







0.摘要
图像检索是在图像库中获取和待检索图像相似图像的一项基础任务。常规的图像检索方式,首先使用图像的全局特征进行相似性检索,然后通过局部特征对候选图像进行排序。之前基于学习的工作主要聚焦于全局或者局部的图像表征学习来解决图像检索问题。在本文中,我们放弃了两阶段的范式,通过在图像内部整合全局和局部信息,形成紧凑型的图像表征方式。具体细节是,我们提出了DOLG信息整合框架,进行端到端图像检索。它首先通过空洞卷积和自注意力机制提取局部信息;然后从局部信息中提取出与全局图像表征正交的分量;正交分量和全局特征作为互补特征串联起来,整合后产生最终的特征表征。整个框架是可微的并可以使用图像级别的标签训练。实验结果验证了我们的方法的有效性并在Revisited Oxford and Paris datasets数据集上表现SOTA。
1.介绍
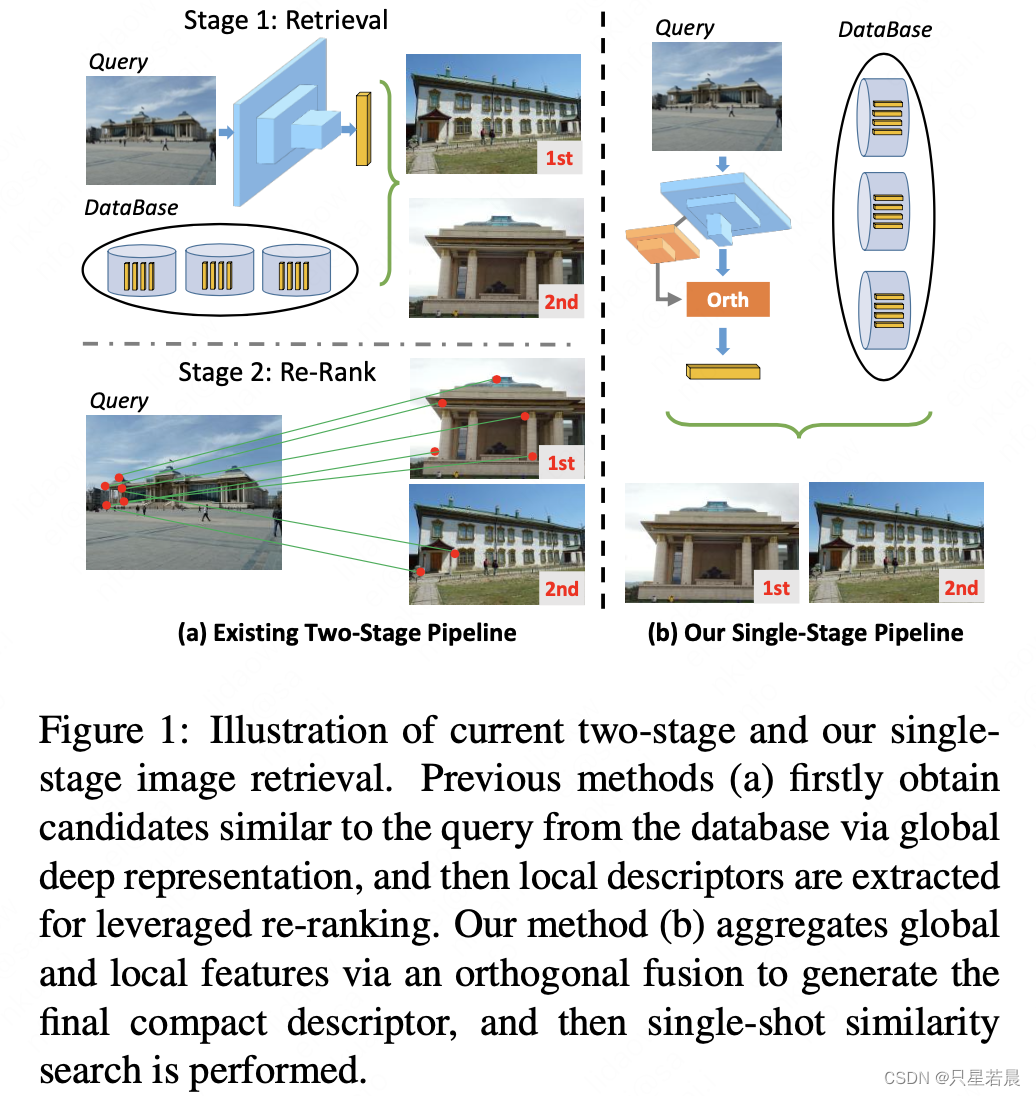
图像检索是计算机视觉领域的一项重要工作。主要目的是在海量数据集中查找与目标图像相似的图像。通过手工设计的特征,这一任务已经进行了广泛的研究。随着深度学习技术的发展,这一领域取得了重大进展。用于编码图像的图像描述子在图像检索领域中发挥着至关重要的作用。在众多基于学习的方法中,有两种类型的特征表征方法得到了广泛研究:全局特征和局部特征。全局特征用作高级语义图像标识;局部特征用于详细描述图像的不同区域。通常,全局特征对观察视角和环境光具有一致性,局部特征则对局部几何和纹理更敏感。因此,之前的SOTA工作通常采用两阶段范式。如图1(a),通过全局特征检索候选图像,保证高召回;然后通过对候选图像进行排序,来进一步提高准确率。
本文仍致力于通过深度网络解决图像检索问题。虽然之前的SOTA工作通过两阶段方法实现了高性能图像检索,但是它们需要对图像进行两次排序。并且,第二次排序需要使用高代价的RANSAC或者AMSK,借助局部特征进行空间验证。更重要的是,这两阶段中存在不可避免的错误。两阶段法会因为错误累计而导致性能瓶颈。为了减轻这个问题,我们放弃了两阶段框架,并试图找到一种单阶段的图像检索方法,如图1(b)。之前的研究表明全局特征和局部特征在图像检索领域是两个互补的重要元素。直观感觉,把全局特征和局部特征整合成紧凑型的图像描述子,可以实现我们的目标。合适的全局和局部融合模块可以利用这两种类型的特征,自动地相互促进,实现单阶段图像检索。此外,也可以避免错误累计。因此,我们设计并实现了端到端单阶段图像检索。
