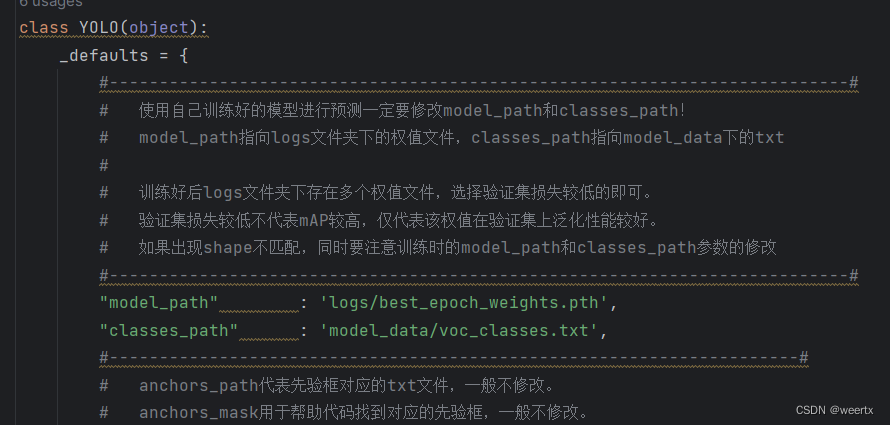
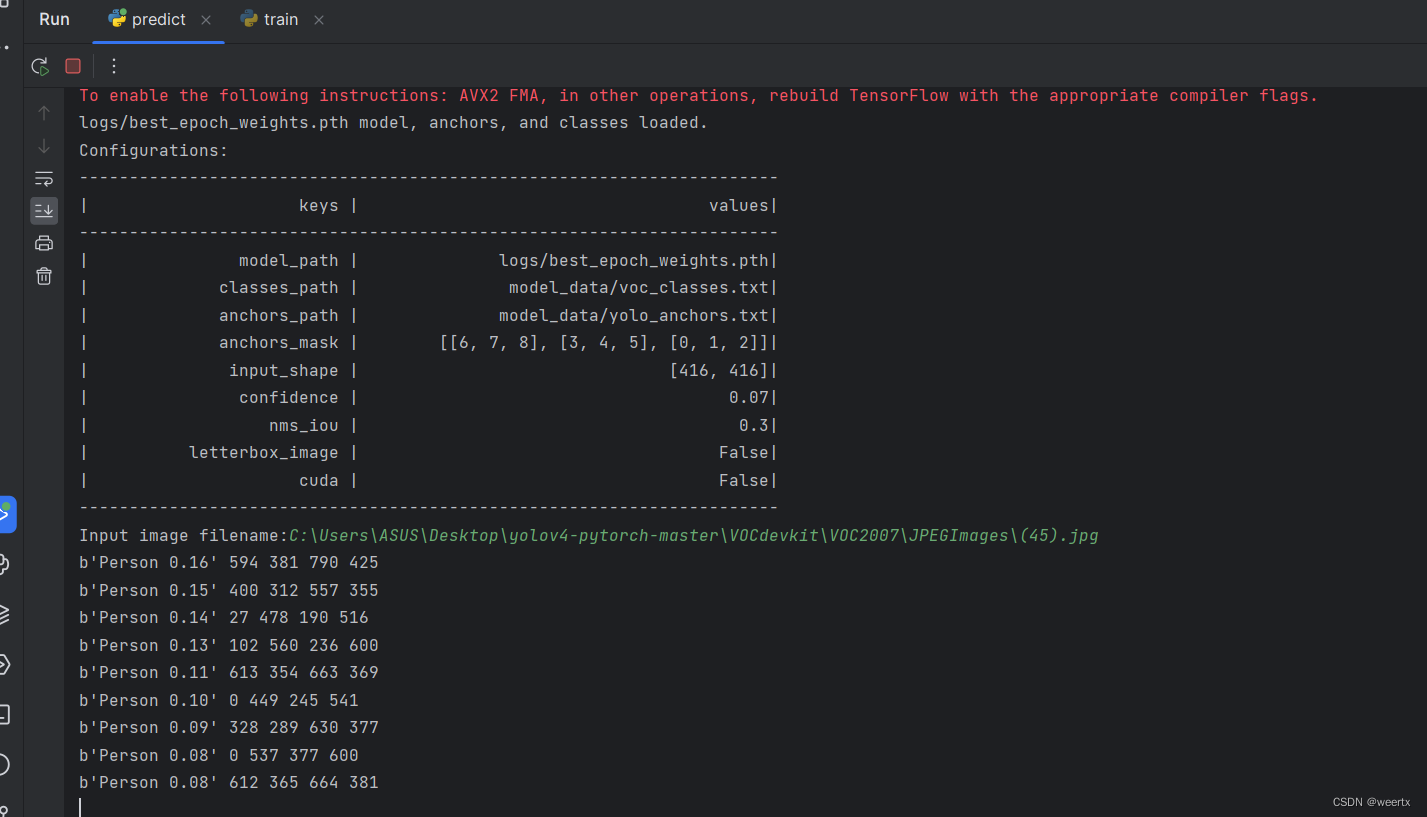
运行predict文件后,将你想要检测的图片路径写进去:
















 3705
3705











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









