






自定义管理者改变列表
既然Question管理页面看起来不错了,让我们来修改一下change list页面,该页面是展示系统中所有question模型的页面。
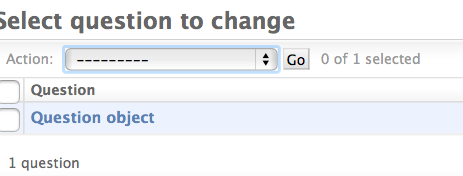
默认,Django会展示每个对象的str()这个方法所返回的值,但有时候如果我们能够展示单独的字段会更有帮助。为了实现那个,使用list_display这个管理者选项,它是一个包含字段名的元组,里面的字段名会展示在change list页面上的列。
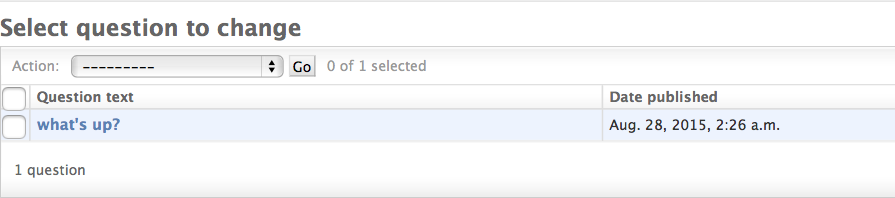
让我们来包含was_published_recently这个自定义方法:
list_display=('question_text','pub_date','was_published_recently')该方法定义为:
from django.db import models
import time
import datetime
from django.utils import timezone
class Question(models.Model):
question_text=models.CharField(max_length=200)
pub_date=models.DateTimeField('date published')
def was_published_recently(self):
return self.pub_date >= timezone.now()
class Choice(models.Model):
question=models.ForeignKey(Question)
choice_text=models.CharField(max_length=200)
votes=models.IntegerField(default=0)
现在问题change list页面是这样的:

现在,你可点击列的头部来通过列值来排序,除了was_published_recently这个头部,因为通过一个专制的函数返回值来排序还不支持。但是,你可以通过给那个方法一些属性来改变它。
from django.db import models
import time
import datetime
from django.utils import timezone
class Question(models.Model):
question_text=models.CharField(max_length=200)
pub_date=models.DateTimeField('date published')
def was_published_recently(self):
return self.pub_date >= timezone.now() - datetime.timedelta(days=1)
was_published_recently.admin_order_field = 'pub_date'
was_published_recently.boolean = True
was_published_recently.short_description = 'Published recently?'
class Choice(models.Model):
question=models.ForeignKey(Question)
choice_text=models.CharField(max_length=200)
votes=models.IntegerField(default=0)注意:为was_published_recently这个方法定义属性一定要注意缩进,否则的话特别容易出错,代码的图片是这样:

再次编辑你的polls/admin.py文件,使用list_filter来提高Question这个change list页。在QuestionAdmin里添加下面这行:
class QuestionAdmin(admin.ModelAdmin):
fieldsets=[(None,{'fields':['question_text']}),('Date information',{'fields':['pub_date'],'classes':['collapse']})]
inlines=[ChoiceInline]
list_display=('question_text','pub_date','was_published_recently')
list_filter=['pub_date']这会添加一个Filter栏,会根据pub_date这个字段来过滤change list

所展示的过滤器的类型取决于你所要过滤的字段类型,因为pub_date的类型是DateTimeField,Django知道给适当的过滤器选项:"Any date","Today","Past 7 days","This month","this year"。
让我们来添加搜索功能:
search_fields=['question_text']这句代码会在change list的顶部添加一个搜索框。当有人输入搜索条目时,Django会搜索question_text这个字段。你可以使用尽可能多的字段,如果你想的话。
现在注意到change list能够给你自由的页面设置。默认是每页展示100个条目。Change list pagination,search boxes,filters,date-hierarchies和column-header-ordering都可以一起工作。
















 66
66

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