具体来说,提出DOLG。它包含全局特征学习分支、局部特征学习分支和正交融合模块来融合两种特征。详细来说,从局部特征中解析与全局特征正交的分量,然后该分量与全局特征串联,作为互补模块。最后,它被聚合成一个紧凑的描述符。通过正交融合,重要的局部信息得以保留,冗余的信息可以丢弃,进而局部和全局信息能够自动地互补增强,产生最终的特征描述子。为了增强局部特征学习,受之前研究的启发, 局部特征分支采用空洞卷机和自注意力机制。像FP-Net,采用正交空间学习,但是DOLG的目标在于正交空间的互补学习。Revisited Oxford and Pairs数据集上的实验表明了我们工作的有效性。DOLG实现了SOTA。主要的贡献点如下:
- 我们提出了单阶段的图像检索框架,新颖的全局和局部特征正交融合方法,产生了紧凑的图像特征描述子,实现端到端学习。
- 带有空洞卷机和自注意力机制的局部特征学习分支
- 模型SOTA
2.相关工作
2.1局部特征
在深度学习之前,SIFT特征和SURF特征是比较著名的人工设计的特征。通常这些特征会和KD trees、vocabulary trees等方法用作最近邻搜索。RANSAC等排序方法可以进一步提高搜索的准确性。基于深度学习的DELF等方法通过网络学习图像特征描述子。DELF没有考虑多尺度等问题。
2.2全局特征
传统的全局特征提取方法:BoW、Fisher vectors、VLAD、ASMK+Hamming Embedding;深度学习领域,全局特征提取方法包括:sum-pooling、 GeM pooling,训练过程中采用的损失函数:ranking based triplet, quadruplet, angular、listwise losses 或者 classification based losses。深度学习的方法在图像检索任务上性能更优。本文采用ArcFace loss,通过对局部特征和全局特征的正交融合,模型生成紧凑的特征描述子。
2.3局部与全局联合的CNN特征
同时考虑局部特征和全局特征是很自然的,因为来自图像表征模型的特征可以解释为局部视觉语义。DELG采用端到端的方式融合局部特征和全局特征,但是DELG采用两阶段方法。我们的工作采用正交融合的方式使用局部特征和全局特征,实现端到端单阶段图像检索。
3.方法
3.1概括
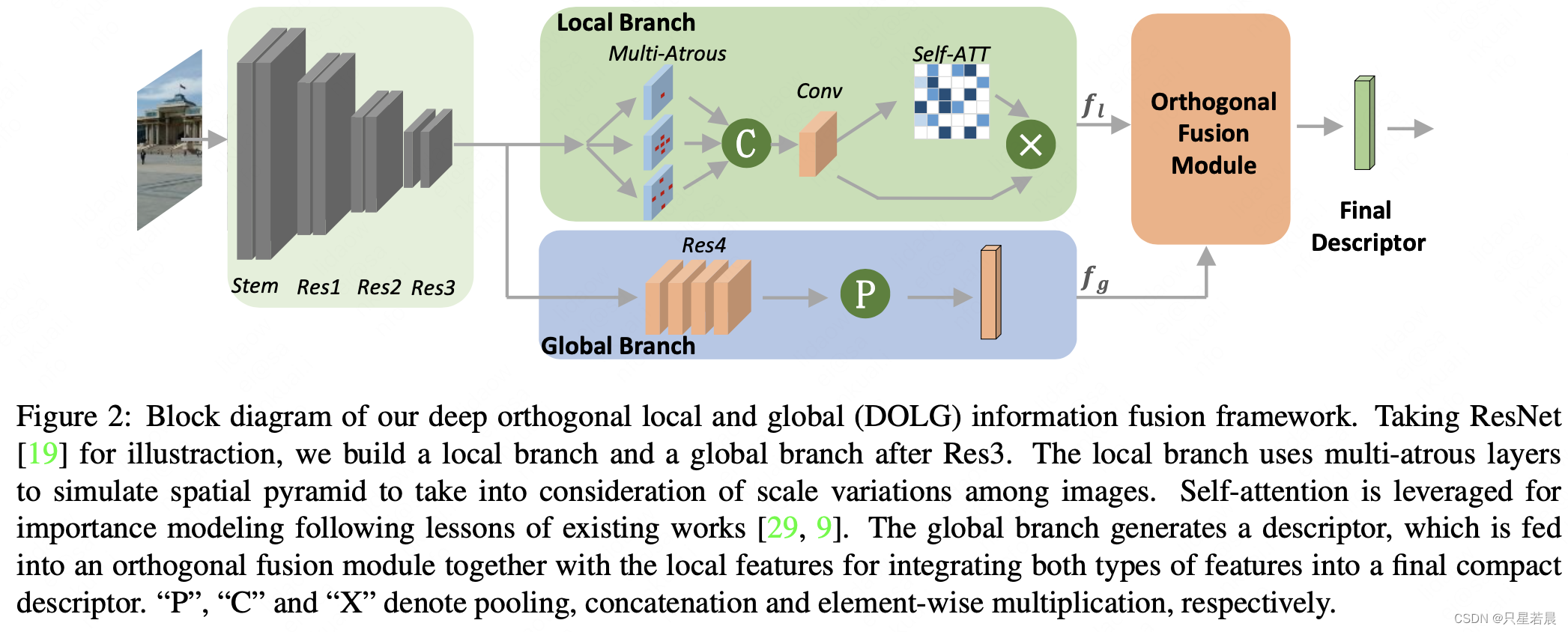
DOLG框架如图2。Backbone采用Resnet。全局模块保留resnet的基本结构,但是(1)采用GeM pooling作为全局池化;(2)全卷积层用于减少输出特征的维度,输出层特征为
f
g
∈
R
C
×
1
f_g\in R^{C\times1}
fg∈RC×1。记Res4的输出为
f
4
∈
R
C
4
×
h
×
w
f_4\in R^{C_4\times h \times w}
f4∈RC4×h×w ,那么GeM pooling可以表示为:
f g , c = ( 1 h w ∑ i , j f 4 , ( c , i , j ) p ) c = 1 , 2 , . . . , C 4 1 / p f_{g,c}=(\frac{1}{hw} \sum _{i,j}f_{4,(c,i,j)}^p)^{1/p}_{c=1,2,...,C_4} fg,c=(hw1∑i,jf4,(c,i,j)p)c=1,2,...,C41/p
解释:对Res4输出的特征,在每个通道上求特征值。方式是,对于第 c c c个通道,其特征的维度为 h × w h \times w h×w,对该特征的每个特征值的 p p p次方求和,然后再求平均,再计算平均值的 1 / p 1/p 1/p次方恢复到原量级,用求得的这1个值作为第 c c c个通道的特征值。因此Res4输出的特征 f 4 ∈ R C 4 × h × w f_4\in R^{C_4\times h \times w} f4∈RC4×h×w经过GeM pooling后变成 f 4 _ p o o l ∈ R C 4 × 1 f_{4\_pool} \in R^{C_4\times 1 } f4_pool∈RC4×1,再经过全卷积,得到最终全局分支的输出 f g ∈ R C × 1 f_g\in R^{C\times1} fg∈RC×1。
这里作者采用DELG中的思路, p p p取3.0。为了提取局部特征,把Rest3提取的特征作为局部分支的输入。局部分支包括了空洞卷机和自注意力机制,输出特征为 f l ∈ R C × H × W f_l \in R^{C \times H \times W } fl∈RC×H×W。正交融合模块用于整合 f g f_g fg和 f l f_l fl。正交融合后,生成最后的图像描述子。
3.2局部分支
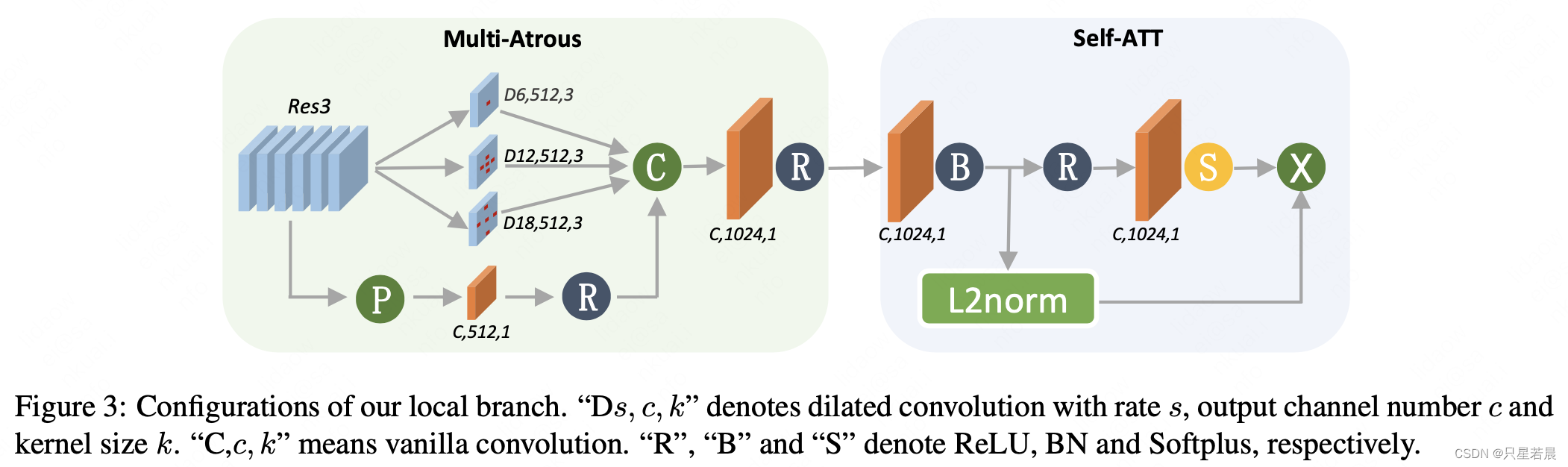
局部分支只要包括两个重要模块:空洞卷机和自注意力机制。空洞卷积用于提取特征金字塔,适应多尺度实例;自注意力机制主要用于聚焦重要实例建模。框架如图3所示。空洞卷积模块包含3种不同尺度的卷积,代表不同尺度的感受野,并施加全局池化。所有得到的特征串联后通过 1 × 1 1 \times 1 1×1的卷积进行融合降维。降维后的特征输入自注意力模块,该特征首先经过 1 × 1 1 \times 1 1×1的卷积+BN层,输出特征则分两路,一路用于L2norm,作为激活特征,另一路特征再次通过 1 × 1 1 \times 1 1×1卷积,并通过Softplus产生1通道的注意力图谱,最后激活特征和注意力图谱按元素相乘,作为局部分支的输出。
3.3正交融合模块
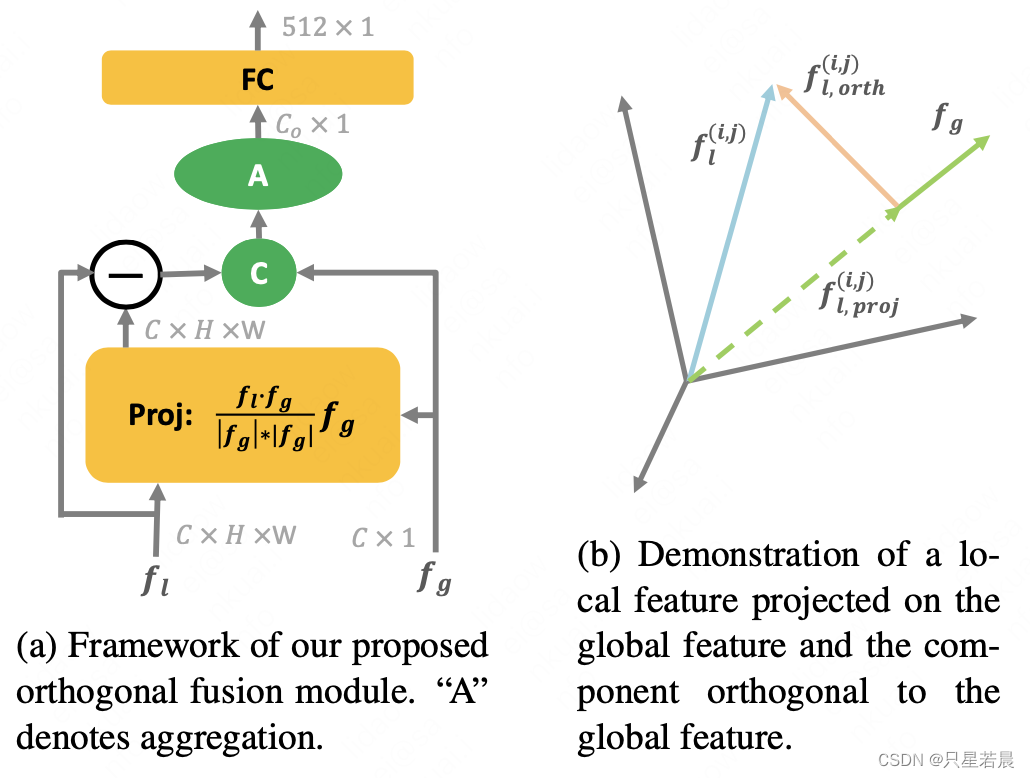
正交融合模块如图4。首先计算局部特征
f
l
f_l
fl每个特征点到全局特征
f
g
f_g
fg的投影
f
l
,
p
r
o
j
f_{l,proj}
fl,proj,计算方式如下:
f l , p r o j = f l ⋅ f g ∣ f g ∣ 2 f g f_{l,proj}=\frac{f_l \cdot f_g}{|f_g|^2}f_g fl,proj=∣fg∣2fl⋅fgfg,此处省略特征点位置标识 ( i , j ) (i,j) (i,j)
f l ⋅ f g f_l \cdot f_g fl⋅fg表示矩阵乘法, ∣ f g ∣ 2 |f_g|^2 ∣fg∣2表示L2范数。
解释:设向量 f l f_l fl与 f g f_g fg的夹角为 θ \theta θ,这个公式就是求图4b中的向量 f l , p r o j f_{l,proj} fl,proj,该向量可以表示为
f l , p r o j = ∣ f l , p r o j ∣ ∣ f g ∣ f g = ∣ f l ∣ c o s θ ∣ f g ∣ f g f_{l,proj}=\frac{|f_{l,proj}|}{|f_g|}f_g=\frac{|f_l|cos\theta}{|f_g|}f_g fl,proj=∣fg∣∣fl,proj∣fg=∣fg∣∣fl∣cosθfg
已知两个向量夹角的余弦值为
c o s θ = f l ⋅ f g ∣ f l ∣ ∣ f g ∣ cos\theta =\frac{f_l \cdot f_g}{|f_l||f_g|} cosθ=∣fl∣∣fg∣fl⋅fg
带入上式,可得:
f l , p r o j = f l ⋅ f g ∣ f g ∣ 2 f g f_{l,proj}=\frac{f_l \cdot f_g}{|f_g|^2}f_g fl,proj=∣fg∣2fl⋅fgfg。
其中,
f l ⋅ f g = ∑ c = 1 C f l , c f g , c f_l \cdot f_g=\sum_{c=1}^Cf_{l,c}f_{g,c} fl⋅fg=∑c=1Cfl,cfg,c
∣ f g ∣ 2 = ∑ c = 1 C ( f g , c ) 2 |f_g|^2=\sum_{c=1}^C(f_{g,c})^2 ∣fg∣2=∑c=1C(fg,c)2
正交组件定义为局部特征 f l f_l fl与投影 f l , p r o j f_{l,proj} fl,proj的差值,即正交向量 f l , o r t h f_{l,orth} fl,orth,作为前置特征描述子。经过pooling后与全局描述子串联,并通过全连接层映射为固定维度( 512 × 1 512\times 1 512×1)的特征描述子。
结合代码看一下正交融合模块的计算方法,以pytorch实现为例。forward函数和部分解释如下:
def forward(self, x, targets):
""" Global and local orthogonal fusion """
f3, f4 = self.globalmodel(x)
fl, _ = self.localmodel(f3) #局部分支输出特征fl
fg_o = self.pool_g(f4)
fg_o = fg_o.view(fg_o.size(0), cfg.MODEL.S4_DIM)
fg = self.fc_t(fg_o) #全局分支输出特征fg
fg_norm = torch.norm(fg, p=2, dim=1) #L2范数,用于后续作为分母,每个batch求1个范数值,fg_norm的维度为(B,)
proj = torch.bmm(fg.unsqueeze(1), torch.flatten(fl, start_dim=2))
proj = torch.bmm(fg.unsqueeze(2), proj).view(fl.size())
proj = proj / (fg_norm * fg_norm).view(-1, 1, 1, 1) # (fg_norm * fg_norm).view(-1, 1, 1, 1)结果维度为(B,1,1,1)
orth_comp = fl - proj
fo = self.pool_l(orth_comp)
fo = fo.view(fo.size(0), cfg.MODEL.S3_DIM)
final_feat=torch.cat((fg, fo), 1)
global_feature = self.fc(final_feat)
global_logits = self.desc_cls(global_feature, targets)
return global_feature, global_logits
其中,
proj = torch.bmm(fg.unsqueeze(1), torch.flatten(fl, start_dim=2))
对应 f g ⋅ f l f_g\cdot f_l fg⋅fl,矩阵乘法,fg的维度为 ( B , C ) (B,C) (B,C),fl的维度为 ( B , C , H , W ) (B,C,H,W) (B,C,H,W)。fg.unsqueeze(1)给fg添加1个维度变为3维 ( B , 1 , C ) (B,1,C) (B,1,C),torch.flatten(fl, start_dim=2)把fl在第2、3维度展开,变成 ( B , C , H × W ) (B,C,H\times W) (B,C,H×W)。矩阵相乘得到proj,维度 ( B , 1 , H × W ) (B,1,H \times W) (B,1,H×W) 。
proj = torch.bmm(fg.unsqueeze(2), proj).view(fl.size())
proj = proj / (fg_norm * fg_norm).view(-1, 1, 1, 1)
再使用fg和proj进行矩阵相乘,得到新的proj,proj除以前述得到的范数(每个batch除以自己的范数),得到 f l , p r o j f_{l,proj} fl,proj。注意这里view(-1, 1, 1, 1)只对(fg_norm * fg_norm)起作用。
后续即pooling、cat、fc操作。
3.4训练目标
参照DELG,训练过程网络只有一个 L 2 − n o r m a l i z e d L_2-normalized L2−normalized N类别预测头, W ^ ∈ R 512 × N \hat W \in R^{512 \times N} W^∈R512×N。ArcFace margion loss:
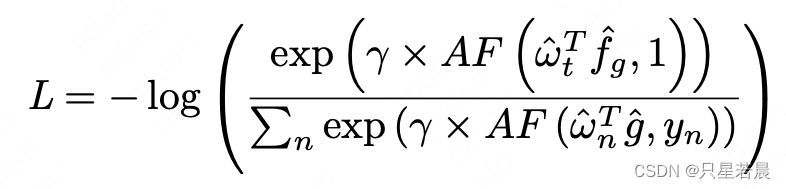
其中,
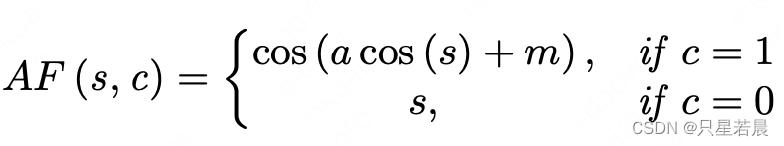
4.实验
略
5.参考
[1] Yang M , He D , Fan M , et al. DOLG: Single-Stage Image Retrieval with Deep Orthogonal Fusion of Local and Global Features[J]. 2021.

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









